Записи, множества, файлы
Обобщением массива является комбинированный тип данных - запись, являющаяся неоднородной упорядоченной статической структурой прямого доступа. Запись есть набор именованных компонент - полей (часто разного типа), объединенных одним общим именем и идентифицируемых (адресуемых) с помощью как имени записи, так и имен полей, рис. 1.33.
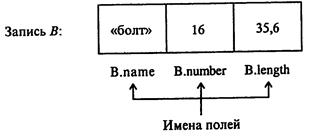
Рис. 1.33. Иллюстрация «записи».
Запись В состоит из трех полей, имеющих последовательно типы «текст», «целое число», «вещественное число»: 1-е поле - название детали, 2-е - условный номер по каталогу, 3-е - длина. При работе с одной единственной записью (что бывает нечасто), имя поля можно использовать как обычную переменную, т.е. можно изменять значение поля с помощью операции присваивания или любых других операций, доступных над величинами данного типа. Если же данная запись - лишь часть набора данных, то имя поля состоит из двух частей и называетсясоставным именем поля (на рис. 1.33 составные имена В. name, В. number, В. length).
Для облегчения работы с полями в различных языках программирования существуют средства, облегчающие их адресацию.
И записи, и массивы обладают одним общим свойством - произвольным доступом к компонентам. Записи более универсальны в том смысле, что для них не требуется идентичности типов их компонент. Массивы обеспечивают большую гибкость -индексы их компонент можно вычислять в отличие от имен полей записей.
Существенно иные возможности дает структура данных, моделирующая свойстваматематического объекта - множества.
Над множеством могут быть выполнены следующие операции:
1) объединение множеств (операция сложения '+');
2) пересечение множеств (операция умножения '*');
3) теоретико-множественная разность (вычитание множеств '-');
4) проверка принадлежности элемента множеству.
Различия между множеством и массивом очень существенны: размер множества заранее не оговаривается (хотя и ограничен компьютерной реализацией, например, 255), не существует иного способа доступа к элементам множества, кроме как проверкой принадлежности множеству.
Более сложной, чем рассмотренные выше из предусмотренных в современных системах программирования структур данных, является очередь (файл).
Понятие «файл» при всей своей привычности употребляется в информатике в нескольких не совсем совпадающих смыслах. Здесь мы остановимся лишь на представлении о файле как однородной упорядоченной динамической структуре последовательного доступа - очереди.
Очередь есть линейно упорядоченный набор следующих друг за другом компонент, доступ к которым происходит по следующим правилам:
1) новые компоненты могут добавляться лишь в хвост очереди;
2) значения компонент могут читаться (извлекаться) лишь в порядке следования компонент от головы к хвосту очереди.
Размер очереди заранее не оговаривается и теоретически может считаться бесконечным. Для запоминания (хранения) компонент очереди часто используют внешние запоминающие устройства большой емкости - магнитные диски и ленты. Отсюда другое название очереди - файл (по английски это слово имеет ряд значений, в том числе «картотека», «шеренга», «очередь»).
Исторически слово «файл» стало впервые применяться в информатике для обозначения последовательного набора каких-либо данных или команд (программа), хранящихся на внешнем запоминающем устройстве. Несколько позже были осознаны абстрактные, не зависящие от магнитных дисков и лент, свойства очереди как структуры данных, полезные при решении многих задач обработки - информации. Такой принцип извлечения и добавления компонент к очереди часто; называется «первым вошел - первым вышел» (английская аббревиатура - «FIFO»), рис. 1.34.
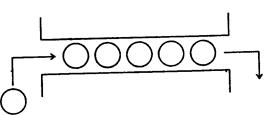
Рис. 1.34. Иллюстрация «очереди»
В языках программирования существуют и такие разновидности файлов, которые не подчиняются условию последовательности доступа к его компонентам (так называемые, файлы прямого доступа). Они уже не являются очередями.
Дата добавления: 2016-02-20; просмотров: 770;