СИТУАЦИОННЫЙ АНАЛИЗ
Ни один метод прогнозирования не может обеспечить требуемого качества без установления начального состояния системы, в отношении которой строится прогноз. В некоторых случаях, когда в качестве объекта прогностической деятельности выступают системы, обладающие высокой устойчивостью паттернов поведения (например, организационно-технические системы, в сильной степени зависящие от состояния технологической компоненты, средствами которой осуществляется ее деятельность), задача прогнозирования может быть сведена к задаче точного установления ее текущего состояния.
Отнюдь не ко всем системам такой подход может быть применен без ограничений. Поведение системы определяется не только ее текущим состоянием, но и множеством других факторов — факторов внешнего происхождения (по отношению к исследуемой системе). Именно здесь и следует обратиться к понятию ситуации. Когда говорят о ситуационном анализе, речь идет не просто о текущем состоянии системы, но и о ситуации, в которой она находится.
Попытаемся определить содержание понятия «ситуация». В большинстве корректных употреблений этого слова его семантика связана с тремя понятиями «субъект», «действие» и «условия». Ситуация для кого-то ситуация «складывается», кто-то «создал» ситуацию и так далее... В то же время, в состоянии может пребывать и субъект и объект... Более того, состоянием субъект может управлять практически неограниченно, а вот ситуацией — только опосредованно, через среду и других субъектов. Большинство словарей определяет слово «ситуация», ставя его в один ряд со словами «обстоятельства», «обстановка», подчеркивая тот факт, что ситуация — это нечто внешнее по отношению к субъекту. Что же получается?

|
Ситуация — это состояние системы более высокого порядка, нежели данная, рассматриваемая. В отношении последней приемлемо употребление термина «состояние». Состояние и ситуация имеют различный временной масштаб. Ситуация является более протяженной во времени, нежели состояние и, в общем случае, имеет довлеющий над состоянием характер.
Поэтому в связи с решением задачи прогнозирования следует говорить о задачах распознавания состояний (применительно к объекту прогноза) и ситуаций (применительно к системе более высокого уровня, определяющей поведенческие особенности объекта прогноза). Но поскольку ситуация — это тоже состояние, но только состояние системы более высокого уровня, для краткости мы будем употреблять словосочетание «распознавание состояния», не делая акцента на уровне системы. По содержанию эти процедуры очень близки и отличаются только носителем состояния.
Качество решения задачи распознавания определяется тем, насколько качественно решена задача формализации признаков и критериев распознавания, и построения системы эталонов. Поскольку нам не дано иной альтернативы для снижения размерности задачи, речь идет о построении дискретной картины мира (тех его фрагментов, знание состояния которых важно для решения задачи) в виде формальных признаков. Более того, специфика большинства методов ситуационного анализа заключается, прежде всего, в том, каким способом осуществляется формализация признаков, и их выделение из общего потока данных. Один из подходов к решению задачи распознавания ситуаций излагается ниже.[116]
Ранее нами рассматривались различные способы представления и отображения данных (а значит, и способы задания эталонов для распознавания). Анализ кибернетического подхода к решению задачи распознавания образов позволил выдвинуть гипотезу о возможности применения технологии дискретного масштабирования образов, широко используемой в отношении графических объектов, к анализу ситуаций. Это становится возможным, поскольку ситуация с точки зрения кибернетики предстает в таком же дискретном виде, как и графические объекты при решении задачи распознавания. В отношении знаковых систем, с помощью которых человек выражает свои мысли, это утверждение тем более справедливо (знаки по своей природе дискретны). При распознавании графических образов достаточно широко используются методы прореживания точек в геометрическом пространстве. Когда же речь идет о распознавании ситуации, аналогичное прореживание возможно в некотором пространстве признаков, описывающих состояние некоторой системы.
Таким образом, переход от дискретного масштабирования образов объектов к дискретному масштабированию образов ситуаций вполне логичен. Автоматически возникают следующие вопросы: «Правомерно ли рассматривать множество признаков, как множество равно значимых для решения задачи распознавания элементов?», «Существуют ли пути автоматизации процесса прореживания точек в пространстве признаков?», «Как и какую метрику можно ввести в таком пространстве признаков?». Ответы на эти вопросы подсказывает все та же теория распознавания образов. Ответы, если расположить их по порядку, таковы: «Не правомерно», «Существуют (при специфической организации пространства признаков)», «Метрика должна вычисляться на основе анализа иерархии, упорядочивающей однотипные признаки». Иными словами, пространство признаков должно быть построено по иерархическому принципу, определяющему параметры алгоритма отсеивания менее информативных признаков. В этом случае процесс масштабирования эталона или образа ситуации до некоторого момента не будет приводить к потере существенных для распознавания черт ситуации. В области ситуационного анализа эти технологии, идеи которых были заложены еще в 1950-е, нашли применение лишь в конце 1980-х — начале 90-х годов.

