Размещение файлов
Область данных диска, отведенную для хранения файлов, можно представить как линейную последовательность адресуемых блоков (секторов). Размещая файлы в этой области, ОС должна отвести для каждого файла необходимое количество блоков и сохранить информацию о том, в каких именно блоках размещен данный файл. Существуют два основных способа использования дискового пространства для размещения файлов.
· Непрерывное размещение характеризуется тем, что каждый файл занимает непрерывную последовательность блоков.
· Сегментированное размещение означает, что файлы могут размещаться «по кусочкам», т.е. один файл может занимать несколько несмежных сегментов разной длины. Оба способа размещения показаны на рис. 3‑1.
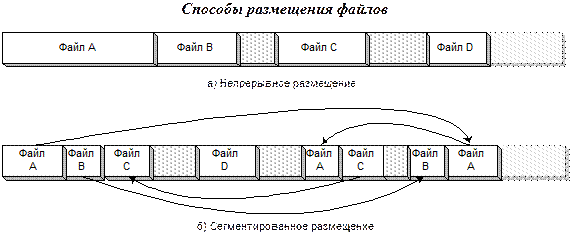
Рис. 3‑1
Непрерывное размещение имеет два серьезных достоинства.
· Информация о размещении файла очень проста и занимает мало места. Фактически достаточно хранить два числа: номер начального блока файла и число занимаемых блоков (или размер файла в байтах, по которому легко вычислить число блоков).
· Доступ к любой позиции в файле выполняется быстро, поскольку, зная смещение от начала файла, легко можно вычислить номер требуемого блока и прочитать сразу этот блок, не читая предыдущие блоки.
К сожалению, недостатки непрерывного распределения еще более весомы.
· При создании файла требуется заранее знать его размер, чтобы найти и зарезервировать на диске область достаточной величины. Последующее возможное увеличение файла весьма затруднено, т.к. после конца файла может не оказаться достаточно свободного места. Фактически вместо увеличения файла обычно приходится заново создавать файл большего размера в другом месте, переписывать в него данные и удалять старый файл. Но такое решение требует много времени на чтение и запись данных и, кроме того, снижает надежность хранения данных, поскольку ошибка при чтении или записи гораздо более вероятна, чем порча данных, «спокойно лежащих» на диске.
· В ходе обычной эксплуатации файловой системы, после многократного создания и удаления файлов разной длины, свободное пространство на диске оказывается разбитым на небольшие кусочки. Суммарный объем свободного места на диске может быть достаточно большим, но создать файл приличного размера не удается, для него нет непрерывной области нужной длины. Это явление носит название фрагментации диска. Для борьбы с ним приходится использовать специальную процедуру дефрагментации, которая перемещает все файлы, размещая их впритык друг к другу от начала области данных диска. Но такая процедура требует много времени, снижает, как сказано выше, надежность и усугубляет проблемы в случае, если позднее потребуется увеличить файл.
Сегментированное размещение лишено первого из недостатков непрерывного: при создании файла ему обычно вообще не выделяют память, а потом, по мере возрастания размера файла, ему могут быть выделены любые свободные сегменты на диске, независимо от их длины.
Не так просто с фрагментацией. Конечно, в отличие от непрерывного размещения, при сегментированном никакая фрагментация не помешает системе использовать все блоки, имеющиеся на диске. Однако последовательное чтение из сегментированного файла может выполняться существенно медленнее за счет необходимости переходить от сегмента к сегменту. Замедление особенно заметно, если файл оказался разбросан маленькими кусочками по нескольким цилиндрам диска. В результате, время от времени целесообразно выполнять дефрагментацию диска, чтобы повысить скорость доступа к данным. При сегментированном размещении дефрагментация означает не только объединение всех свободных участков диска, но и, главным образом, объединение сегментов каждого файла. Эта процедура выполняется значительно сложнее, чем дефрагментация при непрерывном размещении.
Можете ли вы предложить хороший алгоритм дефрагментации? Учтите, что он должен эффективно работать, даже если на диске осталось всего несколько свободных блоков.
Недостатком сегментированного размещения является то, что информация о размещении файла в этом случае намного сложнее, чем для непрерывного случая и, что наиболее неприятно, объем этой информации переменный: чем большее число сегментов занимает файл, тем больше нужно информации, ибо надо перечислить все сегменты. Имеется почти столько же способов решения этой проблемы, сколько вообще придумано разных файловых систем.
