Кодирование информации в ЭВМ
ФОРМАТЫ ДАННЫХ.
АРХИТЕКТУРА СИСТЕМЫ КОМАНД ЭВМ
Кодирование информации в ЭВМ
Каждому символу в ЭВМ (букве, цифре, знаку препинания, математическому знаку) ставится в соответствие определенная двоичная комбинация. Совокупность возможных символов и назначенных им двоичных кодов образует таблицу кодировки. В настоящее время применяется множество различных таблиц кодировки. Объединяет их весовой принцип, при котором веса кодов цифр возрастают по мере увеличения цифры, а веса символов увеличиваются в алфавитном порядке. Так вес буквы «Б» на единицу больше веса буквы «А». Это способствует упрощению обработки в ВМ.
До недавнего времени наиболее распространенными были кодовые таблицы, в которых символы кодируются с помощью восьмиразрядных двоичных комбинаций (байтов), позволяющих представить 256 различных символов:
· расширенный двоично-кодированный код ЕВСВIС (Ехtеnded Вinагу Decimal Interchange Code);
· американский стандартный код для обмена информацией АSСII (American Standard Code for Information Interchange).
Код ЕВСВIС используется в качестве внутреннего кода в универсальных ВМ фирмы IВМ. Он же известен под названием ДКОИ (двоичный код для обработки информации).
Стандартный код ASCII – 7-разрядный, восьмая позиция отводится для записи бита четности. Это обеспечивает представление 128 символов, включая все латинские буквы, цифры, знаки основных математических операций и знаки пунктуации. Позже появилась европейская модификация ASCII, называемая Latin 1 (стандарт ISO 8859-1). В ней «полезно» используются все 8 разрядов. Дополнительные комбинации (коды 128-255) в новом варианте отводятся для представления специфических букв алфавитов западно-европейских языков, символов псевдографики, некоторых букв греческого алфавита, а также ряда математических и финансовых символов. Именно эта кодовая таблица считается мировым стандартом де-факто, который применяется с различными модификациями во всех странах. В зависимости от использования кодов 128-255 различают несколько вариантов стандарта ISO 8859 ( от первого до шестнадцатого). Так, например, стандарт ISO 8859-2 характеризует языки стран центральной и восточной Европы.
В популярной в свое время операционной системе MS-DOS стандарт ISO 8859 реализован в форме кодовых страниц ОЕМ. Каждая ОЕМ-страница имеет свой идентификатор (CP 866 – Россия).
Хотя код АSCII достаточно удобен, он все же слишком тесен и не вмещает множества необходимых символов. По этой причине в 1993 году консорциумом нескольких компаний был разработан 16-битовый стандарт ISO 10646, определяющий универсальный набор символов UCS (Universal Character Set). Новый код, известный под названием Unicode, позволяет задать до 65536 символов, то есть дает возможность одновременно представить символы всех основных «живых» и «мертвых» языков. Для букв русского языка выделены коды 1040-1093.
В «естественном» варианте кодировки Unicode, известном как UCS-2, каждый символ описывается двумя последовательными байтами m и n, так что номеру символа соответствует численное значение 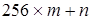 . Таким образом, кодовый номер представлен 16-разрядным двоичным числом.
. Таким образом, кодовый номер представлен 16-разрядным двоичным числом.
Дата добавления: 2015-07-18; просмотров: 961;