Глава 4 Ассоциативный анализ
Ассоциативный анализ служит для выявления связей между переменными. Применительно к маркетинговым исследованиям данная группа статистических процедур позволяет ответить на вопросы типа:
■ Влияет ли на частоту посещения магазина уровень доходов покупателей?
■ Как связаны между собой пол респондентов и желание купить мотоцикл?
■ Как влияет на покупательское поведение потребителей сухих строительных смесей род занятий респондентов?
То есть при помощи ассоциативного анализа становится возможным анализировать вопросы анкеты не только по отдельности, а в зависимости от других вопросов. Этот вид анализа иногда называют построением разрезов, поскольку он позволяет определить не только наличие связи между вопросами анкеты, но и силу связи между переменными и то, каким образом ведет себя одна переменная при изменении другой (возрастает или убывает).
В процессе ассоциативного анализа выявляются следующие типы зависимостей.
■ Немонотонныезависимости свидетельствуют только о наличии определенной связи между двумя переменными, но не позволяют судить о направлении или силе связи. Пример немонотонной зависимости: мужчины в основном покупают рыбные консервы в продовольственных магазинах, а женщины — на рынках.
■ Монотонныезависимости — это зависимости, по которым можно узнать не только наличие, но и направление связи. Пример монотонной зависимости: мужчины покупают пиво чаще, чем женщины. Монотонные зависимости бывают двух видов:
возрастающие — первая переменная возрастает при возрастании второй;
убывающие — первая переменная убывает при возрастании второй.
■ Линейные зависимости характеризуются уравнением функции у = а + Ьх (график линейной функции). Связь между двумя переменными в данном случае является линейной, то есть на основании этой зависимости мы можем сказать, насколько изменится одна переменная при изменении второй.
■ Нелинейные. Примерами нелинейных связей между двумя переменными являются: экспоненциальная, логарифмическая, степенная, полиномиальная зависимости — то есть в данном случае связь присутствует и изменяется по какому-либо известному математическому закону.
Зависимости, выявленные в результате ассоциативного анализа, можно охарактеризовать тремя аспектами.
■ По наличию — определенная (систематическая) связь между двумя переменными есть.
■ По направлению — связь является убывающей или возрастающей.
■ По силе — можно определить, насколько тесно связаны между собой две переменные, то есть насколько значима данная зависимость.
Между переменными с номинальной шкалой может быть установлена только немонотонная зависимость, характеризуемая только наличием связи. Для переменных, имеющих порядковую или интервальную шкалу, данное ограничение не действует — для них можно определить и направление, и силу связи.
4.1. Перекрестные распределения и 
Перекрестные распределения служат для выявления различных типов зависимостей между двумя и более переменными. Например, если требуется установить, где покупают сгущенное молоко мужчины и женщины, следует воспользоваться таблицами перекрестных распределений (таблицами сопряженности, или кросста-буляции). На основании перекрестных распределений можно установить не только наличие зависимости (немонотонной или монотонной) между переменными, но, в большинстве случаев, ее тип (линейная или нелинейная) и направление (возрастающая или убывающая)1. Установленная при помощи перекрестного распределения зависимость может оказаться незначимой из-за малого размера выборки или по другим причинам. Статистическую значимость выявленной зависимости позволяет определить критерий .
В табл. 4.1 представлены основные характеристики переменных, участвующих в анализе.
Несмотря на то что перекрестные табуляции можно строить по переменным, имеющим любой тип шкалы, необходимо иметь в виду, что большое количество категорий (вариантов ответа) анализировать трудно. Даже если анализ выявит значимую зависимость, при наличии большого числа категорий переменных исследователю будет сложно понять, каким именно образом связаны данные переменные.
Таблица 4.1. Основные характеристики переменных, участвующих в перекрестных распределениях
| Перекрестные распределения | |||
| Зависимые переменные | Независимые переменные | ||
| Количество | Тип | Количество | Тип |
| От двух до десяти | Любой | От двух до десяти | Любой |
Также следует отметить, что наибольшую эффективность кросстабуляционный анализ показывает на номинальных и порядковых переменных. Для интервальных переменных больше подходит корреляционный анализ, рассматриваемый в разделе 4.2.
