Основы компиляции
Программы, написанные на языках программирования высокого уровня, перед выполнением на ЭВМ должны транслироваться в эквивалентные программы, написанные на машинном коде. Транслятор – это программа, которая переводит программу на исходном (входном) языке в эквивалентную ей программу на результирующем (выходном) языке. Если исходный язык является языком высокого уровня, например, таким как Паскаль, С++, и если объектный язык – автокод, то такой транслятор называется компилятором.
Достоинство компилятора заключается в том, что программа компилируется один раз, и при каждом выполнении не требуется дополнительных преобразований. Соответственно, не требуется наличие компилятора на целевой машине, для которой компилируется программа. Недостаток: отдельный этап компиляции замедляет написание и отладку и затрудняет исполнение небольших, несложных или разовых программ. В том случае, если исходный язык является языком ассемблера (низкоуровневым языком, близким к машинному языку), компилятор такого языка называется ассемблером.
Другой метод реализации программ, написанных на языке высокого уровня, – интерпретация [21]. Интерпретатор программно моделирует машину, цикл выборки-исполнения которой работает с командами на языках высокого уровня, а не с машинными командами. Такое программное моделирование создает виртуальную машину, реализующую язык. Этот подход называется чистой интерпретацией. Чистая интерпретация применяется, как правило, для языков с простой структурой (например, АПЛ или Лисп). Интерпретаторы командной строки обрабатывают команды в скриптах в UNIX или в пакетных файлах (.bat) в MS-DOS, как правило, также в режиме чистой интерпретации.
Достоинство чистого интерпретатора: отсутствие промежуточных действий для трансляции упрощает реализацию интерпретатора и делает его удобнее в использовании, в том числе в диалоговом режиме. Недостаток – интерпретатор должен быть в наличии на целевой машине, где должна исполняться программа. А свойство чистого интерпретатора, что ошибки в интерпретируемой программе обнаруживаются только при попытке выполнения команды (или строки) с ошибкой, можно признать как недостатком, так и достоинством [20].
Существуют компромиссные между компиляцией и чистой интерпретацией варианты реализации языков программирования, когда интерпретатор перед исполнением программы транслирует ее на промежуточный язык (например, в байт-код или p-код), более удобный для интерпретации (т.е. речь идет об интерпретаторе со встроенным транслятором). Такой метод называется смешанной реализацией. Примером смешанной реализации языка может служить Perl. Этот подход сочетает как достоинства компилятора и интерпретатора (бомльшая скорость исполнения и удобство использования), так и недостатки (для трансляции и хранения программы на промежуточном языке требуются дополнительные ресурсы; для исполнения программы на целевой машине должен быть представлен интерпретатор). Так же, как и в случае компилятора, смешанная реализация требует, чтобы перед исполнением исходный код не содержал ошибок (лексических, синтаксических и семантических).
Для компиляции компилятор должен выполнить анализ исходной программы, а затем синтез объектной программы. Сначала исходная программа разлагается на ее составные части; затем из них строятся части эквивалентной объектной программы. Для этого на этапе анализа компилятор строит несколько таблиц (рис.4.2), которые используются затем как при анализе, так и при синтезе [12].
При анализе программы из описаний, заголовков процедур, заголовков циклов и т.д. извлекается информация и сохраняется для последующего применения. Эта информация обнаруживается в отдельных точках программы и организуется так, чтобы к ней можно было обратиться из любой части компилятора. Например, при каждом использовании идентификатора необходимо знать, как был описан этот идентификатор и как он работал в других местах программы. Что конкретно следует хранить, зависит, конечно, от исходного языка, объектного языка и сложности компилятора. Но в каждом компиляторе в той или иной форме используется таблица символов (иногда ее называют списком идентификаторов или таблицей имен). Это таблица идентификаторов, встречающихся в исходной программе, вместе с их атрибутами. К атрибутам относятся тип идентификатора, его адрес в объектной программе и любая другая информация о нем, которая может понадобиться при генерации объектной программы.
Лексический анализатор (сканер) – самая простая часть компилятора. Сканер просматривает литеры исходной программы слева направо и строит символы программы – целые числа, идентификаторы, служебные слова и т. д. (символы передаются затем на обработку фактическому анализатору). На этой стадии может быть исключен комментарий. Сканер также может заносить идентификаторы в таблицу символов и выполнять другую простую работу, которая фактически не требует анализа исходной программы. Он может выполнить большую часть работы по макрогенерации в тех случаях, когда требуется только текстовая подстановка.
