Структура и компоненты простой программы
Текст программы и препроцессор.Каждая программа на языке Си есть последовательность препроцессорных директив, описаний и определений глобальных объектов и функций. Препроцессорные директивы управляют преобразованием текста программы до ее компиляции. Определения вводят функции и объекты. Объекты необходимы для представления в программе обрабатываемых данных. Функции определяют потенциально возможные действия программы. Описания уведомляют компилятор о свойствах и именах тех объектов и функций, которые определены в других частях программы (например, ниже по ее тексту или в другом файле).
Программа на языке Си должна быть оформлена в виде одного или нескольких текстовых файлов. Текстовый файл разбит на строки. В конце каждой строки есть признак ее окончания (плюс управляющий символ перехода к началу новой строки). Просматривая текстовый файл на экране дисплея, мы видим последовательность строк, причем признаки окончания строк невидимы, но по ним производится разбивка текста редактором.
Определения и описания программы на языке Си могут размещаться в строках текстового файла достаточно произвольно (в свободном формате.) Для препроцессорных директив существуют ограничения. Во-первых, препроцессорная директива обычно размещается в одной строке, т.е. признаком ее окончания является признак конца строки текста программы. Во-вторых, символ '#', вводящий каждую директиву препроцессора, должен быть первым отличным от пробела символом в строке с препроцессорной директивой.
Исходная программа, подготовленная на языке Си в виде текстового файла, проходит три обязательных этапа обработки:
• препроцессорное преобразование текста;
• компиляция;
• компоновка (редактирование связей или сборка).
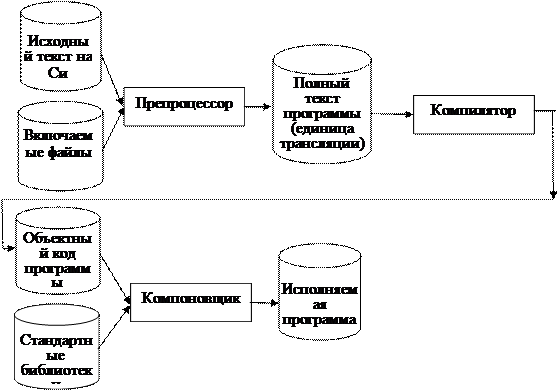 |
Только после успешного завершения всех перечисленных этапов формируется исполняемый машинный код программы.
Задача препроцессора - преобразование текста программы до ее компиляции. Правила препроцессорной обработки определяет программист с помощью директив препроцессора. Каждая препроцессорная директива начинается с символа '#'. Пока нам будет достаточно двух директив: #includeи #define.
Препроцессор "сканирует" исходный текст программы в поиске строк, начинающихся с символа '#'. Такие строки воспринимаются препроцессором как команды (директивы), которые определяют действия по преобразованию текста. #defineуказывает правила замены в тексте. Директива #includeопределяет, какие текстовые файлы нужно включить в этом месте текста программы.
Директива #include <...> предназначена для включения в текст программы текста файла из каталога "заголовочных файлов", поставляемых вместе со стандартными библиотеками компилятора. Каждая библиотечная функция, определенная стандартом языка Си, имеет соответствующее описание (прототип библиотечной функции плюс определения типов, переменных, макроопределений и констант) в одном из заголовочных файлов. Список заголовочных файлов для стандартных библиотек определен стандартом языка.
Важно понимать, что употребление в программе препроцессорной директивы
#include< имя_заголовочного_файла >
не подключает к программе соответствующую стандартную библиотеку. Препроцессорная обработка выполняется на уровне исходного текста программы. Директива #includeтолько позволяет вставить в текст программы описания из указанного заголовочного файла. Подключение к программе кодов библиотечных функций осуществляется только на этапе редактирования связей (этап компоновки), т.е. после компиляции, когда уже получен машинный код программы. Доступ к кодам библиотечных функций нужен только на этапе компоновки. Именно поэтому компилировать программу и устранять синтаксические ошибки в ее тексте можно без стандартной библиотеки, но обязательно с заголовочными файлами.