И наконец, последним ограничением применения перекрестных распределений для анализа зависимостей между переменными является тот факт, что различные статистические тесты (такие как ) могут быть использованы только при анализе одновариантных переменных. Статистические тесты, применяемые для анализа зависимостей, предназначены только для двух переменных. При наличии дополнительных слоев или уровней кросстабуляционной таблицы статистический анализ производится для каждого уровня отдельно, при этом на каждом уровне он работает только с двумя переменными. Для многовариантных переменных SPSS содержит возможность отдельного построения кросстабуляции — выявить наличие и направление связи в данном случае можно только визуально.
Далее в этой главе мы покажем, как строить перекрестные распределения и анализировать зависимости для одновариантных и многовариантных переменных.
4.1.1. Перекрестные распределения для одновариантных вопросов и
Давайте рассмотрим перекрестные распределения для одновариантных вопросов на следующем примере.
ПРИМЕР----------------------------------------------------------------------------------------------
Исходные данные:
В результате маркетингового исследования, посвященного исследованию потребительских предпочтений посетителей развлекательного центра, оказалось, что средняя частота посещения центра составляет приблизительно 12 раз в месяц. Также были получены данные о распределении среди посетителей центра мужчин и женщин различных возрастных групп. В ходе подготовительного этапа анализа были сформированы, в частности, три одновариантные переменные:
1) частота посещения центра (q25);
2) возраст респондентов (ql8);
3) пол респондентов (q23). Требуется:
1. Построить перекрестное распределение частоты посещения развлекательного центра в разрезе возраста и пола респондентов. Рассчитать среднюю частоту посещения центра различными целевыми группами потребителей.
2. Определить, влияет ли на частоту посещения центра возраст потребителей. Установить статистическую значимость зависимости между частотой посещения и возрастом.
---------------------------------------------------------------------------------------------------------------------
Из условия первой задачи следует, что мы должны построить перекрестное распределение сразу по трем переменным: q25 в зависимости от ql8 и q23 (то есть трехуровневое). Для решения задачи воспользуемся меню Analyze ► Descriptive Statistics ► Crosstabs. В открывшемся диалоговом окне (рис. 4.1) из левого списка, содержащего все доступные переменные, выберите те, которые будут расположены в строках результирующей таблицы, и те, которые будут расположены в столбцах. Поместите зависимую переменную q25 Частота посещения в область Rows (варианты ответа на вопрос о частоте посещения будут расположены в строках таблицы), а независимую переменную ql8 Возраст — в область Columns (возрастные группы будут расположены в столбцах таблицы). Осталась еще одна независимая переменная q23 Пол. Поместите ее в область Layer (уровень или слой таблицы).
Обратите внимание, что всегда, когда обратное не обусловлено задачами исследования, рекомендуется размещать переменные с малым количеством вариантов ответа в слоях. Это позволит уменьшить размерность результирующей таблицы. Мы можем задать и большее количество измерений таблицы, щелкая на кнопке Next в области Layer и добавляя релевантные переменные. Максимальное количество слоев, которое можно задать, щелкая на кнопке Next, — 8. Следовательно, максимально возможное количество измерений перекрестной таблицы по одновариантным вопросам — 10(10 = 8 слоев + 1 строковая переменная + 1 столбцовая переменная).
 |
В диалоговом окне Crosstabs в область каждого измерения (Rows, Columns, Layer) можно поместить сразу несколько переменных. Максимальное число переменных, которые можно поместить в области Rows и Columns, — 76; для каждого из восьми возможных уровней Layer — 6. Если задано по одной переменной в строке и столбце (как в нашем случае), все дополнительно указанные слои будут отображаться в одной и той же таблице. Ситуация будет отличаться, если мы укажем несколько переменных для строк, столбцов и слоев в одних и тех же областях (не щелкая на кнопке Next для задания нескольких слоев) перекрестной таблицы. В этом случае будут построены отдельные таблицы для каждой пары строковых и столбцовых переменных.
|
Теперь, когда вы указали все переменные для анализа, для построения перекрестных распределений можно щелкнуть на кнопке ОК. Однако сначала давайте рассмотрим некоторые другие полезные функции диалогового окна Crosstabs. Щелкните на кнопке Cells. Отрывшееся диалоговое окно Cell Display (рис. 4.2) предназначено для задания значений, выводимых в кросстабуляционной таблице. По умолчанию SPSS в каждой ячейке таблицы выводит только количество респондентов (параметр Observed). Область Percentages позволяет организовать вывод в ячейках таблицы процентов по строкам (Rows), столбцам (Columns), а также от общего числа респондентов, ответивших одновременно на все вопросы, по которым строится перекрестное распределение (Частота посещения, Возраст и Пол) (Total).
