определена не определена
В то же время отсутствие статистически значимой связи не говорит об отсутствии причинно-следственных отношений, а заставляет искать другие пути и средства ее выявления, если содержательная концепция и практический опыт указывают на ее возможное существование.
Вторая процедура заключается в непосредственном расчете величины коэффициента корреляции по специальным математическим формулам. Сложность и громоздкость математической процедуры расчета не позволяет привести ее в кратком изложении в данной лекции, поэтому рассмотрим простой вариант нахождения коэффициента парной корреляции при помощи программы Excel.
Пример 1
Используя электронную таблицу Excel, определить значение коэффициента корреляции между двумя явлениями - преступность и безработица, представленными динамическими рядами за семилетний период (табл. 16).
1. Открыть программу Excel.
2. Ввести данные из таблицы 16.
3. Установить курсор в свободную ячейку, например в А4. В ней в дальнейшем отразится результат нашего расчета.
4. В панели инструментов включаем кнопку «Мастер функций» (fx).
Данные для нахождения коэффициента корреляции
| Периоды | |||||||
| Количество преступл. | |||||||
| Количество безработных |
Таблица 16
1. В окне мастера функций (рис.7) в левом поле «категория» выбираем категорию «статистическая». В правом поле соответственно отразятся все статистические функции.
2. Находим и выбираем в правом поле функцию КОРРЕЛ и нажимаем ОК.
3. В поле Массив 1 вносим координаты первого динамического ряда, который отражает динамику количества преступлений. В нашем примере это - В2:Н2. (рис. 7).
4. В поле Массив 2 вносим координаты второго динамического ряда, который отражает динамику количества безработных. В нашем примере это - ВЗ:НЗ (рис.7).
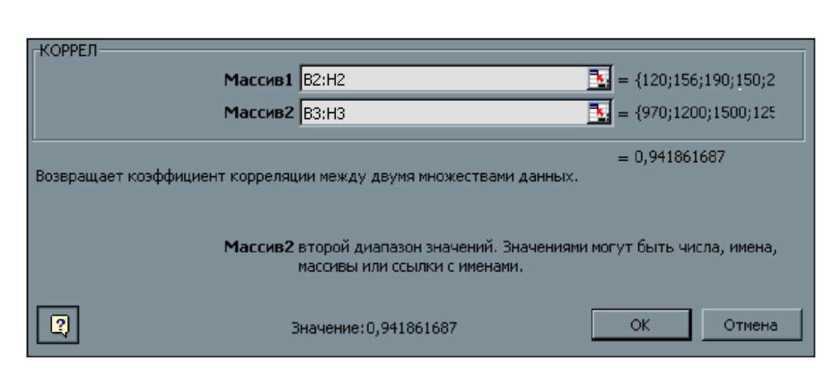
Рис. 7. Окноfxдля внесения координат динамических рядов
9. Нажимаем ОК. В ячейке, где вы установили курсор, должно появиться число 0,941862, отражающее силу взаимосвязи между явлениями (рис. 8).
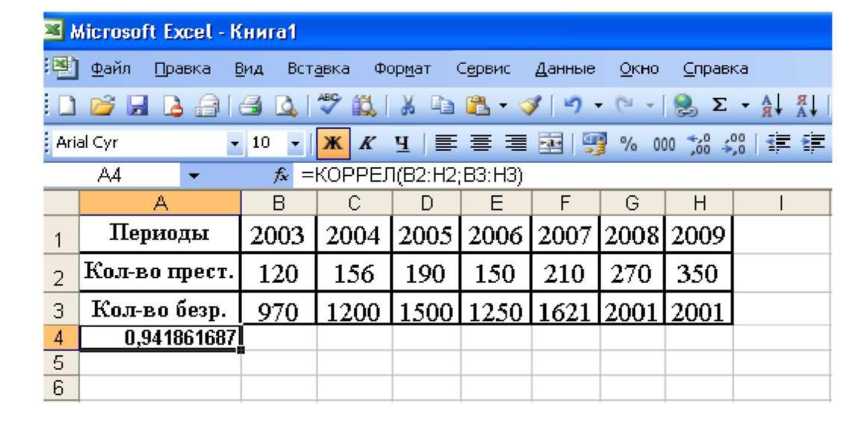
Рис.8. Окно программы Excel с результатами расчета коэффициента корреляции
В соответствии с предложенной выше классификацией коэффициентов парной корреляции теснота взаимосвязи между динамикой количества безработных и динамикой количества преступлений относится к категории очень сильной взаимосвязи. Такой вывод позволяет в дальнейшем уверенно подбирать математическую модель этой зависимости для целей прогнозирования.
