Классификация пользователей СУБД
Пользователей СУБД можно разделить на 3 большие группы.
Пользователи
Пользователей можно разделить на три большие группы.
• Первая —прикладные программисты, которые отвечают за написание прикладных программ, использующих базу данных. Прикладные программы выполняют над данными все стандартные операции: выборку существующей информации, вставку новой информации, удаление или обновление существующей информации. Все эти функции выполняются через соответствующий запрос к СУБД. Эти программы могут быть простыми программами пакетной обработки или оперативными приложениями, функция которых — поддержка работы конечного пользователя, имеющего непосредственный оперативный доступ к базе данных через рабочую станцию или терминал. Большинство современных приложений относится к оперативным.
• Вторая —конечные пользователи, которые работают с системами баз данных непосредственно через рабочую станцию или терминал. Конечный пользователь может получить доступ к базе данных, используя одно из оперативных приложений, упомянутых выше, или же воспользоваться интегрированным интерфейсом программного обеспечения самой системы баз данных. Такой интерфейс также поддерживается оперативным приложением, но это приложение не создается пользователем, оно являетсявстроенным в систему баз данных. В большинстве систем есть, по крайней мере, одно такое встроенное приложение, а именно:процессор языка запросов, который позволяет пользователю указывать команды или выражения высокого уровня (такие как select или insert) для данной СУБД. Язык SQL, упомянутый выше, — типичный пример языка запросов для базы данных.
Замечание. Общепринятый термин "язык запросов" не совсем точно отражает рассматриваемое понятие, поскольку слово "запрос" подразумевает лишь выборку, в то время как с помощью этого языка выполняются также операции обновления, вставки и удаления (а возможно, и многие другие).
Кроме языка запросов, в большинстве систем также предоставляются дополнительные встроенные интерфейсы, в которых пользователь в явном виде не использует команд, таких как select. Для работы с базой данной пользователь, например, выбирает необходимые команды меню или заполняет поля в формах. Такие интерфейсы, основанные на меню и формах, облегчают работу с базами данных тем, кто не имеет опыта работы с информационными технологиями (ИТ; часто употребляется также сокращение ИС — информационные системы, эти понятия практически эквивалентны). Командныйинтерфейс, т.е. язык запросов, напротив, требует некоторого опыта работы с ИТ (возможно, не очень большого). Однако командный интерфейс обычно более гибок, чем основанный на меню и формах; кроме того, в языках запросов обычно есть определенные функции, которые не поддерживаются интерфейсами, основанными на меню и формах.
• Третья группа —администраторы базы данных, илиАБД.
Рассмотрим более подробно концепцию централизованного управления. Предполагается, что при централизованном управлении на предприятии, использующем систему баз данных, есть человек, который несет основную ответственность за данные предприятия. Этоадминистратор данных, или АД, упомянутый ранее в этой главе. В связи с тем, что данные (как отмечено выше) — одна из главных ценностей предприятия, администратор должен разбираться в данных и понимать нужды предприятия по отношению к данным на уровне управления высшего руководства предприятием. Таким образом, в обязанности администратора данных входит: принимать решение, какие данные необходимо вносить в базу данных в первую очередь, а также обеспечивать поддержание порядка при обслуживании данных и использовании их после занесения в базу данных. Например, он должен указывать, кто, при каких условиях, над какими данными и какие операции может выполнять. Другими словами, он должен обеспечивать безопасность данных.
Очень важно, чтобы администратор данных работал как управляющий, а не как специалист по техническим вопросам (хотя он, конечно, должен иметь хорошее представление о возможностях баз данных на техническом уровне). Технический специалист, ответственный за реализацию решений администратора данных, — этоадминистратор базы данных,илиАБД. Итак, администратор базы данных, в отличие от администратора данных, должен быть профессиональным специалистом в области информационных технологий. Работа АБД заключается в создании самих баз данных и техническом контроле, необходимом для осуществления решений администратора данных. АБД также несет ответственность за обеспечение необходимого быстродействия системы и ее технического обслуживания. Обычно у АБД есть штат из системных программистов и технических ассистентов (т.е. на практике функции АБД выполняются командой из нескольких человек, а не одним служащим). Однако для простоты удобно считать, что администратор базы данных — один человек.
Лекция 2. Инфологическая модель данных «Сущность-связь»
Объединяя частные представления о содержимом базы данных, полученные в результате опроса пользователей, и свои представления о данных, которые могут потребоваться в будущих приложениях, АБД сначала создает обобщенное неформальное описание создаваемой базы данных. Это описание, выполненное с использованием естественного языка, математических формул, таблиц, графиков и других средств, понятных всем людям, работающих над проектированием базы данных, называют инфологической моделью данных (рис. 2.1).