Чтобы проиллюстрировать наш пример (расчет средних частот покупки), выведем проценты по вопросу Частота посещения внутри каждой возрастной и половой группы респондентов, отметив параметр Columns и проценты по всем возрастным группам в целом (Total). Также оставим выбранный по умолчанию вывод наблюдаемых частот (Observed). После этого можно закрыть окно Cell Display, щелкнув на кнопке Continue.
|
 |
 |
Следующее диалоговое окно, которое мы рассмотрим, — это Table Format, вызываемое при помощи кнопки Format (рис. 4.3). В нем можно выбрать тип сортировки вариантов ответа строковой переменной: возрастающая или убывающая (по алфавиту). Оставьте выбранный по умолчанию вариант Ascending (возрастающая) и щелкните на кнопке Continue, чтобы закрыть окно. После этого запустите процедуру построения перекрестных распределений, щелкнув на кнопке О К в главном диалоговом окне Crosstabs. В главном диалоговом окне процедуры есть и другие полезные (Ьункпии: мы оассмотоим их ниже.
|
После этого в окне SPSS Viewer будет выведена требуемая таблица перекрестного распределения (рис. 4.4). В ячейках данной таблицы находятся искомые частоты
посещения развлекательного центра каждой из анализируемых целевых групп опрошенных. Например, первая ячейка показывает, что 5 (строка Count) респондентов-мужчин в возрасте от 18 до 25 лет посещают развлекательный центр каждый день. Это составляет 8,1% (подстрока % within Возраст) от общего количества мужчин в возрасте от 18 до 25 лет, ответивших на три предложенных вопроса, или 1,5% (подстрока % of Total) от общего числа мужчин, ответивших на вопросы (это число 333, оно представлено на пересечении строки и столбца Total в первой части таблицы Мужчины).
Строка Total показывает, сколько всего мужчин из каждой возрастной группы ответили на вопрос о частоте посещения центра (в нашем случае 62 респондента-мужчины в возрасте от 18 до 25 лет). Столбец Total показывает, сколько всего мужчин, посещающих развлекательный центр с различной частотой, ответили на вопрос о возрасте (в нашем случае 15 респондентов-мужчин, посещающих центр каждый день).
 |
Вторая часть таблицы Женщины построена аналогичным образом. Как вы видите, 15,8% женщин в возрасте от 41 до 45 лет посещают развлекательный центр 1-2 раза в месяц.
|
На основании представленной таблицы перекрестного распределения вы можете рассчитать вручную средневзвешенные частоты посещения респондентами развлекательного центра в зависимости от их пола и возраста. Для этого скопируйте анализируемую таблицу в Microsoft Excel, щелкнув на ней правой кнопкой мыши в окне SPSS Viewer и выбрав пункт Сору (не Copy Objects !). Окончательный вид полученного распределения представлен в табл. 4.2.
Таблица 4.2. Средневзвешенные частоты посещения развлекательного центра в зависимости от пола и возраста респондентов (раз в месяц)
| Пол | Возраст | |||||||
| ОТ 18 до 25 лет | От 26 до 30 лет | От 31 до 35 лет | От 36 до 40 лет | От 41 до 45 лет | От 46 до 50 лет | От 51 до 55 лет | Старше 55 | |
| Мужчины | ||||||||
| Женщины |
Из представленной таблицы следует, что средняя частота посещения развлекательного центра различными половозрастными группами респондентов несколько различается. Однако, исходя только из визуальных предположений, нельзя утверждать то, что частота посещения центра действительно зависит от пола и возраста. Для этого любая выявленная закономерность должна удовлетворять условию статистической значимости. Определить, значима ли выявленная нами зависимость, позволяют статистические тесты, выполняемые при построении перекрестных распределений.
Далее мы покажем, как решается второй пункт нашей задачи (условие см. выше), то есть как ответить на вопрос: «Действительно ли существует статистически значимая зависимость между тремя анализируемыми переменными или показанные в табл. 4.2 различия в частотах посещения центра вызваны влиянием случайных факторов (то есть как таковой зависимости нет)?».