Регрессионный анализ
Понятия корреляции и регрессии непосредственно связаны между собой. В корреляционном и регрессионном анализе много общих вычислительных приемов. Они используются для выявления причинно- следственных соотношений между явлениями и процессами. Однако, если корреляционный анализ позволяет оценить силу и направление стохастической связи, то регрессионный анализ - еще и функцию зависимости. При этом следует отметить, что чем слабее взаимосвязь, тем больше диаграмма рассеяния похожа на облако (рис.5) и тем труднее определить функцию зависимости.
Регрессия может быть:
а) в зависимости от числа явлений (переменных):
· простой (регрессия между двумя переменными);
· множественной (регрессия между зависимой переменной (у) и несколькими объясняющими ее переменными (х1 х2...хn );
б) в зависимости от формы:
· линейной (отображается линейной функцией, а между изучаемыми переменными существуют линейные соотношения (рис. 4, рис. 9));
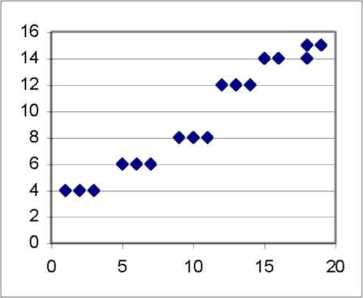
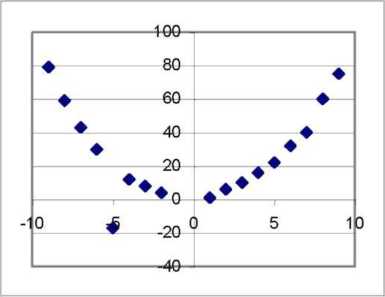
Рис. 9 Линейная зависимость Рис. 10. Нелинейная зависимость
· нелинейной (отображается нелинейной функцией, между изучаемыми переменными связь носит нелинейный характер, рис. 10);
в) по характеру связи между включенными в рассмотрение переменными:
· положительной (увеличение значения объясняющей переменной приводит к увеличению значения зависимой переменной и, наоборот);
· отрицательной (с увеличением значения объясняющей переменной значение объясняемой переменной уменьшается);
г) по типу:
· непосредственной (в этом случае причина оказывает прямое воздействие на следствие, т.е. зависимая и объясняющая переменные связаны непосредственно друг с другом);
· косвенной (объясняющая переменная оказывает опосредованное действие через третью или ряд других переменных на зависимую переменную);
· ложной (нонсенс-регрессия) - может возникнуть при поверхностном и формальном подходе к исследуемым процессам и явлениям. Например, регрессия, устанавливающая связь между уменьшением количества потребляемого алкоголя в нашей стране и уменьшением продажи стирального порошка.
При проведении регрессионного анализа решаются следующие основные задачи:
1. Определение формы зависимости (линейная, нелинейная).
2. Определение функции регрессии. Для этого подбирают математическое уравнение того или иного типа (технология подбора описана ниже), позволяющее, во-первых, установить общую тенденцию изменения
3. зависимой переменной, а, во-вторых, вычислить влияние объясняющей переменной (или нескольких переменных) на зависимую переменную.
4. Оценка неизвестных значений зависимой переменной. Полученная математическая зависимость (уравнение регрессии) позволяет определять значение зависимой переменной как в пределах интервала заданных значений объясняющих переменных, так и за его пределами. В последнем случае регрессионный анализ выступает в качестве полезного инструмента при прогнозировании изменений социально-правовых процессов и явлений (при условии сохранения существующих тенденций и взаимосвязей). Обычно длина временного отрезка, на который осуществляется прогнозирование, выбирается не более 1/3 интервала времени, на котором проведены наблюдения исходных показателей.
Можно осуществить как пассивный прогноз, решая задачу экстраполяции, так и активный, ведя рассуждения по известной схеме "если ..., то" и подставляя различные значения в одну или несколько объясняющих переменных регрессии.
