Локальные дескрипторные таблицы
Выше было показано, что процессор i486 поддерживает три типа дескрипторных таблиц: общесистемные таблицы GDT и IDT, a также таблицы LDT. Последние таблицы при необходимости создаются по одной для каждой задачи и служат расщирением таблицы GDT при реализации мультизадачных систем. Наличие таблицы LDT увеличивает адресное пространство задачи, которое недоступно для других задач. Если задача не имеет таблицы LDT,что вполне допустимо, все требующиеся ей дескрипторы берутся из таблицы GDT; при этом необходимо избегать загрузки в сегментные регистры селекторов с битом TI = 1. Таким образом, с помощью таблиц LDT можно разрешить доступ к критическим областям памяти, например видеобуферу или дисковому контроллеру, только отдельным задачам.
Базовая структура адресного пространства с таблицами GDT и LDT предполагает, что каждая задача имеет свою таблицу LDT и все задачи пользуются общей таблицей GDT. В результате сегмент доступен либо только одной задаче, либо всем задачам. Для небольших однопользовательских систем характерно отсутствие таблиц LDT. Наконец, группа взаимосвязанных задач (образующих задание) может использовать одну и ту же таблицу LDT. Все задачи в группе разделяют одно адресное пространство, но группа, как целое, обладает своими сегментами, изолированными от остальной части системы. Более сложные структуры разделения адресного пространства реализуются с помощью альтернативного именования сегментов.
Локальная дескрипторная таблица, так же как таблица GDT, представляет собой массив 8-байтных дескрипторов сегментов. В любой момент времени процессор работает только с одной таблицей LDT, а при переключении задачи изменяется и активная таблица LDT. Поэтому для локализации таблицы LDT вместо 48-битного регистра, аналогичного регистрам GDTR и IDTR, в процессоре i486 имеется 16-битный регистр LDTR, содержащий только селектор LDT. Этот селектор выбирает в таблице GDT специальный дескриптор, который описывает текущую таблицу LDT, т.е. определяет ее базовый адрес и предел. Таким образом, при обращении к сегменту данных, который определяется селектором с битом TI = 1, появляется дополнительный уровень косвенности. Отметим, что в таблице LDT не могут находиться дескрипторы LDT, т.е. процессор не допускает дальнейшего «вложения косвенности».
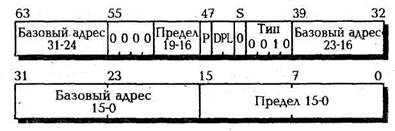
Дескриптор LDT, формат которого показан на рис.2.10, является первым примером системных дескрипторов сегментов с битом S = 0. Такие дескрипторы не имеют бита обращения А и за счет этого поле типа расширено до четырех бит. Для дескриптора LDT поле типа содержит 2 (0010В). В поле базового адреса находится базовый адрес таблицы LDT, а в поле предела — предел сегмента таблицы LDT. Для задания предела можно использовать все 20 бит; функционирует также бит гранулярности G, поэтому можно создать таблицу LDT с размером больше 64 Кбайт, но на практике этого не требуется.
| также не присутствуют. Процессор даже не разрешает загрузить регистр LDTR селектор неприсутствующей таблицы LDT. |
Отметим, что дескриптор LDT, как и любой другой дескриптор сегмента, имеет бит присутствия Р. Если дескриптор LDT отмечен неприсутствующим (Р = 0), считается, что все дескрипторы из LDT
|
Рис.2.10. Формат дескриптора таблицы LDT
Чтобы начать пользоваться таблицей LDT, нужно просто поместить в регистр LDTR селектор нужной таблицы. В этом отношении регистр LDTR действует как и любой другой сегментный регистр. Для сокращения числа обращений к памяти у регистра LDTR предусмотрен теневой регистр (он показан пунктиром на рис. 2.6), в который процессор автоматически считывает дескриптор LDT при загрузке селектора в регистр LDTR.
При попытке загрузить в регистр LDTR что-то отличающееся от селектора, выбирающего дескриптор LDT, процессор формирует общее нарушение защиты и «виноватый» селектор включается в стек как код ошибки. Когда в дескрипторе бит Р = 0, генерируется особый случай неприсутствия, а селектор по-прежнему будет служить кодом ошибки. Загрузка в регистр LDTR пустого селектора (значения 0000Н — 0003Н) допускается; такая операция сообщает процессору о том, что задача не будет пользоваться локальной дескрипторной таблицей.
Мы пока не касаемся дескрипторной таблицы прерываний IDT. Связано это с тем, что программам никогда не разрешается прямое обращение к IDT. Именно поэтому в селекторе достаточно одного бита индикатора таблицы TI. Таблицу IDT процессор i486 использует автоматически при обработке аппаратных и программных прерываний, которым посвящена следующая лекция.
2.1.7. Особенности сегментации
Процессор i486 разрешает создание сегментов, в которых допускаются операции только считывания, только исполнения, считывания/записи и исполнения/считывания. Однако в нем невозможно прямо создать характерные для процессора 8086 сегменты, в которых одновременно разрешены операции считывания, записи и исполнения. Тем не менее, образовать такие сегменты можно другими средствами.