Выявить статистическую значимость зависимостей между переменными позволяют критерий 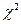 и сопутствующие тесты. Исследуем нашу зависимость между частотой посещения развлекательного центра, полом и возрастом респондентов на предмет статистической значимости. Для этого вновь откройте диалоговое окно Crosstabs. В этом окне остались две не рассмотренные нами кнопки: Exact и Statistics — именно они позволяют исследовать значимость перекрестных распределений. По умолчанию SPSS определяет статистическую значимость только на основании асимптотического метода. Одной из разновидностей данного метода и является . Данный критерий используется наиболее часто в маркетинговых исследованиях. Однако применение асимптотического критерия накладывает на данные, содержащиеся в анализируемой перекрестной таблице, существенные ограничения, которые подробно описаны ниже.
и сопутствующие тесты. Исследуем нашу зависимость между частотой посещения развлекательного центра, полом и возрастом респондентов на предмет статистической значимости. Для этого вновь откройте диалоговое окно Crosstabs. В этом окне остались две не рассмотренные нами кнопки: Exact и Statistics — именно они позволяют исследовать значимость перекрестных распределений. По умолчанию SPSS определяет статистическую значимость только на основании асимптотического метода. Одной из разновидностей данного метода и является . Данный критерий используется наиболее часто в маркетинговых исследованиях. Однако применение асимптотического критерия накладывает на данные, содержащиеся в анализируемой перекрестной таблице, существенные ограничения, которые подробно описаны ниже.
Так, важнейшим требованием к исследуемым данным является достаточно большие значения в ячейках таблицы. При наличии небольших по размеру выборок или при построении разрезов третьего и более уровня данное условие является недостижимым. Исходя из опыта анализа данных в маркетинговых исследованиях, можно утверждать, что подобные ситуации встречаются достаточно часто. В связи с этим в случае несоответствия имеющихся данных общепринятому критерию следует воспользоваться другими статистическими методами.
Сначала на примере перекрестного распределения по трем переменным рассмотрим использование наиболее популярного статистического метода установления статистической значимости зависимостей — критерия . Для того чтобы организовать наряду с перекрестной таблицей вывод соответствующих статистик, в главном диалоговом окне Crosstabs щелкните на кнопке Statistics (рис. 4.5). В открывшемся диа-
логовом окне выберите параметр Chi-square ). Это позволит впоследствии определить, имеется ли определенная связь между исследуемыми переменными.
При анализе зависимостей, кроме обнаружения наличия связи, также можно определить, насколько сильно выражена данная зависимость (установить силу связи). Сделать это позволяют релевантные статистические тесты, применяемые отдельно для каждого из трех типов переменных, участвующих в анализе. Для номинальных переменных следует применять один из тестов, представленных в области Nominal. Наиболее универсальным и часто применяемым методом является V Cramer's. Для порядковых переменных следует применять один из методов, представленных в области Ordinal. Мы рекомендуем использовать наиболее универсальный метод: Gamma. Теоретически этот же метод можно применять и для интервальных переменных, однако все же для них рекомендуется использовать более релевантную процедуру корреляционного анализа.
Далее рассмотрим, как применять перечисленные статистические методы на примере нашей задачи с двумя порядковыми переменными Частота посещения развлекательного центра и Возраст. Для этого выберите параметр Gamma и закройте описываемое окно, щелкнув на кнопке Continue. Запустите процедуру построения перекрестных распределений, щелкнув на кнопке ОК в главном диалоговом окне Crosstabs.
|
 |
В окне SPSS Viewer появится уже рассмотренная выше таблица перекрестного распределения трех переменных: Частота посещения, Возраст и Пол. Но, в отличие от предыдущего случая, ниже будут отображены две таблицы, из которых можно узнать о наличии, силе и направлении (только для порядковых и интервальных переменных) связи между анализируемыми переменными. Рассмотрим их по порядку.
В первой таблице, Chi-Square Tests, выводятся результаты расчета критерия (строка Pearson Chi-Square) и некоторых других статистик (рис. 4.6). Необходимо отметить, что расчет всех статистических процедур производится для каждого варианта переменной, расположенной в слоях (в нашем случае Пол) по отдельности (то есть отдельно для целевых групп мужчин и женщин). Данное обстоятельство уже было отмечено выше.
В нашем примере для респондентов-мужчин величина критерия — 56,048, однако для практических целей важна не столько сама величина, столько ее значимость, представленная в столбце Asymp. Sig. (2-sided). Именно из условия статистической значимости критерия следует статистическая значимость всей зависимости. В нашем примере значимость анализируемого критерия и для мужчин, и для женщин достаточно высока (0,001 и 0,014 соответственно), что позволяет сделать предварительный вывод о том, что между частотой посещения развлекательного центра и возрастом для каждой половой группы респондентов существует определенная статистически значимая зависимость. Тем не менее одной значимости критерия недостаточно, чтобы с уверенностью утверждать о наличии значимой зависимости между тремя анализируемыми переменными. Для этого необходимо, чтобы выполнялись следующие два критерия.