Технология построения регрессии. Для построения регрессии используется специальный метод, получивший название метода наименьших квадратов. Суть его заключается в построении по фактическим данным динамического ряда теоретической кривой (тренда), точки которой находятся на минимально возможном расстоянии от точек динамического ряда (см. рис. 3).
При выборе модели регрессии одним из существенных требований к ней является возможность обеспечения наибольшей простоты, позволяющей получить решение с достаточной точностью. Поэтому для установления статистических связей вначале, как правило, рассматривают модель из класса линейных функций, затем другие.
Существует хорошо развитая система подбора аппроксимирующих функций - методика группового учета аргументов (МГУА), достаточно удачно реализованная в программе Excel.
О правильности подобранной модели молено судить по результатам исследования остатков ε, являющихся разностями между наблюдаемыми величинами 
и соответствующими прогнозируемыми с помощью регрессионного уравнения величинами  . В этом случае для проверки адекватности модели рассчитывается средняя ошибка аппроксимации:
. В этом случае для проверки адекватности модели рассчитывается средняя ошибка аппроксимации:
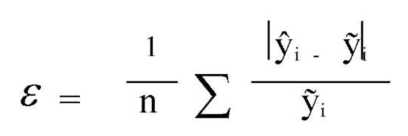
где i = 1 ... n
Модель считается адекватной, если ε не превышает 15%.
Рассмотрим технологию подбора модели регрессии на примере 3.
Пример 3
Используя электронную таблицу Excel, определите регрессионную зависимость (линию и уравнение регрессии) количества преступлений (зависимая переменная - у) от безработицы (объясняющая переменная - х) на основе данных, представленных в табл. 18.
1. Запустить программу Excel.
2. Ввести данные из таблицы 16 (рис.6) и выделить диапазон В2:Н3.
3. Поместить курсор в свободную ячейку (например, в А4).
4. Вызвать мастер диаграмм. В области "Тип:" выбрать "Точечная", а в области "Вид:" - "Точечная диаграмма со значениями, соединенными сглаживающими линиями" (вторая сверху). Нажать кнопку "Далее".
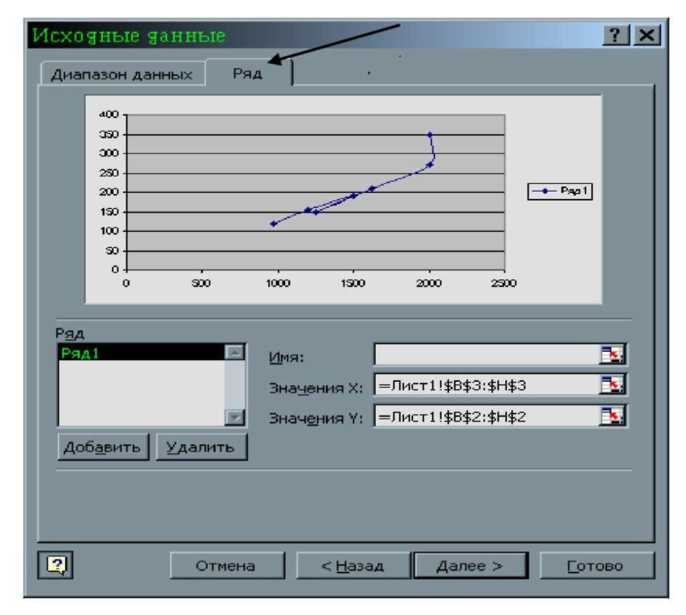
Рис. 11. Окно для ввода диапазонов ячеек с данными
5. В окне мастера диаграмм выбрать вкладку "Ряд” и нажать кнопку "Добавить ".
6. В поле "Значение X:" (рис.11) указать диапазон ячеек, содержащих данные о безработице - независимой переменной (в нашем случае это Лист1!$В$3:$Н$3), а в поле "Значение У:" указать диапазон ячеек, содержащих данные о преступности - зависимой переменной (в нашем случае это =Лист1!$В$2:$Н$2). Нажать кнопку "Готово". При этом на экране должна появиться диаграмма как на рис. 11. Технология ввода диапазона ячеек аналогична технологии ввода данных в массив1 и массив 2 при подсчете коэффициента корреляции.