|
При обработке изображений теория распознавания образов пошла дальше — с целью преодоления недостатков обычной растровой (построчной, поэлементной) дискретизации изображения были разработаны технологии векторизации контурных изображений по совокупности опорных точек. Это стало возможно благодаря дальнейшей математизации кибернетики и внедрению высокопроизводительной вычислительной техники. При использовании технологии векторизации контурное изображение, считываемое в режиме растрового сканирования, подвергается анализу с целью дальнейшего представления в виде совокупности фрагментов кривых, описывающихся примитивными функциями. Полученная в результате выполнения таких процедур совокупность математических описаний в дальнейшем позволяет осуществлять масштабирование контуров в обоих направлениях без потерь.
Но можно ли синтезировать подобные процедуры в отношении дискретного образа ситуации? Могут ли ситуации, представленные в виде знаковых моделей, построенных на основе текстов, быть описаны таким же образом? — Увы, нет — знаковые системы, используемые для описания ситуаций человеком (попросту — человеческая речь), устроены иначе, нежели числовой ряд, в котором между любыми двумя неравными числами, расположенными на числовой оси, если не налагаются особые ограничения, всегда может быть вставлено еще одно число. Любое слово или знак — это уже дискретный образ некоторого объекта, процесса или ситуации. Конечно, существуют способы параметризации отдельных терминов, но без введения строгой системы метризованных эталонов задачи сравнения решаются с очень низкой точностью (попробуйте определить размер «маленького румяного яблочка», описание которого встретилось в тексте, без знания того, что именно было взято в качестве эталона).
Но с другой стороны, мы уже рассматривали пример успешного снижения размерности задачи распознавания на примере метода А. Бертильона, продемонстрировавшего возможность идентификации лица по минимальному набору формальных признаков. Подобные методы могут быть использованы и в отношении ситуаций — задача состоит в том, чтобы синтезировать иерархическую систему признаков (терминов некоторого заданного уровня детализации), однозначно идентифицирующих ситуацию на заданном уровне иерархии описания (с заданной степенью точности). Создание такой системы позволяет успешно решать задачу классификации.
Исследование терминологической иерархии, лежащей в основе построения системы распознавания ситуации, позволяет выявить факт неполноты терминологии, неравной точности определений в соседних ветвях иерархии. При отсутствии терминов промежуточного уровня точности, требуемых для описания некоторой ситуации, в такой системе без порождения нового термина может быть синтезирован временный «терминологический портрет ситуации». Такой портрет представляет собой некоторую совокупность терминов, использование которых отличает данную разновидность ситуации от ей подобных. При накоплении статистики повторного появления терминологических портретов может быть выявлен факт устойчивой повторяемости таких терминологических портретов, чем может быть обоснована необходимость введения нового термина. Задачи такого типа часто встречаются в практике распознавания образов и носят название задач кластеризации. Таким образом, могут быть сформулированы достаточно строгие правила, регламентирующие момент и процедуру определения новых терминов. В принципе, совершенно необязательно, чтобы введенный термин был словом в общепринятом смысле — достаточно, чтобы существовала возможность его «декодирования» — такой подход легко может быть реализован в компьютерной системе распознавания. Другое дело, что таким же образом может быть установлен момент, когда возникает настоятельная потребность введения «полноценного» термина (удобопроизносимого и интуитивно понятного).
В качестве одного из алгоритмов построения текущего образа ситуации по материалам СМИ и иных источников информации, использующих для представления информации текстовые массивы, может быть использован статистический алгоритм анализа «повестки» дня, часа (а равно и любого другого временного интервала на протяжении которого оценивается частотно-ранговое распределение терминов в оперативных сообщениях — вспомним о Дж. Зипфе). При этом может фиксироваться как абсолютное значение «вектора», составленного из терминов равной частоты встречаемости, так и дифференциальный показатель, содержащий лишь изменения в составе вектора относительно взятого эталона. Подобные алгоритмы позволяют существенно усовершенствовать методы генерации словарей ключевых слов для фильтрации сообщений, релевантных текущей тематике сообщений, а при некотором их усовершенствовании могут быть использованы и для наглядного представления совокупности текстов, полученных за некоторый период.
