Регрессионный анализ. 5 страница
Рассмотрим матрицу 23, полученную из матрицы 22 обычным способом: два раза повторен план 22, причем в первых четырех опытах x3 имеет верхнее значение, а в последних четырех опытах – нижнее значение. Допустим, что экспериментатор может поставить в первый день четыре опыта и во второй день также четыре опыта.
Таблица 4.13 - Матрица планирования 23 с ошибкой
| № опыта | x1 | x2 | x3 | y |
| + | + | + | y1+ε | |
| - | + | + | y2+ε | |
| + | - | + | y3+ε | |
| - | - | + | y4+ε | |
| + | + | - | Y5 | |
| - | + | - | Y6 | |
| + | - | - | Y7 | |
| - | - | - | Y8 |
Можно ли опыты ставить подряд и в первый день реализовать опыты № 1, 2, 3 и 4, а во второй – 5, 6, 7 и 8? Ставя опыты подряд, вы разбиваете матрицу на две части или на два блока: в первый блок – входят опыты № 1, 2, 3 и 4, во второй – № 5, 6, 7 и 8. Если внешние условия первого дня каким-то образом отличались от внешних условий второго дня, то это способствовало возникновению некоторой систематической ошибки. Обозначим эту ошибку ε. Тогда четыре значения параметра оптимизации сдвинуты на величину ε по сравнению с истинными значениями. Пусть это будут параметры, входящие в первый блок: y1+ε, y2+ε, y3+ε, y4+ε. Однако матрица построена так, что в первом блоке значения х3 находятся на верхнем уровне, а во втором – на нижнем уровне. Тогда при подсчете b3 получится следующая картина:
b3= 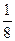 [(y1+ε)+(y2+ε)+(y3+ε)+(y4+ε)–y5–y6–y7–y8]→β3+
[(y1+ε)+(y2+ε)+(y3+ε)+(y4+ε)–y5–y6–y7–y8]→β3+ 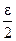 . (4.41)
. (4.41)
где β3 – истинное значение коэффициента при х3.
Таким образом, возможное различие во внешних условиях смешалось с величиной линейного коэффициента b3 и исказило это значение. В такой последовательности опыты ставить нельзя. Опыты нужно рандомизировать во времени, т.е. придать последовательности опытов случайный характер.
|
|
Приведем простой пример рандомизации условий эксперимента. В полном факторном эксперименте 23 предполагается каждое значение параметра оптимизации определять по двум параллельным опытам. Нужно случайно расположить всего 16 опытов. Присвоим параллельным опытам номера с 9 по 16, и тогда опыт № 9 будет повторным по отношению к первому опыту, десятый – ко второму и т. д. Следующий этап рандомизации – использование таблицы случайных чисел. Обычно таблица случайных чисел приводится в руководствах по математической статистике. В случайном месте таблицы выписываются числа с 1 по 16 с отбрасыванием чисел больше 16 и уже выписанных. В нашем случае, начиная с четвертого столбца, можно получить такую последовательность:
2; 15; 9; 5; 12; 14; 8; 13; 16; 1; 3; 7; 4; 6; 11; 10.
Это значит, что первым реализуется опыт № 2, вторым – опыт № 7 и т.д. Выбранную случайным образом последовательность опытов не рекомендуется нарушать.
4.9 Обработка результатов эксперимента
Тщательное, скрупулезное выполнение эксперимента, несомненно, является главным условием успеха исследования. Это общее правило, и планирование эксперимента не относится к исключениям.
Однако нам не безразлично, как обработать полученные данные. Мы хотим навлечь из них всю информацию и сделать соответствующие выводы. Как всегда, мы находимся между Сциллой и Харибдой. С одной стороны, не извлечь из эксперимента все, что из него следует,– значит пренебречь нелегким трудом экспериментатора. С другой стороны, сделать утверждения, не следующие из эксперимента, – значит создавать иллюзии, заниматься самообманом.
Статистические методы обработки результатов позволяют нам не перейти разумной меры риска.
4.9.1 Метод наименьших квадратов.
Начнем с простого случая: один фактор, линейная модель. Интересующая нас функция отклика (которую мы будем также называть уравнением регрессии) имеет вид уравнения (4.42).
y = b0 + b1x1. (4.42)
Это хорошо известное уравнение прямой линии. Наша цель – вычисление неизвестных коэффициентов b0 и b1. Мы провели эксперимент, чтобы использовать при вычислениях его результаты. Как это сделать наилучшим образом?