7. Щелкнуть правой кнопкой мыши по линии диаграммы и в появившемся контекстном меню выбрать "Добавить линию тренда".
8. В появившемся окне оставить «по умолчанию» линейную модель и выбрать вкладку "Параметры". Установить флажок на "поместить на диаграмму величину достоверности аппроксимации (R˄2)". Нажать "ОК".
9. Запомнить (или записать в конспект) величину R2= 0,8871 для линейной модели.
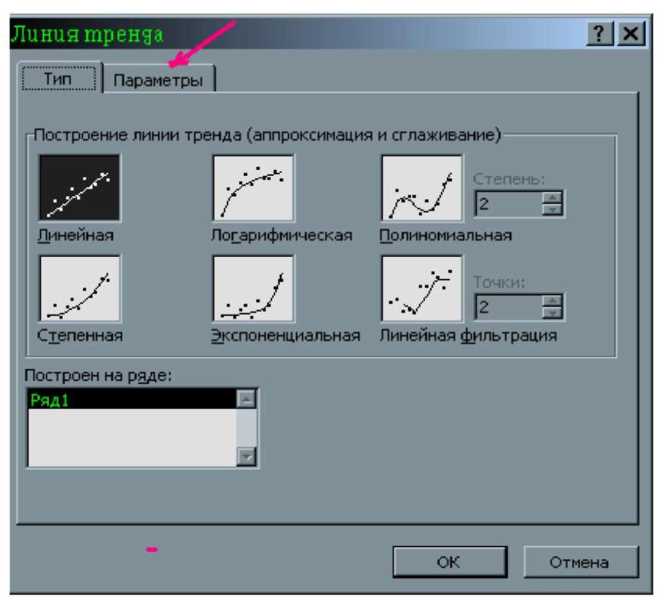
Рис. 12. Окно для выбора модели тренда
10. Щелкнуть правой кнопкой мыши по линии тренда (черная толстая линия) и в контекстном меню выбрать "Формат линии тренда". В появившемся окне выбрать вкладку "Тип”, а на ней выбрать следующий тип тренда - "Логарифмическая” к нажать “OK” (рис. 12).
11. Запомнить (записать) значение R2 = 0,8467 для логарифмической модели.
12. Повторить п.п. 10 и 11 для других типов тренда: "Полиномиальная" (по умолчанию применяется полином 2 степени), "Степенная" и "Экспоненциальная", за исключением "Линейная фильтрация".
13. Лучшим в нашем примере является тренд типа "Экспоненциальная", т.к. его величина R2 = 0,9519 является максимальной среди остальных.
Величина R2 является критерием выбора наилучшего типа тренда, наиболее подходящего к анализируемым данным. Чем ближе его значение приближается к 1, тем лучше выбранная модель тренда подходит для выражения тенденций исследуемых данных.
14. Полученное уравнение регрессии можно увидеть на диаграмме в верхнем правом углу (рис. 13). Уравнение имеет вид у = 50,169 е0.0009x
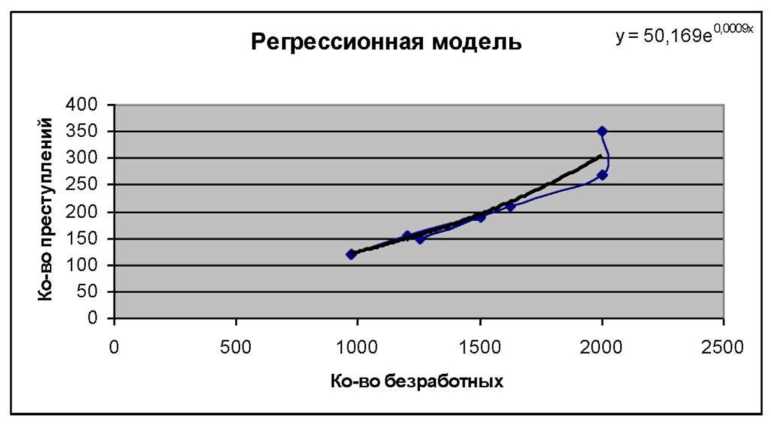
Рис. 13. Регрессионная модель зависимости между количеством безработных и количеством преступлений
Полученное уравнение регрессионной зависимости, можно использовать в дальнейшем для решения некоторых задач прогнозирования. Например, задавшись известным значением независимой переменной X (количество безработных) и подставив его в найденное уравнение регрессии, молено рассчитать неизвестное значение зависимой переменной - Y (количество преступлений).