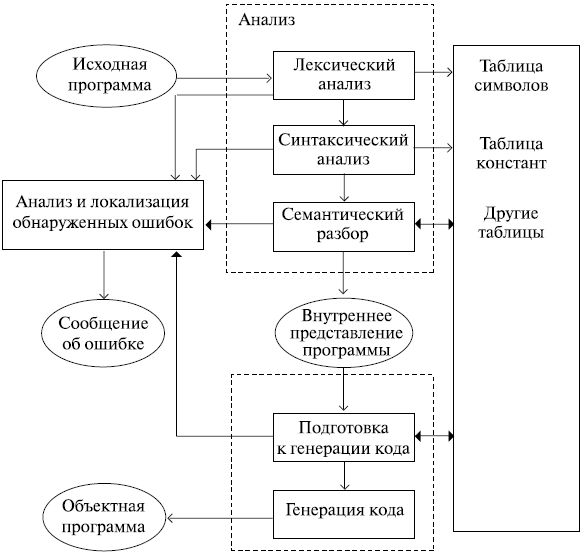
Рис. 4.2.Структура процесса компиляции
Обычно сканер передает символы анализатору во внутренней форме. Каждый разделитель (служебное слово, знак операции или знак пунктуации) будет представлен целым числом. Идентификаторы или константы можно представить парой чисел. Первое число, отличное от любого целого числа, использующегося для представления разделителя, характеризует сам "идентификатор" или "константу"; второе число является адресом или индексом идентификатора или константы в некоторой таблице. Это позволяет в остальных частях компилятора работать эффективно, оперируя с символами фиксированной длины, а не с цепочками литер переменной длины.
Синтаксический и семантический анализаторы выполняют сложную работу по расчленению исходной программы на составные части, формированию ее внутреннего представления и занесению информации в таблицу символов и другие таблицы. При этом также выполняется полный синтаксический и семантический контроль программы. Синтаксис – способ соединения слов (и их форм) в словосочетания и предложения. Семантика – это значения единиц языка. Обычный анализатор представляет собой синтаксически управляемую программу.
В действительности стремятся отделить синтаксис от семантики настолько, насколько это возможно. Когда синтаксический анализатор (распознаватель) узнает конструкцию исходного языка, он вызывает соответствующую семантическую процедуру, или семантическую программу, которая контролирует данную конструкцию с точки зрения семантики и затем запоминает информацию о ней в таблице символов или во внутреннем представлении программы. Например, когда распознается описание переменных, семантическая программа проверяет идентификаторы, указанные в этом описании, чтобы убедиться в том, что они не были описаны дважды, и заносит их вместе с атрибутами в таблицу символов.
Внутреннее представление исходной программы в значительной степени зависит от его дальнейшего использования. Это может быть дерево, отражающее синтаксис исходной программы. Это может быть исходная программа, в так называемой польской записи, список тетрад и т.д.
Перед генерацией команд обычно необходимо некоторым образом обработать и изменить внутреннюю программу. Кроме того, должна быть распределена память под переменные готовой программы. Одним из важных моментов на этом этапе является оптимизация программы с целью уменьшения времени ее работы. По существу, на этом этапе происходит перевод внутреннего представления исходной программы на автокод или на машинный язык. Это наиболее хлопотная и кропотливая часть компилятора, хотя и наиболее понятная. В интерпретаторе эта часть компилятора заменяется программой, которая фактически выполняет (или интерпретирует) внутреннее представление исходной программы. Само внутреннее представление в этом случае мало чем отличается от того, которое получается при компиляции.
Естественно, возникает вопрос: в чем заключаются главные трудности реализации компилятора? Сканер весьма прост и хорошо изучен. Синтаксические анализаторы, если речь идет о простых формальных языках, также довольно хорошо изучены. В действительности эту часть можно в значительной степени автоматизировать. С тех пор, как синтаксис был формализован, большинство исследований по созданию компиляторов касалось именно синтаксиса, а не семантики. Наиболее трудными и запутанными частями компилятора являются семантический анализ, программы подготовки генерации и программы генерации команд. Эти три части взаимозависимы, должны в значительной степени разрабатываться совместно и могут коренным образом измениться при переходе с одного объектного языка на другой или с одной машины на другую.
Более детальное представление о процессе компиляции можно получить в специальной литературе [12, 20, 21].
Дата добавления: 2015-02-25; просмотров: 1304;