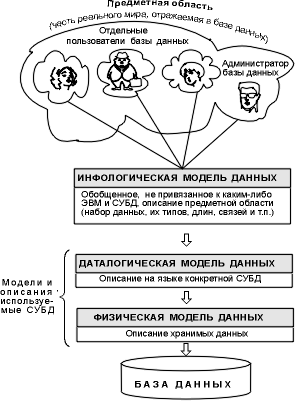
Рис. 2.1. Уровни моделей данных
Такая человеко-ориентированная модель полностью независима от физических параметров среды хранения данных. В конце концов этой средой может быть память человека, а не ЭВМ. Поэтому инфологическая модель не должна изменяться до тех пор, пока какие-то изменения в реальном мире не потребуют изменения в ней некоторого определения, чтобы эта модель продолжала отражать предметную область.
Остальные модели, показанные на рис. 2.1, являются компьютеро-ориентированными. С их помощью СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным лишь по их именам, не заботясь о физическом расположении этих данных. Нужные данные отыскиваются СУБД на внешних запоминающих устройствах по физической модели данных.
Так как указанный доступ осуществляется с помощью конкретной СУБД, то модели должны быть описаны на языке описания данных этой СУБД. Такое описание, создаваемое АБД по инфологической модели данных, называют даталогической моделью данных.
Трехуровневая архитектура (инфологический, даталогический и физический уровни) позволяет обеспечить независимость хранимых данных от использующих их программ. АБД может при необходимости переписать хранимые данные на другие носители информации и (или) реорганизовать их физическую структуру, изменив лишь физическую модель данных. АБД может подключить к системе любое число новых пользователей (новых приложений), дополнив, если надо, даталогическую модель. Указанные изменения физической и даталогической моделей не будут замечены существующими пользователями системы (окажутся "прозрачными" для них), так же как не будут замечены и новые пользователи. Следовательно, независимость данных обеспечивает возможность развития системы баз данных без разрушения существующих приложений.
Инфологическая модель отображает реальный мир в некоторые понятные человеку концепции, полностью независимые от параметров среды хранения данных. Существует множество подходов к построению таких моделей: графовые модели, семантические сети, модель "сущность-связь" и т.д. Наиболее популярной из них оказалась модель "сущность-связь".
Основные понятия
Цель инфологического моделирования – обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных. Поэтому инфологическую модель данных пытаются строить по аналогии с естественным языком (последний не может быть использован в чистом виде из-за сложности компьютерной обработки текстов и неоднозначности любого естественного языка). Основными конструктивными элементами инфологических моделей являются сущности, связи между ними и их свойства (атрибуты).
Сущность – любой различимый объект (объект, который мы можем отличить от другого), информацию о котором необходимо хранить в базе данных. Сущностями могут быть люди, места, самолеты, рейсы, вкус, цвет и т.д. Необходимо различать такие понятия, как тип сущности и экземпляр сущности. Понятие тип сущности относится к набору однородных объектов выступающих как целое. Экземпляр сущности относится к конкретной вещи в наборе. Например, типом сущности может быть ГОРОД, а экземпляром – Москва, Киев и т.д.
Атрибут – поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей (например, ЦВЕТ может быть определен для многих сущностей: СОБАКА, АВТОМОБИЛЬ, ДЫМ и т.д.). Атрибуты используются для определения того, какая информация должна быть собрана о сущности. Примерами атрибутов для сущности АВТОМОБИЛЬ являются ТИП, МАРКА, НОМЕРНОЙ ЗНАК, ЦВЕТ и т.д. Здесь также существует различие между типом и экземпляром. Тип атрибута ЦВЕТ имеет много экземпляров или значений:
Красный, Синий, Банановый, Белая ночь и т.д.,
однако каждому экземпляру сущности присваивается только одно значение атрибута.
Абсолютное различие между типами сущностей и атрибутами отсутствует. Атрибут является таковым только в связи с типом сущности. В другом контексте атрибут может выступать как самостоятельная сущность. Например, для автомобильного завода цвет – это только атрибут продукта производства, а для лакокрасочной фабрики цвет – тип сущности.
Ключ – минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся.
Связь – ассоциирование двух или более сущностей. Если бы назначением базы данных было только хранение отдельных, не связанных между собой данных, то ее структура могла бы быть очень простой. Однако одно из основных требований к организации базы данных – это обеспечение возможности отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи. А так как в реальных базах данных нередко содержатся сотни или даже тысячи сущностей, то теоретически между ними может быть установлено более миллиона связей. Наличие такого множества связей и определяет сложность инфологических моделей.
Дата добавления: 2015-02-10; просмотров: 7420;