Процент ячеек, в которых ожидаемые значения1 (Expected counts) меньше или равны 5, должен быть менее или равным 20 %. Это значение отображается в примечании «а» в первой строке после таблицы Chi-Square Tests. На практике приемлемая доля ожидаемых частот меньше 5 может отклоняться от 20 % (в пределах +5 %). При наличии ярко выраженной зависимости можно считать такую зависимость статистически значимой. Также всегда необходимо иметь в виду практические соображения (и это относится ко всем без исключения статистическим процедурам). Если ожидаемые частоты меньше 5 у переменных, представляющих малую практическую значимость для исследователя, — значит, можно не принимать в расчет рассматриваемый критерий и признать зависимость значимой по практическим соображениям. Как видно на рис. 4.58, в нашем случае 55 % ячеек имеют ожидаемые значения меньше 5 (при этом минимальное ожидаемое значение 0,32). Следовательно, несмотря на то что критерий является статистически значимым, он не удовлетворяет рассматриваемому дополнительному условию.
Суммы по строкам и столбцам должны быть больше 0. В нашем случае данное условие удовлетворяется.
Еще одной не рассмотренной статистикой в таблице Chi-Square Tests является тест Mantel-Hanzel (строка Linear-by-Lf near Association). Его значимость позволяет сделать вывод о наличии линейной зависимости между неноминальными переменными. Если величина данного теста статистически значима, следовательно, между строковой и столбцовой переменными есть линейная зависимость. В нашем случае (рис. 4.6) линейная зависимость между возрастом и частотой посещения развлекательного центра существует только в целевой группе респондентов-женщин. Про мужчин подобное сказать нельзя.
 |
После того как мы установили наличие зависимости между тремя анализируемыми переменными (при этом между возрастом и частотой посещения для респондентов-женщин существует и линейная зависимость), можно приступить к анализу таблицы Symmetric Measures (рис. 4.7), чтобы определить силу выявленной связи.
|
|
 |
Для порядковых переменных (как в нашем случае) определить силу связи позволяет критерий Gamma. Этот показатель может варьироваться в интервале от -1 (максимально разнонаправленная зависимость) до 1 (полная зависимость); значение О показывает полное отсутствие зависимости. Значение критерия Gamma представлено в столбце Value таблицы Symmetric Measures. В нашем случае в группе респондентов-мужчин имеется лишь весьма слабая положительная зависимость (Gamma = 0,080). Столбец Approx. Sig. свидетельствует о том, что данная зависимость еще и статистически незначима. Обратная ситуация в группе респондентов-женщин: для них установлена слабая, но статистически значимая положительная зависимость между возрастом и частотой посещения развлекательного центра.
Если в перекрестном анализе участвуют номинальные переменные, силу (но не направление) связи позволяет определить критерий Cramer's V. Отображение этого критерия можно установить в диалоговом окне Statistics при помощи параметра Phi and Cramer's V (см. рис. 4.5).
Давайте рассчитаем данный критерий для наших переменных. Результаты расчетов представлены на рис. 4.8. В целом, критерий Cramer's V может варьироваться в пределах от 0 до 1, где 0 показывает отсутствие связи между исследуемыми переменными, а 1 — полную зависимость. В нашем случае и для мужчин, и для женщин есть статистически значимые (как показывает столбец Approx. Sig.) слабые зависимости (для мужчин Cramer's V = 0,205; для женщин = 0,176). Необходимо отметить, что значение 1 для теста Cramer's V является практически недостижимым, поэтому значения 0,8-0,9 следует считать весьма высокими.
 |
|
Итак, мы определили, что между тремя анализируемыми переменными — возрастом, полом и частотой посещения респондентами развлекательного центра — есть слабые, но статистически значимые зависимости. Вместе с тем было установлено, что больше половины (55 %) ячеек в перекрестной таблице имеют ожидаемые частоты меньше 5 — из чего следует вывод о неприменимости теста и сопутствующих асимптотических тестов (Gamma и Cramer's V) в нашем случае. В принципе мы ответили на второй пункт задачи (условие см. выше) и можем сказать, что различия, выявленные в ходе перекрестного анализа (см. табл. 4.2), действительно имеют место и являются статистически значимыми. Однако добросовестный аналитик в такой ситуации все же попытается доказать истинность сделанных выводов.