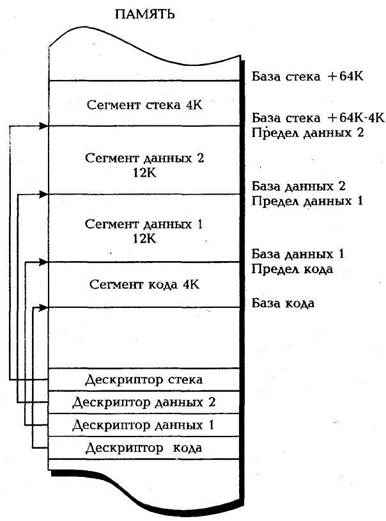
Рис.2.11. Неперекрывающиеся сегменты памяти
В способе сегментации памяти процессора 8086 нет никаких трудностей для обращения по одному и тому же физическому адресу с привлечением различных сегментных регистров. Если, например, в регистрах DS и ES содержатся одинаковые начальные адреса, то оба регистра определяют один и тот же сегмент. Кроме того, как отмечалось выше, множество пар сегмент:смещение могут определять один и тот же физический адрес. Аналогичную ситуацию в процессоре i486 можно смоделировать путем тщательного подбора дескрипторов сегментов.
Обычно дескрипторы сегментов создаются во время инициализации системы для определения всех используемых областей памяти с учетом их назначения. Например, можно определить один сегмент кода для хранения машинных команд (т.е. собственно программы), один или два сегмента для данных и один сегмент для стека, рассчитанный на максимальный размер стекового кадра. Обычно эти сегменты должны занимать различные области памяти. При желании сегментам можно назначить соседние адреса так, чтобы конец одного сегмента совпадал с началом другого. На рис. 2.11 показаны неперекрывающиеся (непересекающиеся) сег мент кода 6 Кбайт, два сегмента данных по 12 Кбайт и сегмент стека 4 Кбайт.
Представим теперь, что дескриптор первого сегмента данных изменен с целью увеличения его предела на 4 Кбайт. В этом случае два сегмента данных оказываются перекрывающимися, что показано на рис. 2.12. Такое перекрытие вполне допустимо, так как процессор i486 не накладывает никаких ограничений на определения перекрывающихся сегментов.
Перекрытие двух или более сегментов в некоторых отношениях может оказаться благоприятным. К любой ячейке в области перекрытия можно обращаться несколькими способами. Например, считывание по смещению 0 из сегмента данных 2 эквивалентно считыванию по смещению 3000Н из сегмента данных 1.
Выше говорилось, что процессор запрещает запись в сегменты, которые определены как исполняемые. Но не будет ошибкой запись в сегмент, который определен с разрешенной операцией записи и просто перекрывает то же линейное адресное пространство, что и исполняемый сегмент. Если дескрипторы сегмента кода и сегмента данных имеют одинаковые базовые адреса и пределы, то можно будет «модифицировать код» и «выполнять данные». Такой прием создания нескольких дескрипторов одного и того же адресного пространства называется альтернативным именованием (aliasing). Очевидно, дескрипторы можно считать именами сегментов; тогда несколько дескрипторов одного и того же сегмента (т.е. альтернативные имена) естественно назвать псевдонимами.
В предельной ситуации можно определить сегмент данных с разрешенными операциями записи и считывания, который имеет базовый адрес 0 и предел OFFFFFFFFH. Загрузка селектора такого дескриптора в сегментный регистр позволяет считывать и записывать по любому адресу всего линейного адресного пространства процессора i486. По существу, для любого сегмента в системе имеется альтернативное имя. Конечно, система не обязательно должна иметь физическую память 4 Гбайт; этот пример только показывает,
о попускается описывать несуществующее пространство памяти к же легко, как и перекрывающиеся диапазоны адресов.
ПАМЯТЬ
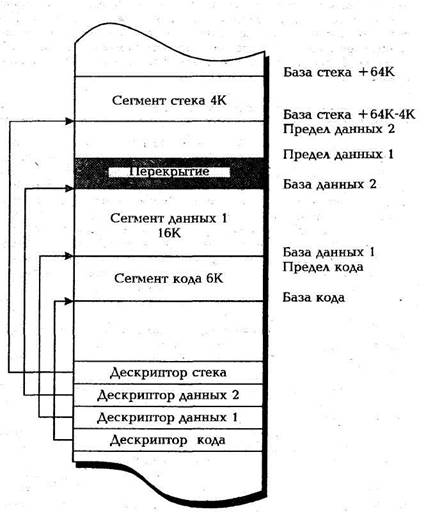
Рис.2.12. Перекрывающиеся сегменты памяти
Перекрытие и альтернативное именование оказываются очень удобными для разделения данных между задачами. Например, создание для сегмента кода псевдонима в виде сегмента данных позволяет разработать самомодифицирующиеся программы. Упомянем еще один очень важный момент. Пространство, занятое дескрипторной таблицей, невозможно адресовать, не имея определяющего его дескриптора. Если не создать псевдонимов для дескрипторных таблиц в виде сегментов данных до перевода процессора i486 в Р-режим, то к таблицам будет невозможно обратиться. Конечно, определения этих сегментов должны быть максимально защищенными, так как разрешение всем программам доступа к таблицам GDT, IDT и LDT для считывания и записи приведет к катастрофическим последствиям.
Дата добавления: 2015-06-05; просмотров: 2353;