История развития систем управления базами данных



25. Пример применения формулы Полячека-Хинчина для системы М/Н2/1
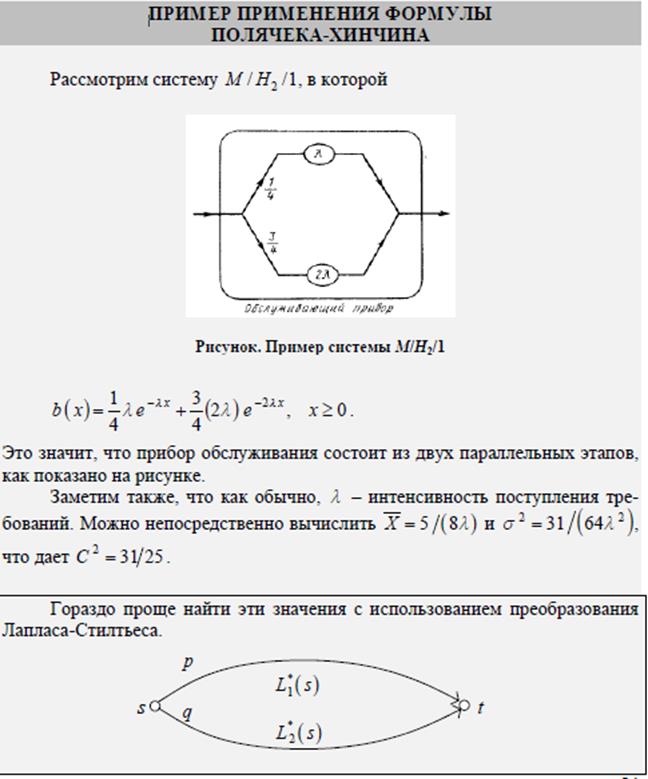

[1] Здесь и далее для простоты мы будем приближенные равенства, становящиеся точными при  писать просто как равенства, не оговаривая их приближенность.
писать просто как равенства, не оговаривая их приближенность.
Основные понятия системы баз данных
Информационная система (ИС) – система, реализующая автоматизированный сбор, обработку и манипулирование информацией и включающая в себя технические средства, программное обеспечение и персонал. Автоматическая ИС не использует участие человека. Автоматизированной участие человека необходимо. Основой любой информационной системы является база данных.
Цель любой информационной системы - обработка данных об объектах реального мира. Основой информационной системы является база данных как совокупность сведений о конкретных объектах реального мира в какой-либо предметной области. Под предметной областьюпринято понимать часть реального мира, подлежащего изучению для организации управления.
Объектом называется элемент предметной области, информацию о котором мы сохраняем.
База данных (БД) - это поименованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области. В современной технологии баз данных предполагается, что создание базы данных, ее поддержка и обеспечение доступа пользователей к ней осуществляются централизованно с помощью специального программного инструментария - системы управлении базами данных.
Система управления базами данных (СУБД) -это комплекс программных и языковых средств, предназначенных для создания, ведения и совместного применения баз данных многими пользователями.
История развития систем управления базами данных
Важным этапом развития ИС явился переход к использованию централизованных систем управления файлами. Широкое распространение получили индексированные файлы. Файл является простым набором записей (record), которые содержат логически связанные данные. Каждая запись содержит логически связанный набор из одного или нескольких полей (field), каждое из которых представляет некоторую характеристику моделируемого объекта. С точки зрения прикладной программы файл – именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные.
Недостатки файловых систем:
1. Изоляция данных. При изолированных файлах возрастает время доступа к данным и возникают трудности извлечения данных из двух и более файлов.
2. Зависимость от данных. Физическая структура и способ хранения записей файлов данных жестко зафиксированы в коде приложения, что приводит к сложности изменения существующей структуры данных.
3. Несовместимость формата данных. Структура файлов определяется кодом приложения, следовательно, зависит от языка программирования этого приложения. Несовместимость файлов, написанных на различных языках программирования, затрудняет процесс их совместной обработки.
4. Дублирование данных. Из-за децентрализованной работы с данными в файловой системе допускается бесконтрольное дублирование данных, что приводит не только к неэкономному расходованию ресурсов, но и к нарушению целостности данных и, как следствие, противоречивости хранящихся данных.
5. Невозможность многопользовательского режима работы.
Эти недостатки послужили причиной разработки нового подхода к управлению информацией. Разработаны системы управления базами данных (СУБД).
К СУБД первого поколения можно отнести системы, основанные на инвертированных списках, иерархические и сетевые системы управления базами данных.
Инвертированные списки представляют собой список таблиц и список индексов, позволяющих осуществлять доступ к данным, хранимым в таблицах.
Общие правила определения целостности в системах на основе инвертированных списков отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу. С помощью индексов осуществляется поиск по вторичному ключу. БД, организованная с помощью инвертированных списков, похожа на реляционную, но с тем различием, что индексы доступны.
