Эффективное посимвольное кодирование для сжатия данных.
Основные моменты сводятся к следующему:
- идея такого кодирования базируется на том, чтобы использовать для часто встречающихся символов более короткие кодовые цепочки, а для редких - более длинные. В результате средняя длина кода 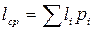 будет меньше, чем при равномерном кодировании;
будет меньше, чем при равномерном кодировании;
- согласно теореме Шеннона, наилучшее кодирование позволяет сократить lср. до величены энтропии Н, подсчитанной для данного набора символов;
- неравномерное кодирование позволяет автоматически устранить избыточность, связанную с тем, что количество символов в алфавите может быть не кратно степени двойки (так, например, чтобы закодировать одинаковым числом разрядов 5 разновидностей символов потребуется 3 бита, так же как и для 8 символов).
Идея неравномерного кодирования, в котором длина кодовой цепочки зависит от частоты появления соответствующего символа, реализована еще в знаменитой «азбуке Морзе». Однако там наряду с «точками» и «тире» использовался третий кодовый символ – разделитель «пауза». Если ограничиться только «O» и «1», то при построении кода необходимо учесть дополнительное требование: чтобы все кодовые цепочки однозначно выделялись в непрерывном потоке битов, ни одна из них не должна входить как начальный участок в кодовую, цепочку другого символа. Такое свойство кода называется префиксностью.
Наибольшее распространение получил способ построения эффективного кода предположенный Хаффменом. Рассмотрим его на примере. Пусть задан алфавит из 5 разновидностей символов Z1 – Z5, и их вероятности. В таблице 5.1 наряду с этими исходными данными приведены так же результаты кодирования по Хаффмену: кодовые цепочки Ki их длинны li. Процедуру построения кода иллюстрирует таблица и рисунок 1
На первом этапе символы упорядочивают по убыванию вероятностей, а затем выполняют несколько шагов «объединения», на каждом из которых суммируются вероятности наиболее редко встречающихся символов и столбец вероятностей пересортировывается .
Пример кода Хаффмена
| Zi | Pi | Ki | li |
| Z1 Z2 Z3 Z4 Z5 | 0,25 0,17 0,08 0,35 0,15 | ||
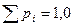
| lср |
На втором этапе строится «дерево кода», ветви которого отображают в обратном порядке процесс «объединения вероятностей». При построении дерева принимается правило соответствия большей вероятности одному из направлений ветви (например «левому») и определенному значению бита кода (например, «1») . Цепочки битов от «корня» до конца каждой ветви соответствуют кодам исходных символов (табл.5.1 – 5.2).
Таблица 2 Объединение вероятностей символов
| Zi | Pi | Шаги объединения | Ki | |||
| Z1 Z2 Z3 Z4 Z5 | 0,35 0,25 0,17 0,15 0,08 | 0,35 0,25 0,23 0,17 | 0,40 0,35 0,25 | 0,60 0,40 | 1,00 |
Процедура кодирования сводится к выбору из кодовой таблицы цепочек, соответствующих каждому символу источника. Декодирование предусматривает выделение в битовом потоке кодов символов и их расшифровку в соответствии с таблицей.
Код Хаффмена может быть двухпроходным и однопроходным. Первый строится по результатам подсчета частот (вероятностей) появления различных символов в данном сообщении. Второй использует готовую таблицу кодирования, построенную на основе вероятностей символов в сообщениях похожего типа. Например, кодирование текста на русском языке в первом случае включает его предварительный анализ, подсчет вероятностей символов, построение дерева кода и таблицы кодирования индивидуально для данного сообщения. Во втором случае будет работать готовая таблица, построенная по результатам анализа множества русскоязычных текстов. Двухпроходный код более полно использует возможности сжатия. Однако, при этом вместе с сообщением нужно передавать и кодовую таблицу. Однопроходный код не оптимален, однако прост в использовании, поэтому на практике обычно применяют именно его.
В целом код Хаффмена проигрывает по сравнению с «цепочечными» кодами и его редко используют самостоятельно, однако он часто фигурирует как элемент более сложных алгоритмов сжатия.
Дата добавления: 2015-09-18; просмотров: 1907;