Синхронизация типа critical
Директива определяет регион, который может быть выполнен лишь одним процессом-нитью.
#pragma omp critical [ name ] newline
structured_block
Описание:
- При выполнении критического региона нитью, все остальные (достигшие данной точки программы) ожидают ее завершения (рис.2.1.2.1.).
- Параметр name позволяет существовать нескольким критическим регионам:
- Имена выполняют роль глобальных идентификаторов (global identifiers). Различные регионы с тем же именем рассматриваются как один регион.
- Все CRITICAL регионы без имени рассматриваются как один и тот же регион.
Ограничения:
- Какие либо переходы недопустимы в/из блока critical
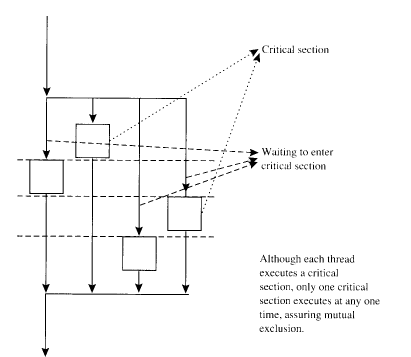
Рис.2.1.2.1.Схема выполнения критической секции
Пример. В параллельном регионе 8 нитей последовательно инкрементируют значение переменной x.
#include "stdafx.h"
#include "omp.h"
using namespace System;
int main()
{
int x;
x = 0;
#pragma omp parallel shared(x) num_threads(8)
{
#pragma omp critical
x = x + 1;
} /* end of parallel section */
Console::WriteLine(x.ToString());
}
Использование глобальных (неименованных) критических разделов может привести к снижению производительности, поскольку все потоки будут пытаться обратиться к одному и тому же критическому разделу кода. Поэтому в OpenMP предусмотрены именованные критические разделы, которые позволяют организовывать синхронизацию с повышенным уровнем детализации. Следовательно, блокировка раздела будет проведена только теми потоками, которым это действительно необходимо.
Пример. В примере определены две критических секции name1 и name2, каждая из которых выполняется только в одном из параллельных потоков-нитей.
#include <omp.h>
main()
{
int i, x1, x2;
…
#pragma omp parallel shared(x1, x2)
{
#pragma omp for
for(i = 1, i<n, i++)
{
…
if(condition1)
#pragma omp critical(name1)
x1 = x1 + 1;
else
#pragma omp critical(name1)
x1 = x1 - 1;
…
if(condition2)
#pragma omp critical(name2)
X2 = x2 + 1;
}
} /* end of parallel section */
}
Пример использования директивы для нахождения максимального значения: переменная max меняется последовательно каждой нитью.
#include "stdafx.h"
#include "omp.h"
#include "stdio.h"
#include <stdlib.h>
#define SIZE 10
…
void TestCritical()
{
int i;
int max;
int a[SIZE];
for (i = 0; i < SIZE; i++)
{
a[i] = rand();
printf_s("%d\n", a[i]);
}
max = a[0];
#pragma omp parallel for num_threads(4)
for (i = 1; i < SIZE; i++)
{
if (a[i] > max)
{
#pragma omp critical
{
// compare a[i] and max again because max
// could have been changed by another thread after
// the comparison outside the critical section
if (a[i] > max)
max = a[i];
}
}
}
printf_s("max = %d\n", max);
}Частые входы в критическую секцию могут существенно замедлить программу. Чтобы избежать этого, рекомендуется насколько возможно снижать число входов в критические секции. Так, рассмотрим вариант вышеописанного примера поиска максимума
| #pragma omp parallel for for ( i = 0 ; i < N; ++i ) { #pragma omp critical { if (arr[i] > max) max = arr[i]; } } |
Очевидно, что если вынести условие из критической секции, вход в нее будет производиться далеко не во всех итерациях цикла.
Поэтому более корректно будет использование (директива flush рассматривается в п.2.1.6):
| #pragma omp parallel for for ( i = 0 ; i < N; ++i ) { #pragma omp flush(max) if (arr[i] > max) { #pragma omp critical { if (arr[i] > max) max = arr[i]; } } } |
Такое простое исправление может существенно увеличить производительность вашего кода.
В приложении может быть несколько именованных критических разделов, причем все они могут выполняться одновременно. Необходимо отметить, что обработка вложенных критических разделов может создать условие для взаимной блокировки, которую OpenMP не сможет обнаружить. Поэтому при организации нескольких критических разделов будьте предельно внимательны с теми из них, которые расположены в теле подпрограмм.
Дата добавления: 2015-02-03; просмотров: 1010;