В 1968 году появилась первая версия базы данных Information Management System (IMS) фирмы IBM. Применяемая структура, напоминала перевернутое дерево и была названа иерархической структурой.
Другим заметным достижением середины 1960-х годов было появление системы IDS (Integrated Data Store) фирмы General Electric. Развитие этой системы привело к созданию нового типа систем управления базами данных — сетевых СУБД. Сетевая СУБД создавалась для представления более сложных взаимосвязей между данными, чем те, которые можно было моделировать с помощью иерархических структур, а также для формирования стандарта баз данных. В 1971 году для утверждения Национальным институтом стандартизации США (American National Standards Institute — ANSI), группой DBTG был представлен стандарт баз данных, содержаий три компонента:
· Сетевая схема — это логическая организация всей базы данных в целом (с точки зрения АБД), которая включает определение имени базы данных, типа каждой записи и компонентов записей каждого типа.
· Подсхема — это часть базы данных, как она видится пользователями или приложениями.
· Язык управления данными — инструмент для определения характеристики структуры данных, а также для управления ими.
Той же группой DBTG было предложено стандартизировать три языка:
· Язык определения данных для схемы (Data Definition Language — DDL), который позволяет администраторам баз данных ее описать.
· Язык определения данных для подсхемы (также DDL), который позволяет определять в приложениях те части базы данных, доступ к которым будет необходим.
· Язык манипулирования данными (Data Manipulation Language — DML), предназначенный для управления данными.
Несмотря на то что этот отчет официально не был утвержден Национальным институтом стандартизации США (American National Standards Institute — ANSI), большое количество систем было разработано в полном соответствии с этими предложениями группы DBTG.
Всем СУБД первого поколения присущи следующие достоинства:
· Развитые средства управления данными во внешней памяти на низком уровне.
· Возможность построения вручную эффективных прикладных систем.
· Возможность экономии памяти за счет разделения подобъектов (в сетевых системах).
Всем СУБД первого поколения присущи перечисленные ниже недостатки:
· Даже для выполнения простых запросов с использованием переходов и доступов к определенным записям необходимо создавать достаточно сложные программы.
· Независимость от данных существует лишь в минимальной степени.
· Отсутствие общепризнанных теоретических основ.
В 1970 году Э. Ф. Кодд (Е. F. Codd), работавший в исследовательской лаборатории корпорации IBM, опубликовал статью о реляционной модели данных, позволявшей устранить недостатки прежних моделей. Вслед за этим появилось множество экспериментальных реляционных СУБД, а первые коммерческие продукты появились в 1970-1980-х годах. Корпорацией IBM, расположенной в городе Сан-Хосе, штат Калифорния, созданной в конце 1970-х годов, был задуман проект с целью доказать практичность реляционной модели, что достигалось посредством реализации предусмотренных ею структур данных и требуемых функциональных возможностей. На основе этого проекта были получены важнейшие результаты.
· Был разработан структурированный язык запросов SQL, который с тех пор стал стандартным языком любых реляционных СУБД.
· В 1980-х годах были созданы различные коммерческие реляционные СУБД — например DB2 или SQL/DS корпорации IBM или Oracle корпорации Oracle Corporation.
В настоящее время существует несколько сотен различных реляционных СУБД. В качестве примеров многопользовательских СУБД могут служить система INGRES II фирмы Computer Associates и система Informix фирмы Informix Software, Inc. Примерами реляционных СУБД для персональных компьютеров являются Access и FoxPro фирмы Microsoft, Paradox фирмы Corel Corporation, InterBase и BDE iupMbi Borland, а также R:Base фирмы R:Base Technologies. Реляционные СУБД относятся к СУБД второго поколения.
Однако реляционная модель обладает также некоторыми недостатками, в частности ограниченными возможностями моделирования. Для решения этой проблемы был выполнен большой объем исследовательской работы. В 1976 году Питер Чен) предложил модель "сущность-связь" (Entity-Relationship model — ER-модель), которая в настоящее время стала самой распространенной технологией проектирования баз данных и является основой методологии. В 1979 году Кодд сделал попытку устранить недостатки собственной основополагающей работы и опубликовал расширенную версию реляционной модели — RM/T (1979), затем еще одну версию — RM/V2 (1990). Попытки создания модели данных, позволяющей более точно описывать реальный мир, неформально называют семантическим моделированием данных (semantic data modeling).
В ответ на все возрастающую сложность приложений баз данных появились две новые системы: объектно-ориентированные СУБД, или ООСУБД (Object-Driented DBMS — OODBMS), и объектно-реляционные СУБД, или ОРСУБД Object-Relational DBMS — ORDBMS). Однако в отличие от предыдущих моделей действительная структура этих моделей не совсем ясна. Попытки реализации подобных моделей представляют собой СУБД третьего поколения.
Дата добавления: 2015-01-19; просмотров: 1491;