Здесь следует отметить еще одну важную особенность. Хотя в заголовочных файлах содержатся описания всех стандартных функций, в код программы включаются только те функции, которые используются в программе. Выбор нужных функций выполняет компоновщик на этапе, называемом "редактирование связей".
Термин "заголовочный файл" {header file} в применении к файлам, содержащим описания библиотечных функций стандартных библиотек, не случаен. Он предполагает включение этих файлов именно в начало программы. Мы настоятельно рекомендуем, чтобы до обращения к любой функции она была определена или описана в том же файле, где помещен текст программы. Описание или определения функций должны быть "выше" по тексту, чем вызовы функций. Именно поэтому заголовочные файлы нужно помещать в начале текста программы, т.е. заведомо раньше обращений к соответствующим библиотечным функциям.
Хотя заголовочный файл может быть включен в программу не в ее начале, а непосредственно перед обращением к нужной библиотечной функции, такое размещение директив #include<...> не рекомендуется.
Структура программы.После выполнения препроцессорной обработки в тексте программы не остается ни одной препроцессорной директивы. Теперь программа представляет собой набор описаний и определений. Если не рассматривать определений глобальных объектов и описаний, то программа будет набором определений функций.
Среди этих функций всегда должна присутствовать функция с фиксированным именем main. Именно эта функция является главной функцией программы, без которой программа не может быть выполнена. Имя этой главной функции для всех программ одинаково (всегда main) и не может выбираться произвольно. Таким образом, исходный текст программы в простом случае (когда программа состоит только из одной функции) имеет такой вид:
директивы препроцессора
void main()
{
определения объектов;
исполняемые_операторы; }
Две директивы препроцессора #define и #include мы уже ввели. Директивы препроцессора могут размещаться не только в начале программы. Они при необходимости могут быть помещены в любом месте текста программы. Однако заголовочные файлы, с которыми всегда приходится иметь дело, рекомендуется помещать в начале текста программы. Именно эта особенность отмечена в предложенном формате программы. Теперь можно писать несложные программы на языке Си.
Перед именем каждой функции программы следует помещать сведения о типе возвращаемого функцией значения (тип результата). Если функция ничего не возвращает, то указывается тип void. Функция main() является той функцией программы, которая запускается на исполнение по командам операционной системы. Возвращаемое функцией main() значение также передается операционный системе. Если программист не предполагает, что операционная система будет анализировать результат выполнения его программы, то проще всего указать, что возвращаемое значение отсутствует, т.е. имеет тип void.Если сведения о типе результата отсутствуют, то считается по умолчанию, что функция mainвозвращает целочисленное значение типа int.
Каждая функция (в том числе и main)в языке Си должна иметь набор параметров. Этот набор может быть пустым, тогда в скобках после имени функции помещается служебное слово void либо скобки остаются пустыми. В отличие от обычных функций главная функция main() может использоваться как с параметрами, так и без них.
Вслед за заголовком void main( ) размещается тело функции. Тело функции - это блок, последовательность определений, описаний и исполняемых операторов, заключенная в фигурные скобки. Определения и описания в блоке будем размещать до исполняемых операторов. Каждое определение, описание и каждый оператор завершается символом ';' (точка с запятой).
Определения вводят объекты, необходимые для представления в программе обрабатываемых данных. Примером таких объектов служат именованные константы и переменные разных типов. Описания уведомляют компилятор о свойствах и именах объектов и функций, определенных в других частях программы. Операторы определяют действия программы на каждом шаге ее выполнения.
Чтобы привести пример простейшей осмысленной программы на языке Си, необходимо ввести оператор, обеспечивающий вывод данных из ЭВМ, например на экран дисплея. К сожалению (или как особенность языка), такого оператора в языке Си НЕТ! Все возможности обмена данными с внешним миром программа на языке Си реализует с помощью библиотечных функций ввода-вывода.
Для подключения к программе описаний средств ввода-вывода из стандартной библиотеки компилятора используется директива #include <stdio.h>.