Факторный анализ
Анализ функционирования социально-экономических систем сопряжен с необходимостью исследования значительного числа различных показателей. Однако многомерность описания может служить помехой, как при обработке исходных данных, так и при содержательной интерпретации полученных результатов. Построение корреляционных и регрессионных моделей "в лоб", когда число показателей достигает нескольких десятков, порой оказывается затруднительно. Поэтому возникает естественная необходимость в сжатии исходной информации, в замене исходных показателей на такие переменные, которые оказались бы наиболее информативными и отражающими существенные свойства изучаемого процесса. В дальнейшем изложении будем именовать такие переменные факторами.
В настоящее время факторный анализ широко используется при исследовании различных проблем:
· в экономике - для построения обобщенных показателей, для проведения типологии предприятий и агрегирования отраслей;
· в социологии - для классификации социальных объектов и изучения общественного мнения, в том числе для анализа качественных признаков;
· в экономической географии - в целях районирования, моделирования миграционных процессов, типологического исследования городов и др.
Методы факторного анализа широко применяются для исследования проблем, возникающих в сфере борьбы с преступностью.
Факторный анализ позволяет извлечь на поверхность некоторую величину (так называемый фактор), которая всегда стоит за наблюдаемыми величинами, но сама при этом для измерения остается недоступной.
Основная идея факторного анализа заключается в группировке с помощью специальных процедур множества исходных показателей в ограниченное число скрытых факторов. Подчеркнем, что термин "фактор" применяется в специфическом смысле. Если в общенаучном смысле фактором может быть назван любой признак какой-либо системы, то в факторном анализе под этим термином понимают внутренний, скрытый параметр системы, а наблюдаемые признаки лишь косвенно характеризуют тот или иной фактор.
Приведем несколько примеров, иллюстрирующих идею факторного анализа.
В социологических исследованиях при обследовании населения измеряемыми параметрами являются ответы на вопросы анкеты, а факторами, определяющими ответы анкетируемого, - такие не измеряемые характеристики, как социальный статус, культурный уровень, общественная активность анкетируемого и т.д.
Психологи, проводя свои исследования, фиксируют реакцию человека посредством тех или иных тестов. Факторами, которые определяют реакции испытуемого, являются, например, тренированность, темперамент, математические или художественные способности.
В социологии права факторами могут выступать правовая установка, уровень знания права, причины правонарушения и др.
Для формализации постановки задачи факторного анализа, как правило, делается допущение о линейной связи между измеренными параметрами и факторами. Нелинейные модели пока не получили широкого распространения в силу значительных вычислительных трудностей и сложности в интерпретации результатов в сравнении с линейными моделями. Таким образом, предполагается, что каждый из анализируемых признаков, параметров, характеризирующих тот или иной объект наблюдения, явление и т.п., может быть представлен следующей линейной формой:
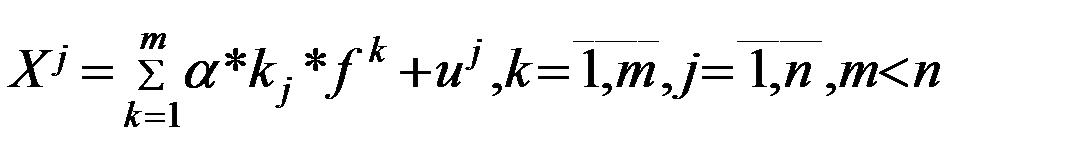
где a, kj - коэффициенты ("факторные нагрузки"), которые необходимо определить;
fk - обозначения факторов;
uj - "характерный фактор", изменение которого влияет на значение соответствующего параметра Xj.
Для определения общих факторов и соответствующих факторных нагрузок используется ряд методов. Наиболее широкую известность получили метод главных компонент и центроидный метод. Эти классические модели факторного анализа объединяет одна цель: определить общие факторы и факторные нагрузки таким образом, чтобы по ведение вычисленных параметров Xj было бы близко к поведению измеренных параметров Xj. Различие этих моделей определяется критериями близости.