Когда анализируемые данные не удовлетворяют требованиям, предъявляемым асимптотическими методами (как, например, в нашем случае ), есть другая возможность установить статистическую значимость исследуемой зависимости. Это позволяют сделать точные (Exact) тесты.
Откройте главное диалоговое окно перекрестного анализа Crosstabs (см. рис. 4.1), щелкнув на кнопке Exact. В появившемся диалоговом окне Exact Tests (рис. 4.9) по умолчанию установлен расчет только асимптотических критериев. Данное диалоговое окно позволяет провести расчеты по двум неасимптотическим методам: Monte-Carlo и Exact, причем последний метод не рекомендуется использовать в практических целях, так как он занимает много времени. Для практических целей следует применять метод Monte-Carlo с установленным по умолчанию количеством выборок (10 000). Доверительный уровень 99 % практически всегда является слишком высоким, поэтому измените его на 95 %, что соответствует доверительному уровню при расчете статистической ошибки выборки для маркетинговых исследований (см. раздел 1.2). Все остальные параметры диалогового окна Crosstabs аналогичны указанным в предыдущем примере. Теперь можно запустить процедуру построения перекрестных распределений.
|
 |
После завершения всех необходимых расчетов в окне SPSS Viewer будут выведены результаты. Их структура аналогична рассмотренной выше, за исключением того, что таблицы Chi-Square Tests и Symmetric Measures расширены за счет результатов теста Monte-Carlo. Единственным практическим результатом данного теста является рассчитанная статистическая значимость критериев, указанных в диалоговом окне Statistics (см. рис. 4.5).

На рис. 4.10 представлена таблица Chi-Square Tests с результатами теста Monte-Carlo. Искомые значения статистической значимости представлены в столбце Monte Carlo Sig. (2-sided) в подстолбце Sig.. В подстолбцах Lower Bound и Upper Bound показаны, соответственно, нижний и верхний пределы, в которых варьируется значение статистической значимости Sig.. Так, в нашем случае критерий действительно свидетельствует о наличии статистически значимой зависимости между полом, возрастом и частотой посещения развлекательного центра — это следует из весьма высокой значимости теста Monte-Carlo (0,001 — для мужчин и 0,012 — для женщин). В 95 % случаев данное значение не выходит за рамки статистической значимости (например, для мужчин оно варьируется в пределах от 0,001 до 0,002). Также из таблицы мы видим, что выявленная связь является линейной только для целевой группы респондентов-женщин. Таким образом, для нашего случая все предварительные выводы, сделанные нами в таблице Chi-Square Tests, подтвердились результатами теста Monte-Carlo.
|

Теперь рассмотрим таблицу Symmetric Measures (рис. 4.11), на основании которой мы сделали выводы о силе выявленной зависимости. Результаты теста Monte-Carlo и в данном случае подтверждают выводы асимптотического метода: между частотой посещения центра и возрастом в целевой группе респондентов-женщин выявлена слабая статистически значимая зависимость. Для мужчин зависимость статистически незначима.
|
Таким образом, мы выяснили, что между частотой посещения развлекательного центра и возрастом респондентов-женщин существует статистически значимая зависимость, характеризующаяся слабой положительной линейностью. Для респондентов-мужчин возраст и частота посещения центра также связаны статистически значимой зависимостью, однако сделать точный вывод о характере данной зависимости не представляется возможным.
Вернемся к табл. 4.2 и покажем, как интерпретировать представленные в ней данные. На основании проведенных расчетов можно утверждать, что мужчины в возрасте старше 51 года посещают развлекательный центр реже всего (примерно 2 раза в неделю). Наиболее частыми посетителями развлекательного центра являются мужчины в возрасте младше 50 лет (примерно 3 раза в месяц). В целевой группе женщин можно выделить три группы. Наиболее частыми посетителями являются женщины в возрасте 31-35 лет (примерно 4 раза в неделю). Среднюю группу (примерно 3 раза в неделю) составляют женщины младше 30 лет, от 36 до 40 лет и старше 46 лет. И наконец, группу респондентов-женщин, посещающих центр реже всего, составляет возрастная группа от 41 до 45 лет.
4.1.2. Перекрестные распределения для многовариантных вопросов
Как уже было сказано выше (см. раздел 3.2), все статистические процедуры применимы только для одновариантных вопросов. На практике установить статистическую зависимость в многовариантных вопросах можно только двумя способами.