Чтобы уменьшить влияние сегментации на скорость доступа к данным файла, в ОС, использующих сегментированное размещение, применяются различные алгоритмы выбора места для файла. Их целью является разместить файл по возможности в одном сегменте, и только в крайнем случае разбивать файл на несколько сегментов.
В современных ОС для файловых систем на магнитных дисках практически всегда используют сегментированное размещение. Иное дело файловые системы на дисках, предназначенных только для чтения (например, CD ROM). Нетрудно понять, что в этом случае недостатки непрерывного размещения не имеют никакого значения, а его достоинства сохраняются.
Еще одной важной характеристикой размещения файлов является степень его «дробности». До сих пор мы предполагали, что файл может занимать любое целое число блоков, а под блоком фактически понимали сектор диска. Проблема в том, что для дисков большого объема число блоков может быть слишком большим. Допустим, в некоторой файловой системе размер блока равен 512 байт, а для хранения номеров блоков файла используются 16-разрядные числа. В этом случае размер области данных диска не сможет превысить 512 * 216 = 32 Мб, что нынче смешно. Конечно, можно перейти к использованию 32-разрядных номеров блоков, но тогда суммарный размер информации о размещении всех файлов на диске становится чересчур большим. Обычный выход из этого затруднения заключается в том, что минимальной единицей размещения файлов считают кластер (называемый в некоторых системах блоком или логическим блоком), который принимается равным 2k секторов, т.е., например, 1, 2, 4, 8, 16, 32 сектора, редко больше. Каждому файлу отводится целое число кластеров, и в информации о размещении файла хранятся номера кластеров, а не секторов. Увеличение размера кластеров позволяет сократить количество данных о размещении файлов «и в длину и в ширину»: во-первых, для каждого файла нужно хранить информацию о меньшем числе кластеров, а во-вторых, уменьшается число двоичных разрядов, используемых для задания номера кластера (либо при той же разрядности можно использовать больший диск). Так, при кластере размером 32 сектора и 16-разрядных номерах можно адресовать до 1 Гб дисковой памяти.
Использование больших кластеров имеет свою плохую сторону. Поскольку размер файла можно считать случайной величиной (по крайней мере, этот размер никак не связан с размером кластера), то можно приближенно считать, что в среднем половина последнего кластера каждого файла остается незанятой. Это явление иногда называют внутренней фрагментацией (в отличие от описанной выше фрагментации свободного пространства диска, которую называют также внешней фрагментацией). Кроме того, если хотя бы один из секторов, входящих в кластер, отмечен как дефектный, то и весь кластер считается дефектным, т.е. не может быть использован. Очевидно, что при увеличении размера кластера возрастает и число неиспользуемых секторов диска.
Оптимальный размер кластера либо вычисляется автоматически при форматировании диска, либо задается вручную.
Для нормальной работы файловой системы требуется, чтобы, кроме информации о размещении файлов, система хранила в удобном для использования виде информацию об имеющихся свободных кластерах диска. Эта информация необходима при создании новых или увеличении существующих файлов. Используются различные способы представления информации о свободном месте, некоторые из них перечислены ниже.
· Можно хранить все свободные кластеры как связанный линейный список, т.е. в начале каждого свободного кластера хранить номер следующего по списку. Недостаток такого способа в том, что затрудняется поиск свободного непрерывного фрагмента нужного размера, поэтому сложнее оптимизировать размещение файлов.
· Названный недостаток можно преодолеть, если хранить список не из отдельных кластеров, а из непрерывных свободных фрагментов диска. Правда, работать с таким списком несколько сложнее.
· В системах с непрерывным размещением часто каждый непрерывный фрагмент диска описывают так же, как файл, но отмечают его флажком «свободен».
· Удобный и простой способ заключается в использовании битовой карты (bitmap) свободных кластеров. Она представляет собой массив, содержащий по одному биту на каждый кластер, причем значение 1 означает «кластер занят», а 0 – «кластер свободен». Для поиска свободного непрерывного фрагмента нужного размера система должна будет просмотреть весь массив.
Дата добавления: 2015-09-07; просмотров: 926;