Название заголовочного файла stdio.hявляется аббревиатурой: std - standard (стандартный), / - input (ввод), о ~ output (вывод), h - head (заголовок).
Функция форматированного вывода.Достаточно часто для вывода информации из ЭВМ в программах используется функция printf(). Она переводит данные из внутреннего кода в символьное представление и выводит полученные изображения символов результатов на экран дисплея. При этом у программиста имеется возможность форматировать данные, т.е. влиять на их представление на экране дисплея.
Возможность форматирования условно отмечена в самом имени функции с помощью литеры fв конце ее названия (print formatted).
Оператор вызова функции printf() можно представить так:
printf(форматная строка, список _аргументов);
Форматная строка ограничена двойными кавычками и может включать произвольный текст, управляющие символы и спецификации преобразования данных. Список аргументов (с предшествующей запятой) может отсутствовать. Например:
#include <stdio.h> void main( )
{ printf ("\n Здравствуй, Мир!\n");
}
Директива #include <stdio.h>включает в текст программы описание (прототип) библиотечной функции printf(). (Если удалить из текста программы эту препроцессорную директиву, то появятся сообщения об ошибках и исполнимый код программы не будет создан. Среди параметров функции printf() есть в этом примере только форматная строка (список аргументов отсутствует). В форматной строке два управляющих символа '\n' - "перевод строки". Между ними текст, который выводится на экран дисплея:
Здравствуй, Мир!
Первый символ '\n' обеспечивает вывод этой фразы с начала новой строки. Второй управляющий символ '\n' переведет курсор к началу следующей строки, где и начнется вывод других сообщений (не связанных с программой) на экран дисплея.
Итак, произвольный текст (не спецификации преобразования и не управляющие символы) непосредственно без изменений выводится на экран. Управляющие символы (перевод строки, табуляция и т.д.) позволяют влиять на размещение выводимой информации на экране дисплея.
Спецификации преобразования данных предназначены для управления формой внешнего представления значений аргументов функции printf(). Обобщенный формат спецификации преобразования имеет вид:
%фпажки ширина _поля.точность модификатор спецификатор
Среди элементов спецификации преобразования обязательными являются только два — символ '% ' и спецификатор.
В задачах вычислительного характера будем использовать спецификаторы:
d - для целых десятичных чисел (тип int);
u -для целых десятичных чисел без знака (тип unsigned);
f- для вещественных чисел в форме с фиксированной точкой (типы float и double);
е - для вещественных чисел в форме с плавающей точкой (с мантиссой и порядком) - для типов double и float.
В список аргументов функции printf() включают объекты, значения которых должны быть выведены из программы. Это выражения и их частные случаи - переменные и константы. Количество аргументов и их типы должны соответствовать последовательности спецификаций преобразования в форматной строке. Например, если вещественная переменная summa имеет значение 2102.3, то при таком вызове функции
printf("\n summa=%f", summa);
на экран с новой строки будет выведено: summa=2102.3
После выполнения операторов
float с, е ;
int к;
с=48.3; к=-83; e=16.33;
printf ("\nc=%f\tk=%d\te=%e", с, к, e);
на экране получится такая строка:
с=48.299999 к=-83 e=1.63300e+01
Здесь обратите внимание на управляющий символ \t (табуляция). С его помощью выводимые значения в строке результата отделены друг от друга.
Для вывода числовых значений в спецификации преобразования весьма полезны "ширина поля" и "точность".
Ширина_поля - целое положительное число, определяющее длину (в позициях на экране) представления выводимого значения.
Точность - целое положительное число, определяющее количество цифр в дробной части внешнего представления вещественного числа (с фиксированной точкой) или его мантиссы (при использовании формы с плавающей точкой).
Пример с теми же переменными:
printf ("\nc=%5.2\tk=%5d\te=%8.2f\te=%11.4e", c, k , e, e) ;
Результат на экране:
с=48.30 к= -83 e= 16.33 e= 1.6330e+01
В качестве модификаторов в спецификации преобразования используются символы:
h - для вывода значений типа short int;
I - для вывода значений типа long;
L - для вывода значений типа long double.