■ Визуально. В этом случае аналитик должен самостоятельно (на основании опыта или опираясь на другие данные, выявленные в ходе исследования) попытаться сделать заключение о значимости различий между двумя переменными. Например, если мужчины покупают сметану в упаковке в 4 раза чаще, чем женщины, и при этом число респондентов, ответивших на данный вопрос, достаточно велико (скажем, 100 человек), можно сделать вывод о статистической значимости данного различия.
■ Можно рассматривать многовариантный вопрос как несколько дихотомических переменных с вариантами ответа «есть/нет» и строить по ним стандартные перекрестные распределения (при помощи процедуры Crosstabs). На практике в подавляющем большинстве случаев именно данный способ является оптимальным. Тем не менее необходимо отметить, что дихотомические переменные, являющиеся вариантами ответа на многовариантный вопрос, могут принимать участие даже в корреляционном анализе в качестве порядковых переменных (см. раздел 4.2).
Кроме существенных ограничений при установлении статистических зависимостей между многовариантными переменными, их анализ осложнен также и тем, что результаты перекрестных распределений по многовариантным вопросам SPSS выводит только в виде простого текста (plain text)1.
Ниже мы проиллюстрируем процесс построения перекрестных распределений по многовариантным переменным на примере двух многовариантных вопросов из маркетингового исследования московского рынка сметаны. Первый вопрос Где Вы покупаете сметану? (q7) с вариантами ответа:
■ продмаг (q7_l);
■ рынок (q7_2);
■ супермаркет (q7_3);
■ палатка (q7_4);
■ универсам (q7_5).
Второй вопрос Какую сметану Вы предпочитаете? с вариантами ответа:
■ в упаковке (ql6_l);
■ развесную (ql6_2).
Как было сказано выше в разделе 2.2.2, чтобы строить распределения (линейные или перекрестные) по многовариантным переменным, сначала их нужно сформировать. Мы не будем возвращаться к процедуре создания многовариантных переменных при помощи меню Analyze ► Multiple Response ► Define Sets; этот процесс описан в разделе 2.2.2. Давайте исходить из того, что вы самостоятельно сформировали две многовариантные переменные, назовем их q7 (Место покупки сметаны) и ql6 (Наиболее предпочтительная для респондентов упаковка сметаны). Теперь можно заняться построением перекрестного распределения по этим вопросам, то есть ответить на вопрос: «Зависят ли предпочтения респондентов в отношении сметаны (упакованной или развесной) от места совершения покупки?».
Построение перекрестного распределения по многовариантным вопросам осуществляется при помощи меню Analyze ► Multiple Response ► Crosstabs. В открывшемся диалоговом окне (рис. 4.12) слева вы видите два списка переменных. В верхнем находятся все доступные переменные из файла данных (включая и дихотомические переменные — варианты ответа на анализируемые многовариантные вопросы). Нижний список содержит только сформированные нами многовариантные переменные ($q7 и $ql6). В перекрестном анализе могут принимать участие как
 |
многовариантные переменные, так и другие доступные одновариантные переменные. Как для кросстабуляций (см. раздел 4.1.1), для перекрестных таблиц можно задать несколько измерений (максимум три) при помощи введения одного дополнительного слоя (область Layer). Имейте в виду, что при построении перекрестных таблиц, переменные, находящиеся в областях Row(s), Column(s) и Layer(s), перекрещиваются по тройкам последовательно.
|
Итак, поместите в область Row(s) переменную Место покупки сметаны (q7), а в область Column(s) — переменную Предпочтения сметаны (ql6). В область Layer(s) поместите переменную Пол (q3).
Как вы поняли, мы будем рассматривать трехмерное перекрестное распределение. Обратите внимание на то, что при внесении в одну из трех областей переменной из верхнего левого списка (всех доступных переменных в базе данных) после имени этой переменной появляется строка символов вида (? ?) и становится доступной кнопка Define Ranges. Это подсказывает нам, что следует ввести границы изменения одновариантной переменной. Выделите переменную q3 в поле Layer(s) и щелкните на кнопке Define Ranges.
 |
На экране появится новое диалоговое окно Define Variable Ranges (рис. 4.13). В нем в соответствующих полях следует указать минимальное Minimum и максимальное Maximum значения, которые может принимать данная переменная. В нашем случае пол респондентов может быть либо мужским (код 1), либо женским (код 2). Поэтому введите 1 в качестве минимального значения, а 2 — в качестве максимального и щелкните на кнопке Continue для того, чтобы закрыть это диалоговое окно.
|
Необходимо отметить, что переменные, участвующие в рассматриваемом статистическом анализе, для которых указываются интервалы допустимых значений, должны принимать только целые значения (дробные SPSS будет игнорировать). Это связано с ограничением при использовании в кросстабуляциях по многовариантным вопросам переменных с интервальной шкалой. Такие переменные могут использоваться, только если они принимают целые значения.
