Кодирование символов. Байт.
На основании одной ячейки информационной ёмкостью 1 бит можно закодировать только 2 различных состояния. Для того чтобы каждый символ, который можно ввести с клавиатуры в латинском регистре, получил свой уникальный двоичный код, требуется 7 бит. На основании последовательности из 7 бит, в соответствии с формулой Хартли, может быть получено N=27=128 различных комбинаций из нулей и единиц, т.е. двоичных кодов. Поставив в соответствие каждому символу его двоичный код, мы получим кодировочную таблицу. Человек оперирует символами, компьютер – их двоичными кодами.
Для латинской раскладки клавиатуры такая кодировочная таблица одна на весь мир, поэтому текст, набранный с использованием латинской раскладки, будет адекватно отображен на любом компьютере. Эта таблица носит название ASCII (American Standard Code of Information Interchange) по-английски произносится [э́ски], по-русски произносится [а́ски]. Ниже приводится вся таблица ASCII, коды в которой указаны в десятичном виде. По ней можно определить, что когда вы вводите с клавиатуры, скажем, символ “*”, компьютер его воспринимает как код 42(10), в свою очередь 42(10)=101010(2) – это и есть двоичный код символа “*”. Коды с 0 по 31 в этой таблице не задействованы.
Таблица 8.
Таблица символов ASCII
| код | символ | код | символ | код | символ | код | символ | код | символ | код | символ |
| Пробел | . | @ | P | ' | p | ||||||
| ! | A | Q | a | q | |||||||
| " | B | R | b | r | |||||||
| # | C | S | c | s | |||||||
| $ | D | T | d | t | |||||||
| % | E | U | e | u | |||||||
| & | F | V | f | v | |||||||
| ' | G | W | g | w | |||||||
| ( | H | X | h | x | |||||||
| ) | I | Y | i | y | |||||||
| * | J | Z | j | z | |||||||
| + | : | K | [ | k | { | ||||||
| , | ; | L | \ | l | | | ||||||
| - | < | M | ] | m | } | ||||||
| . | > | N | ^ | n | ~ | ||||||
| / | ? | O | _ | o | DEL |
Чтобы хранить также и коды национальных символов каждой страны (в нашем случае – символов кириллицы) требуется добавить еще 1 бит, что увеличит количество уникальных комбинаций из нулей и единиц вдвое, т.е. в нашем распоряжении дополнительно появится 128 свободных кодов (со 128-го по 255-й), в соответствие которым можно поставить символы русского алфавита.
Таким образом, отведя под хранение информации о коде каждого символа 8 бит, мы получим N=28=256 уникальных двоичных кодов, что достаточно, чтобы закодировать все символы, которые можно ввести с клавиатуры.
Так мы подошли к необходимости познакомиться с еще одной базовой единицей измерения – байтом.
Байт - последовательность из 8 бит.
1 байт = 23 бит = 8 бит.
На основании одного байта можно получить 28=256 уникальных двоичных кодов.
В современных кодировочных таблицах под хранение информации о коде каждого символа отводится 1 байт.
1 символ = 1 байт.
В байтах измеряется объем данных (V) при их хранении и передаче по каналам связи. Например, текст “Добрый день!” занимает объем равный 12 байтам.
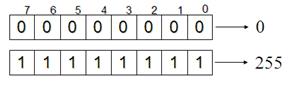
Биты в байте нумеруются с конца с 0-го по 7-й. Минимальная комбинация на основании одного байта – восемь нулей, максимальная – восемь единиц. Рис. 18а.
11111111(2)=27+26+25+24+23+22+21+20=128+64+32+16+8+4+2+1=255(10)
При хранении на физическом уровне каждый байт может быть реализован, например, на базе восьми конденсаторов, каждый из которых либо разряжен (0), либо заряжен (1). Рис. 18b.
| 
|
| Рис. 18а. Байт: минимальная и максимальная комбинации | Рис. 18b. Байт: соответствие двоичного числа и электрического импульса. |
Возвращаясь к кодировочным таблицам, заметим, что на сегодняшний день в использовании не одна, а несколько кодировочных таблиц, включающих коды кириллицы, – это стандарты, выработанные в разные годы и различными учреждениями. В этих таблицах различен порядок, в котором расположены друг за другом символы кирилличного алфавита, поэтому одному и тому же коду соответствуют разные символы. По этой причине, мы иногда сталкиваемся с текстами, которые состоят из русских букв, но в бессмысленной для нас последовательности.
Например, текст “Компьютерные вирусы”, введенный в кодировке Windows-1251 в кодировке КОИ-8 будет отображен так: ”лПНРШАФЕТОШЕ ЧЙТХУЩ”.
Таблица 9.
Несоответствие кодов символов в различных кодировках кириллицы.
| Код | Windows-1251 | КОИ-8 | ISO | Под национальные кодировки отданы коды с 128-го по 255-й. |
| А | ю | Р | ||
| Б | а | С | ||
| В | б | Т |
Эта проблема разрешима - на каждом компьютере найдутся все основные кодировочные таблицы, и если тест выглядит неадекватно, нужно попробовать перекодировать его, просто указав использовать другую кодировочную таблицу. Но наличие такой проблемы, конечно, вносит неудобства.
Используя 8-битную кодировочную таблицу мы не сможем адекватно увидеть на мониторе и тексты, созданные на тех языках, где используются символы, отличные от латинских и кирилличных, например символы с умляутами в немецком языке.
Дата добавления: 2015-10-21; просмотров: 800;