Если бы все экспериментальные точки лежали строго на прямой линии, то для каждой из них было бы справедливо равенство (4.43)
y - b0 - b1x1i = 0, (4.43)
где i = 1, 2, ..., N – номер опыта. Тогда не было бы никакой проблемы. На практике это равенство нарушается и вместо него приходится писать
yi - b0 - b1x1i = ξi, (4.44)
где ξ – разность между экспериментальным и вычисленным по уравнению регрессии значениями y в i-й экспериментальной точке. Эту величину иногда невязкой.
Мы хотим найти такие коэффициенты регрессии, при которых невязки будут минимальны. Это требование можно записать по-разному. В зависимости от этого мы будем получать разные оценки коэффициентов. Уравнение (4.45) - одна из возможных записей, которая приводит к методу наименьших квадратов.
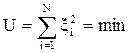 . (4.45)
. (4.45)
Когда мы ставим эксперимент, то обычно стремимся провести больше (во всяком случае не меньше) опытов, чем число неизвестных коэффициентов. Поэтому система линейных уравнений (4.44) оказывается переопределенной и часто противоречивой (т. е. она может иметь бесконечно много решений или может не иметь решений). Переопределенность возникает, когда число уравнений больше числа неизвестных; противоречивость – когда некоторые из уравнений несовместимы друг с другом.
Только если все экспериментальные точки лежат па прямой, то система становится определенной и имеет единственное решение.
МНК обладает тем замечательным свойством, что он делает определенной любую, произвольную систему уравнений. Он делает число уравнений равным числу неизвестных коэффициентов.
Для определения двух неизвестных коэффициентов требуется два уравнения. Давайте попробуем их получить.
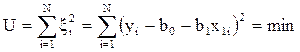 . (4.46)
. (4.46)
Минимум некоторой функции, если он существует, достигается при одновременном равенстве нулю частных производных по всей неизвестным, т. е.
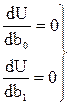 . (4.47)
. (4.47)
В явном виде это запишется как
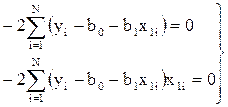 ,
, 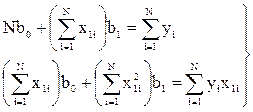 .
.
Окончательные формулы для вычисления коэффициентов регрессии, которые удобно находить с помощью определителей, имеют вид
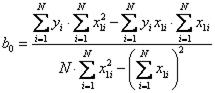 , (4.48)
, (4.48)
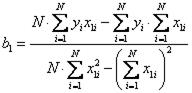
Величина U называется остаточной суммой квадратов
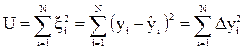 , (4.49)
, (4.49)
где 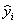 – значение параметра оптимизации, вычисленное из уравнения регрессии). МНК гарантирует, что эта величина минимально возможная.
– значение параметра оптимизации, вычисленное из уравнения регрессии). МНК гарантирует, что эта величина минимально возможная.
Обобщение на многофакторный случай не связано с какими-либо принципиальными трудностями.
Воспользуемся тем, что матрицы планирования ортогональны и нормированы, т.е. уравнения (4.15) и (4.16):
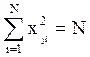 и
и 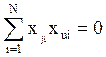 .
.
Для любого числа факторов коэффициенты будут вычисляться по формуле (4.50)
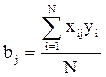 , (4.50)
, (4.50)
В этой формуле j = 0, 1, 2 ..., k – номер фактора. Ноль записан для вычисления b0.
Так как каждый фактор (кроме x0) варьируется на двух уровнях +1 и –1, то вычисления сводятся к приписыванию столбцу y знаков соответствующего фактору столбца и алгебраическому сложению полученных значений. Деление результата на число опытов в матрице планирования дает искомый коэффициент.
Чем меньше величина U, тем более обосновано предположение, что табличная зависимость описывается линейной функцией. Существует показатель, характеризующий тесноту линейной связи между x и y. Это коэффициент корреляции. Он рассчитывается по формуле (4.51).
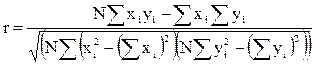 , (4.51)
, (4.51)
Коэффициент корреляции r и коэффициент регрессии b связаны соотношением (4.51).
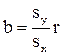 , (4.52)
, (4.52)
где sy, sx - среднеквадратичное отклонение значений x и y.
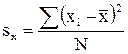 , (4.53)
, (4.53)
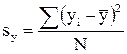 , (4.54)
, (4.54)
где 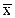 и
и 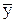 - средние арифметические значения параметров х и у, (4.55 и 4.56).
- средние арифметические значения параметров х и у, (4.55 и 4.56).
