Эмуляция ассоциативного доступа в файловых системах
На первых ЭВМ данные хранились на ленте и записи извлекались и обрабатывались последовательно. В программах эти данные были организованы точно также как и на физическом носителе когда еще не существовало понятия логической структуры.
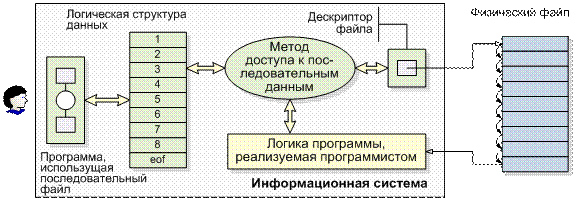
Поэтому при этом использовался самый простой способ локализации записи – сканирование файла до выявления требуемой записи. Для реализации данного способа доступа достаточно было знать начальный адрес файла (см. Рис. 1.3).
|
| Рис. 1.3 - Логическая и физическая структуры файлов с последовательным доступом |
Рассмотрим классический пример последовательного файла, содержащего записи о сотрудниках компании. Такой файл состоит из логических записей, в которых содержится информация об одном сотруднике. Каждая логическая запись делится на поля, такие как имя, адрес, идентификационный номер сотрудника и т.д.
Предположим, что такой файл используется для обработки платежной ведомости, т.е. в каждый период платежа файл необходимо обработать целиком. Так как при этом обрабатываются все записи, записи файла можно обрабатывать в любом порядке. Поэтому организовывается последовательный файл, состоящий из длинного списка записей, и обработка записей ведется последовательно от начала до конца. Для поддержки этого последовательного процесса записи в файле (т.е. на внешнем носителе) должны располагаться в том же порядке, что и в логической структуре данных, которой оперирует прикладная программа. Так как внешним носителем данных в нашем случае является магнитная лента, то такое ограничение легко выполнимо.
Неотъемлемой частью процесса обработки последовательного файла является определение конца файла, а для этого мы должны иметь возможность распознавать записи по какому-нибудь признаку. Логические записи распознаются, как правило, по одному полю в записи. Например, в файле сотрудников это может быть поле, содержащее идентификационный номер сотрудника. Такое поле называется ключевым. Ключом обычно является значение поля, расположенное в каждой записи в одной и той же позиции. Иногда бывает необходимо объединить несколько полей, чтобы обеспечить уникальность ключа, который в этом случае называется составным ключом. Эти понятия широко используются в СУБД и понадобятся нам в дальнейшем.
Во многих приложениях требуется идентифицировать записи по ключам, которые не являются уникальными (например, Фамилия, Имя, Отчество). Однако при этом все равно должен существовать один уникальный ключ, тот, который используется для размещения записи в файле и выборки ее из файла (например, в таблице СТУДЕНТЫ,- это номер зачетной книжки). Такой ключ называется первичным или идентификатором.
Таким образом, в случае обработки последовательного файла записи считываются одна за другой пока не будет достигнут конец файла, а обработанные записи в том же порядке заносятся на носитель.
Ограниченные возможности файловых систем последовательным доступом не помешали им быть эффективным средством для составления один или два раза в месяц счетов, платежных ведомостей и других отчетов. Обычно с такими файлами работали в пакетном режиме, то есть все записи файла обрабатывались за один раз, обычно ночью, после закрытия офиса.
Однако для выполнения большого количества рутинной работы требуется произвольный доступ – возможность напрямую обращаться к конкретной записи без предварительной сортировки файла или последовательного чтения всех записей. Поэтому при разработке сложных информационных систем нужно было найти способ организации ассоциативного доступа, т.е. доступа по содержанию. Это стало возможным после появления дисковых систем внешней памяти, обеспечивающих произвольный доступ к записям файлов, и разработки индексированных файлов.
Для создания индексированных файлов на основе ключей были реализованы специальные таблицы, переводящие ассоциативный запрос в соответствующий адрес. Эти таблицы были названы списками ссылок или индексами. Индекс определяется как таблица, с которой связана процедура, воспринимающая на входе информацию о значениях ключевых атрибутов и выдающая на выходе информацию, способствующую быстрой локализации записи, которая имеет заданные значения атрибутов.
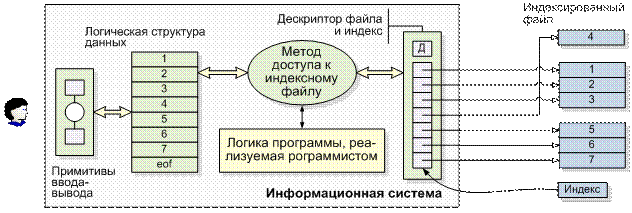
Таким образом, индекс содержит список ключевых значений, каждое из которых идентифицирует блок физических записей на внешнем носителе. Для этого в индексе вместе с ключами хранятся указатели, локализующие соответствующий блок записей на носителе данных. Чтобы найти определенный блок информации, сначала необходимо отыскать в индексе его ключ, а потом получить сам блок, который хранится по адресу, связанным с этим ключом. В качестве аналога индекса можно привести предметный указатель, размещаемый в конце книги. Понятие индекса широко используется в СУБД и понадобится нам в дальнейшем.
Индексы являются удобным инструментом для эффективного доступа к файлам, хранящимся на внешних носителях. Индекс обычно хранится на том же носителе, что и сам индексированный файл. Во время открытия файла индекс передается в оперативную память, чтобы к нему можно было легко обратиться, как только возникнет необходимость обратиться к индексированному файлу.
Классическим примером использования индексированного файла является обслуживание записей сотрудников. За счет создания индекса можно избежать длительных операций поиска для получения отдельной записи. В частности, если файл записей сотрудников индексирован по идентификационным номерам сотрудников, то определенную запись можно быстро получить, если этот номер известен (см. Рис. 1.4).
|
| Рис. 1.4 - Логическая и физическая структуры файлов с произвольным доступом |
На основе рассмотренных вариантов информационных систем, построенных на основе файловых систем, можно констатировать следующее:
– типовым программным обеспечением обработки данных в этих информационных системах являются методы доступа, а не методы управления данными;
– файловые системы, входящие в состав операционных систем, обеспечивают абстракцию файла для хранения этих записей.
Обратите внимание на то, что в индексных файлах идея использования данных для доступа получила дальнейшее развитие. Это и есть та основа, на которой в дальнейшем была разработана концепция баз данных.
Дата добавления: 2015-02-03; просмотров: 1132;