Существует и другой подход к обработке эмпирических данных, основанный на анализе матрицы, элементами которой являются величины степени близости между измеренными параметрами. Результатом обработки такой матрицы может быть разбиение исходного множества параметров на непересекающиеся подмножества. При этом величины степени близости между параметрами, оказавшимися в одном подмножестве, заметно сильнее, чем между параметрами из разных подмножеств. Такой подход в отличие от классических методов факторного анализа позволяет использовать иной путь выявления существенных факторов: вначале осуществляется разбиение параметров на сильно связанные подмножества, а затем для каждого подмножества выделяется свой существенный фактор.
Факторный анализ имеет в своем арсенале различные методы, решающую роль, в выборе которых играют опыт исследователя, ресурсы ЭВМ и имеющееся программное обеспечение. Наиболее простым считается центроидный метод. Для научных исследований при наличии ЭВМ используют метод главных компонент.
Факторный анализ необходим не только для выявления действующих факторов и проведения оценки их значений; его результаты могут быть использованы и для проведения классификации различных объектов. Во многих социально-экономических задачах часто возникает необходимость разбиения исследуемых объектов на однородные группы. Такое разбиение значительно упрощает построение различных математических моделей и проведение дальнейших исследований.
При классификации объектов невольно возникает вопрос о том, какие и сколько наблюдаемых признаков необходимо включить в рассмотрение. На первый взгляд, может показаться, что чем больше таких признаков взято, тем точнее и лучше будут классифицированы исследуемые объекты. Однако однородные группы, построенные в пространстве большого числа признаков, могут оказаться неустойчивыми и плохо объяснимыми. В этом случае предварительно выявленные факторы с учетом значений их весов могут быть использованы для сравнения различных групп объектов и определения степени различия между ними.
Кластерный анализ
В социально-правовых исследованиях нередко возникает необходимость проведения классификации изучаемых объектов и выявления среди множества объектов группы с похожими свойствами. Задачи классификации неоднократно решались как у нас в стране, так и за рубежом при изучении территориальной дифференциации различных условий жизнедеятельности человека. Учет объектовых и территориальных неоднородностей необходим для выработки управленческих решений, для обоснования и принятия различных социально-экономических программ.
В отечественной научной литературе наиболее широко освещены вопросы территориальной дифференциации применительно к городским и сельским населенным пунктам. В зарубежных исследованиях большое внимание уделено проблемам типологии городов и населенных пунктов, районирования, типологического анализа в исследовании мировой экономики и международных отношений.
Перечень работ, посвященных социально-экономическим вопросам, достаточно обширен. Однако исследований, проведенных с использованием типологического подхода и посвященных проблемам совершенствования органов внутренних дел, сравнительно немного.
Необходимость классификации по сочетанию ряда признаков можно проиллюстрировать на примере исследования, посвященного проблеме безопасности дорожного движения, в котором была осуществлена необходимая типология крупных городов.
Простейшая классификация городов может быть осуществлена, например, по числу проживающих жителей или числу зарегистрированных транспортных средств, по числу дорожно-транспортных происшествий, имевших место за фиксированный отрезок времени, и т.д.. Однако такой упрощенный подход неприемлем, поскольку объектом изучения явилась безопасность дорожного движения в крупных городах - сложных целостных системах.
В общем виде задача кластерного анализа заключается в следующем. Используя данные, отражающие различные характеристики объектов, необходимо провести их разбиение на m однородных непересекающихся подмножеств (кластеров). При этом каждый объект Аi должен принадлежать только одному кластеру. Объекты, входящие в один и тот же кластер, должны быть сходными, а принадлежащие разным кластерам - разнородными.
Процедура кластерного анализа осуществляется ступенчато. Вначале объединяются в один кластер два наиболее "близко расположенных" объекта. Число исходных объектов уменьшается и становится равным n-1 (при этом один кластер содержит два объекта). Повторяя процесс объединения, можно последовательно получить множество кластеров, состоящее из n-2, n-3 кластеров и т.д.
Проведение описанных процедур с использованием методов факторного и кластерного анализов позволяет, во-первых, "сжать" пространство исходных показателей и выявить существенные внутренние характеристики-факторы, а во-вторых, проводить исследование на однородных группах изучаемых объектов, образованных по итогам многомерной классификации.
Дата добавления: 2018-06-28; просмотров: 509;