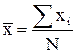 , (4.55)
, (4.55)
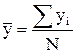 . (4.56)
. (4.56)
Значение коэффициента корреляции удовлетворяет соотношению -1 ≤ r ≤ 1. Чем меньше отличается абсолютная величина r от единицы, тем ближе к линии регрессии располагаются экспериментальные точки. Если коэффициент корреляции равен нулю, то переменные x, y называются некоррелированными. Если r = 0, то это только означает, что между x, y не существует линейной связи, но между ними может существовать зависимость, отличная от линейной.
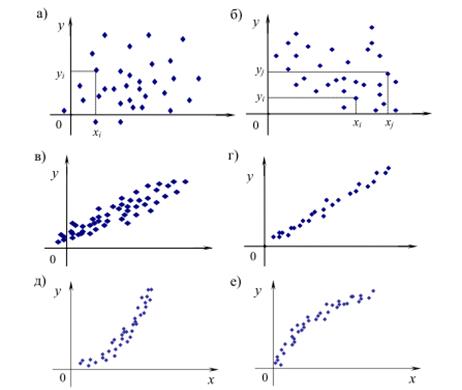
а – корреляция отсутствует; б – слабая корреляция; в – сильная положительная корреляция; г – функциональная линейная корреляция; д,е – функциональные нелинейные зависимости
Рисунок 4.14 – Корреляция случайных величин Х и У
Для того чтобы проверить, значимо ли отличается от нуля коэффициент корреляции, можно использовать критерий Стьюдента. Вычисленное значение критерия определяется по формуле (4.57).
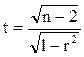 . (4.57)
. (4.57)
Значение t сравнивается со значением, взятым из таблицы распределения Стьюдента (Приложение В) в соответствии с уровнем значимости q и числом степеней свободы N-2. Если t больше табличного, то коэффициент корреляции значимо отличен от нуля.
4.9.2 Регрессионный анализ.
До сих пор мы пользовались МНК как вычислительным приемом. Нам нигде не приходилось вспоминать о статистике. Но, как только мы начинаем проверять какие-либо гипотезы о пригодности модели или о значимости коэффициентов, приходится вспоминать о статистике. И с этого момента МНК превращается в регрессионный анализ.
А регрессионный анализ как всякий статистический метод, применим при определенных предположениях, постулатах.
Первый постулат. Параметр оптимизации y есть случайная величина с нормальным законом распределения. Дисперсия воспроизводимости – одна из характеристик этого закона распределения.
В данном случае, как и по отношению к любым другим постулатам, нас интересуют два вопроса: как проверить его выполнимость и к чему приводят его нарушения?
При наличии большого экспериментального материала (десятки параллельных опытов) гипотезу о нормальном распределении можно проверить стандартными статистическими тестами (например, – критерием). К сожалению, экспериментатор редко располагает такими данными, поэтому приходится принимать этот постулат на веру.
При нарушении нормальности мы лишаемся возможности установления вероятностей, с которыми справедливы те или иные высказывания. В этом таится большая опасность. Мы рискуем загипнотизировать себя численными оценками и вероятностями, за которыми ничего не стоит. Вот почему надо очень внимательно относиться к возможным нарушениям предпосылок.
Второй постулат. Дисперсия y не зависит от абсолютной величины y. Выполнимость этого постулата проверяется с помощью критериев однородности дисперсий в разных точках факторного пространства. Нарушение этого постулата недопустимо.
Всегда существует такое преобразование y, которое делает дисперсии однородными. Увы, его не всегда легко найти. Довольно часто помогает логарифмическое преобразование, с которого обычно начинают поиски.
Третий постулат. Значения факторов суть неслучайные величины. Это несколько неожиданное утверждение практически означает, что установление каждого фактора на заданный уровень и его поддержание существенно точнее, чем сшибка воспроизводимости.
Нарушение этого постулата приводит к трудностям при реализации матрицы планирования. Поэтому оно обычно легко обнаруживается экспериментатором.
Существует еще четвертый постулат, налагающий ограничения на взаимосвязь между значениями факторов. У Нас он выполняется автоматически в силу ортогональности матрицы планирования.
4.9.3 Проверка адекватности модели.
Первый вопрос, который нас интересует после вычисления коэффициентов модели, это проверка ее пригодности. Мы будем называть такую проверку проверкой адекватности модели.
Для характеристики среднего разброса относительно линии регрессии вполне подходит остаточная сумма квадратов. Неудобство состоит в том, что она зависит от числа коэффициентов в уравнении: введите столько коэффициентов, сколько вы провели независимых опытов, и получите остаточную сумму, равную нулю. Поэтому предпочитают относить ее на один «свободный» опыт. Число таких опытов называется числом степеней свободы f.