Щелкните на кнопке Options. Открывшееся диалоговое окно (рис. 4.14) позволяет указать, нужно ли выводить проценты (по строкам — Row, по столбцам — Column или общие — Total), а также определить, что является базой для расчета процентов: количество респондентов (Cases) или количество ответов на вопрос (Responses)1.
 |
|
Давайте выведем проценты по строкам (то есть доли респондентов, предпочитающих разный вид сметаны в каждом из пяти рассматриваемых типов торговых точек). Оставьте выбранный по умолчанию параметр Cases в области Percentages Based on — это позволит вам рассчитать проценты от общего числа респондентов (гистограмма), а не от количества ответов на вопрос (сектограмма). Щелкните на кнопке Continue для того, чтобы закрыть диалоговое окно, и запустите процедуру построения перекрестного распределения при помощи щелчка на кнопке О К в главном диалоговом окне программы.
В окне SPSS Viewer будет выведена перекрестная таблица с результатами расчетов. Обратите внимание, что таблица разбита на две части: первая содержит результаты построения перекрестного распределения предпочтений сметаны и места покупки для мужчин (рис. 4.15), а вторая — для женщин (рис. 4.16). Таким образом, можно сказать, что собственно построения перекрестного распределения по трем заданным переменным (включая переменную Пол) не происходит.
 |
Переменная, указанная в качестве слоя (Layer), не отображается в таблице. Вместо этого ее значение (для каждого из вариантов ответа, в нашем случае — мужчины и женщины) отображается в верхней части каждой кросстабуляции как текст Category = 1 Мужчины (для мужчин) и Category = 2 Женщины (для женщин).
|
|
 |
В нижней части под всеми таблицами расположены две строки, содержащие информацию об общих параметрах построения перекрестных распределений. Так, в нашем случае мы видим, что все проценты, представленные в таблицах, рассчитаны от общего числа респондентов (Percents and totals based on respondents). Во второй строке отражаются:
■ количество результативных анкет (то есть анкет, в которых респонденты ответили на три вопроса) — 940 valid cases;
■ количество анкет, не включенных в анализ (респонденты не дали ответа хотя бы на один из трех вопросов), — 63 missing cases.
Общий размер выборки равен сумме результативных и исключенных анкет: 1003 = 940 + 63. В таблицах приведены результаты построения перекрестного распределения предпочтений респондентов по типу сметаны в зависимости от места покупки. Необходимо отметить, что проценты в ячейках таблицы отражают доли покупателей, предпочитающих сметану в упаковке и развесную для каждого из рассматриваемых мест покупки. Например, 75,5 % мужчин, покупающих сметану в продовольственных магазинах, предпочитают сметану в упаковке, а 24,5 % — развесную1.
Проценты в строке Column Total отражают доли респондентов, предпочитающих сметану в упаковке или развесную, от общего числа респондентов (в нашем случае мужского или женского пола), ответивших на рассматриваемые вопросы. Например, 79 % мужчин, ответивших на рассматриваемые вопросы, предпочитают упакованную сметану, а 21 % — развесную.
Проценты в столбце Row Total отражают доли респондентов, покупающих сметану в различных торговых точках. На рис. 4.15 вы видите, что 51,9 % мужчин, ответивших на рассматриваемые вопросы, покупают сметану в продовольственных магазинах. Значения на пересечении строки Column Total и столбца Row Total показывают общее количество респондентов мужского пола, ответивших на вопросы о предпочтениях сметаны и месте покупки (как и всегда, в абсолютных и относительных величинах). В нашем случае на рассматриваемые вопросы ответил 181 мужчина. Обратите внимание, что длинные таблицы, выводимые в виде текста, могут по умолчанию не отражаться полностью в окне SPSS Viewer. Чтобы убедиться, что вы видите таблицу целиком, дважды щелкните мышью на ней. Откроется специальная область с возможностью прокрутки, в которой вы можете увидеть все построенные таблицы.
Дата добавления: 2015-04-25; просмотров: 1423;