Известно, что любое СМИ, пекущееся о своем рейтинге, осуществляет мониторинг сообщений открытых (и не только) источников информации в интересах выявления ситуаций, относящихся к важным «тематическим зонам». Пропуск важных для потребителя информационной продукции событий (а любое разумно построенное СМИ строит собственную модель потребителя) способен понизить рейтинг СМИ. Классическим подходом к решению этой задачи является подход, основанный на анализе поступающих сообщений с использованием перечня ключевых слов. Но ситуация меняется, а перечень ключевых слов всегда является неполным. Это вызвано хотя бы тем, что в оборот постоянно вводятся новые слова — например, в компьютерной области за месяц появляется в среднем порядка 300 новых терминов и устойчивых аббревиатур. Однако самой распространенной причиной пропуска информации из-за неполноты словаря является отсутствие возможности предусмотреть все возможные события, способные существенно повлиять на ситуацию.
Допустим, что некое СМИ отслеживает события, влияющие на финансовую ситуацию в США. Вполне вероятно, что, используя технологию отбора по ключевым словам, такое СМИ упустило бы из вида первые оперативные сообщения о террористической атаке на здания Всемирного Торгового Центра. Действительно, совершенно не очевидно, что слова «захват» и «авиалайнер» должны присутствовать в перечне ключевых слов автоматизированной системы отбора сообщений, релевантных финансовой тематике. Упоминания же о возможности наступления финансовых последствий для США (в которых наиболее вероятно появление «финансовой» терминологии) в связи с этими событиями появились значительно позже — в аналитических сообщениях. Используя же технологию пополнения словаря на основе анализа частотно-ранговых распределений слов и устойчивых словосочетаний, такое СМИ могло бы быстро отреагировать на изменение информационной обстановки (прежде, чем аналитик позаботится о внесении ключевого слова в словарь и снабдит его соответствующей интерпретантой).
Результат работы системы, использующей анализ потока сообщений для выявления повестки дня СМИ, может быть продемонстрирован на примере фрагмента карты семантических отношений для событий 11.09.2002.
Представленная на приводимом ниже рисунке карта семантических отношений получена с применением подхода, реализованного специалистами[117] из Лаборатории по исследованию проблем организации, коммуникации и познания (LOCKS) при университете штата Аризона (Arizona State University, США). Подход получил наименование Centering Resonance Analysis (CRA), основан на применении статистического аппарата для анализа интенсивности откликов прессы. Он позволяет выделить термины, релевантные основной тематике сообщений, и семантические связи между ними на основе анализа частотно-рангового распределения как отдельных слов, так и их устойчивых сочетаний.
Степень актуальности той или иной темы определяется частотой упоминания терминов, описывающих ее, при этом может быть задано ядро семантической сети, вокруг которого в некотором диапазоне частот размещаются термины, связанные с ним и релевантные тематике сообщений.
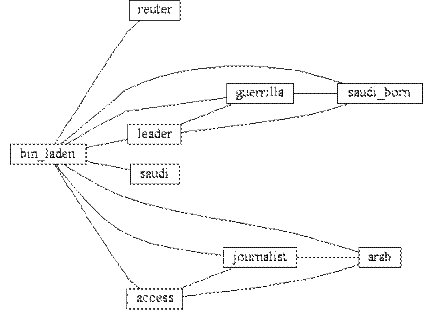
Рисунок 5.1 — Фрагмент карты семантических связей.
Как видим, метод CRA позволяет выделить основные слова, служащие для обозначения основных объектов внимания прессы, отследить семантические связи между ними и степень устойчивости этих связей. А значит, локализовать ту предметную область, в которой происходят значимые или целенаправленно акцентируемые события, перенастроить словари, используемые для осуществления фильтрации сообщений.
Использование аналогичных методов на этапе формирования словаря позволяет придать словарям ключевых слов динамические свойства, обеспечить их релевантность текущей ситуации. Кроме того, могут быть активизированы именно те группы эталонов, которые могут попасть в рабочее подмножество в ходе дальнейшего развития ситуации. То есть, может быть сокращена размерность задачи перебора массива эталонных моделей и предварительно определен уровень детализации эталонных описаний, который, скорее всего, будет превышен в ходе дальнейшего освещения в источниках развития ситуации.
Заметим, что свое применение методы управления поисковыми и «ключевыми» словарями на основе анализа статистических распределений могут найти не только в секторе СМИ, служб мониторинга социально-политической, криминальной и военной обстановки, но и при проведении масштабных научных исследований, а также в бизнесе и финансово-экономической сфере. Одним из очевидных приложений является анализ эффективности рекламных кампаний и иные задачи, сопряженные с анализом больших массивов текстовой информации. Некоторые элементы такой технологии могут быть использованы при выработке направлений инновационной политики при проведении анкетирования сотрудников предприятия (как это делается на японских предприятиях, когда работникам предлагается в свободной форме высказывать предложения и пожелания по совершенствованию системы управления и технологического процесса).
Дата добавления: 2017-04-20; просмотров: 646;