Числом степеней свободы в статистике называется разность между числом опытов и числом коэффициентов (констант), которые уже вычислены по результатам этих опытов независимо друг от друга.
Остаточная сумма квадратов, деленная на число степеней свободы, называется остаточной дисперсией, или дисперсией адекватности s2ад
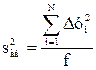 . (4.58)
. (4.58)
В статистике разработан критерий, который очень удобен для проверки гипотезы об адекватности модели. Он называется F-критерием Фишера и определяется следующей формулой:
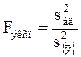 , (4.59)
, (4.59)
где s2{y} - дисперсия воспроизводимости эксперимента.
Удобство использования критерия Фишера состоит в том, что проверку гипотезы можно свести к сравнению с табличным значением.
Если рассчитанное значение F-критерия не превышает табличного, то, с соответствующей доверительной вероятностью, модель можно считать адекватной. При превышении табличного значения эту приятную гипотезу приходится отвергать.
Этот способ расчета дисперсии адекватности, подходит, если опыты в матрице планирования не дублируются, а информация о дисперсии воспроизводимости извлекается из параллельных опытов в нулевой точке или из предварительных экспериментов.
Важны два случая: 1) опыты во всех точках плана дублируются одинаковое число раз (равномерное дублирование), 2) число параллельных опытов не одинаково (неравномерное дублирование).
В первом случае дисперсию адекватности нужно умножать на n,
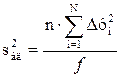 , (4.60)
, (4.60)
где n – число повторных опытов.
Такое видоизменение формулы вполне естественно. Чем больше число параллельных опытов, тем с большей достоверностью оцениваются средние значения. Поэтому требования к различиям между экспериментальными и расчетными значениями становятся более жесткими, что отражается в увеличении F-критерия.
Во втором случае, когда приходится иметь дело с неравномерным дублированием, положение усложняется. Даже когда экспериментатор задумал провести равное число параллельных опытов, часто не удается по тем или иным причинам все их реализовать. Кроме того, иногда приходится отбрасывать отдельные опыты как выпадающие наблюдения.
При неравномерном дублировании нарушается ортогональность матрицы планирования и, как следствие, изменяются расчетные формулы для коэффициентов регрессии и их ошибок, а также для дисперсии адекватности.
Для дисперсии адекватности можно записать общую формулу (4.61).
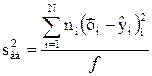 , (4.61)
, (4.61)
где N – число различных опытов (число строк матрицы);
ni – число параллельных опытов в i-й строке матрицы;
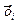 – среднее арифметическое из ni параллельных опытов;
– среднее арифметическое из ni параллельных опытов;
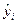 – предсказанное по уравнению значение в этом опыте.
– предсказанное по уравнению значение в этом опыте.
Смысл этой формулы очень прост: различию между экспериментальным и расчетным значением придается тем больший вес, чем больше число повторных опытов.
4.9.4 Проверка значимости коэффициентов.
Проверка значимости каждого коэффициента проводится независимо.
Ее можно осуществлять двумя равноценными способами:
- проверкой по t-критерию Стьюдента;
- построением доверительного интервала.
При использовании полного факторного эксперимента или регулярных дробных реплик доверительные интервалы для всех коэффициентов (в том числе и эффектов взаимодействия) равны друг другу.
Прежде всего, надо найти дисперсию коэффициента регрессии s2{bj}. Она определяется в нашем по формуле (4.62).
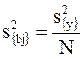 , (4.62)
, (4.62)
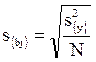 , (4.63)
, (4.63)
Из формулы видно, что дисперсии всех коэффициентов равны друг другу, так как они зависят только от ошибки опыта и числа опытов.
Теперь легко построить доверительный интервал:
Δbj = ±t·s{bj}, (4.64)
где t – табличное значение критерия Стьюдента при числе степеней свободы, с которыми определялась s2{y}, и выбранном уровне значимости (приложение В);
s{bj} – квадратичная ошибка коэффициента регрессии.
Коэффициент значим, если его абсолютная величина больше доверительного интервала.
Проверка значимости коэффициентов по критерию Стьюдента, производится по формуле (4.65).
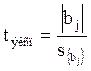 , (4.65)
, (4.65)
где bj – значение j-го коэффициента;
s{bj} – квадратичная ошибка коэффициента регрессии (4.63).
Вычисленное значение t-критерия сравнивается с табличным при числе степеней свободы, с которыми определялась s2{y}, и выбранном уровне значимости (приложение В). Коэффициент значим, если tэксп больше табличного значения критерия.
4.10 Принятие решений после построения модели
Дата добавления: 2017-12-05; просмотров: 647;