Применимость вещественных данных.Даже познакомившись с различиями в диапазонах представления вещественных чисел, начинающий программист не сразу осознает различия между типами float, doubleи long double.Сразу бросается в глаза разное количество байтов, отводимых в памяти для вещественных данных перечисленных типов. На IBM PC:
• для float- 4 байта;
• для double- 8 байт;
• для long double- 10 байт.
По умолчанию все константы, не относящиеся к целым типам, принимают тип double. У программиста это соглашение часто вызывает недоумение - а не лучше ли всегда работать с вещественными данными типа float и только при необходимости переходить к double или long double? Ведь значения больше 1Е+38 и меньше 1Е-38 встречаются довольно редко.
Следующая программа (предложена С.М.Лавреновым) иллюстрирует опасности, связанные с применением данных типа float даже в несложных арифметических выражениях:
#include <stdio.h>
void main ( )
{
float a, b, c, tl, t2, t3;
a=95.0;
b=0.02;
tl=(a+b)*(a+b);
t2=-2.0*a*b-a*a;
t3=b*b;
c=(tl+t2)/t3;
printf("\nc=%f\n", c) ; }
Результат выполнения программы: c=2.441406
Если в той же программе переменной а присвоить значение 100.0, то результат будет еще хуже:
с=0.000000.
Таким образом, запрограммированное с использованием переменных типа floatнесложное алгебраическое выражение
(a+b)2-(a2+2ab)/b2
никак "не хочет" вычисляться и принимать свое явное теоретическое единичное значение.
Если заменить в программе только одну строку, т.е. так определить переменные:
double а, b, с, tl, t2, t3; значение выражения вычисляется совершенно точно: с=1.000000
Приведенный пример и общие положения вычислительной математики заставляют существенно ограничить применение переменных типа float.Тип floatможно выбирать для представления исходных данных или окончательных результатов, получаемых в программе. Однако применение данных типа floatв промежуточных вычислениях (особенно в итерационных алгоритмах) следует ограничить и всегда использовать doubleлибо long double.
К сожалению, ни double,ни long doubleне снимают полностью проблем конечной точности представления вещественных чисел в памяти ЭВМ. Существенное различие в порядках значений операндов арифметических выражений может привести к подобным некорректным результатам и при использовании типов doubleи long double.
Выделение лексем из текста программы.В главе 1 мы ввели понятие лексемы, перечислили их группы (идентификаторы, знаки операций и т.д.) и определили состав каждой из групп лексем. Первая задача, которую решает компилятор, - это лексический анализ текста программы. В результате лексического анализа из сплошного текста выделяются лексические единицы (лексемы).
Компилятор просматривает символы (литеры) текста программы слева направо. При этом его первая задача - выделить лексемы языка. За очередную лексическую единицу принимается наибольшая последовательность литер, которая образует лексему. Таким образом, из последовательности intjine компилятор не станет выделять как лексему служебное слово int,a воспримет всю последовательность как введенный пользователем идентификатор.
В соответствии с тем же принципом выражение d+++b трактуется как d++ +b, а выражение b-->с эквивалентно (b--)>с.
Следующая программа иллюстрирует сказанное:
#include <stdio.h>
void main()
{ int n=10,m=2;
printf("\nn+++m=%d",n+++m)
printf("\nn=%d, m=%d",n,m)
printf("\nm-->n=%d",m-->n)
printf("\nn=%d, m=%d",n,m)
printf("\nn-->m=%d",n-->m)
printf("\nn=%d, m=%d",n,m) )
Результат выполнения программы:
n+++m=12
n=ll,m=2
m--n=0
n=ll,m=l
n-->m=l
n=10,m=l i
Результаты вычисления выражений n+++m, n-->m, m-->n полностью соответствуют правилам интерпретации выражений на основе таблицы рангов операций. Унарные операции ++ и -- имеют ранг 2. Аддитивные операции + и - имеют ранг 4. Операции отношений имеют ранг 6.
Дата добавления: 2015-10-09; просмотров: 1399;