Двумерные случайные веЛИчины
Двумерной случайной величиной называется пара случайных величин, определённых на вероятностном пространстве (W, Å, P(×)). Результат наблюдения двумерной случайной величины (X, Y) можно изобразить точкой (x, y) на плоскости. Закон распределения вероятностей между возможными значениями двумерной случайной величины даётся совместной функцией распределения:
F(x, y)=P{X<x, Y<y}
|

|
Запятая в записи вероятности P{X<x, Y<y} заменяет знак умножения между событиями {X<x} и {Y<y}.
Выделим два простейших случая: непрерывный и дискретный.
Двумерная случайная величина (X, Y) называется непрерывной, если существует такая функция p(x, y), что
F(x, y)= 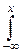
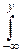 p(x, y)dxdy.
p(x, y)dxdy.
Очевидно, p(x, y)= 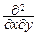 F(x, y).
F(x, y).
Функция p(x, y) называется совместной плотностью вероятности; она играет роль поверхностной плотности распределения единичной вероятностной массы на двумерной плоскости. Вероятность того, что (X, Y) попадёт в область A на двумерной плоскости, вычисляется так:
P(A)= 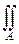 p(x, y)dxdy,
p(x, y)dxdy,
и эта вероятность определена для таких событий A, для которых определён интеграл справа.
В дискретном случае возможные значения (X, Y) можно представить как упорядоченные пары чисел (xi, yj) и закон распределения давать в виде таблицы: pij=P{X=xi, Y=yj}.
Если известен закон распределения двумерной случайной величины (X, Y), то можно найти также законы распределения компонент X и Y.
В общем случае:
FX(x)=P{X<x}=P{X<x, Y<+¥}=F(x, +¥).
Аналогично: FY(y)=F(+¥, y).
В непрерывном случае:
pX(x)= 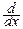 FX(x)= F(x, +¥)=
FX(x)= F(x, +¥)= 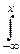 dx
dx 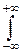 p(x, y)dy= p(x, y)dy.
p(x, y)dy= p(x, y)dy.
Аналогично:
pY(y)= p(x, y)dx.
В дискретном случае:
pi=P{X=xi}=P{X=xi, -¥<Y<+¥}= 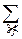 pij.
pij.
Аналогично:
qj=P{Y=yj}= 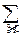 pij.
pij.
Обратная задача – восстановить закон распределения двумерной случайной величины по законам распределения компонент – решается для независимых компонент.
Естественно называть случайные величины X и Y независимыми, если события {X<x} и {Y<y} независимы, т. е., если
F(x, y)=P{X<x, Y<y}=P{X<x}P{Y<y}=FX(x)FY(y).
Если F(x, y) дифференцируема, то
p(x, y)= 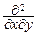 F(x, y)= FX(x)FY(y)= FX(x)
F(x, y)= FX(x)FY(y)= FX(x) 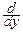 FY(y)=pX(x)pY(y).
FY(y)=pX(x)pY(y).
В дискретном случае:
pij=P{X=xi, Y=yj}=P{X=xi}P{Y=yj}=piqj.
Совершенно аналогично вводятся n-мерные случайные величины.
Например, пусть независимые случайные величины Xi, i=1, 2, ¼ , n распределены по стандартному нормальному закону: Xi~N(0, 1), i=1, 2, ¼ , n. Их совместная плотность вероятности равна:
p(x1, x2, ¼ , xn)= 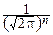 exp(-
exp(- 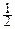
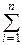 xi2).
xi2).
Выполним невырожденное линейное преобразование и введём новые случайные величины
Yk= aijXi, k=1, 2, ¼ , n.
Это преобразование можно переписать в матричном виде: Y=AX, где XT=
=(X1, X2, ¼ , Xn), YT=(Y1, Y2, ¼ , Yn), A=||aij||, DetA¹0. Так как преобразование невырождено, то оно обратимо, так что X=A-1Y. В евклидовом пространстве переменных y1, y2, ¼ , ynсовместная плотность вероятности вектора Y равна
q(y1, y2, ¼ , yn)= 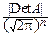 exp(- YTSY),
exp(- YTSY),
где S=ATA – матрица квадратичной формы в показателе экспоненты, а |DetA|=J – якобиан преобразования.
Обратно, если совместная плотность вероятности n-мерного вектора равна
q(y1, y2, ¼ , yn)=C×exp(- YTSY),
где S – положительно определённая матрица (что нужно для сходимости интеграла по всему пространству), а C – константа, то существует такая матрица A, что S=ATA, С=|DetA|= 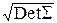 и преобразование Y=AX, (X=A-1Y) приводит к независимым компонентам Xi~N(0, 1), i=1, 2, ¼ , n.
и преобразование Y=AX, (X=A-1Y) приводит к независимым компонентам Xi~N(0, 1), i=1, 2, ¼ , n.
Можно сделать ещё одно обобщение, введя параметры масштаба и сдвига по всем осям.
n-мерной нормальной плотностью называется
p(x1, x2, ¼ , xn)= exp(- 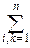 aik(xi-bi)(xk-bk)),
aik(xi-bi)(xk-bk)),
где aik, bi– параметры n-мерного нормального вектора, A=||aij|| – положительно определённая матрица.
C2– распределение
Пусть X1, X2, ¼ , Xn– независимые (в совокупности) нормально распределённые случайные величины: Xi~N(0, 1), i=1, 2, ¼ , n.
Определим сумму их квадратов:
cn2= Xi2
и найдём закон распределения случайной величины cn2:
Fcn2(x)= 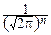
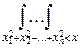 exp(- xi2)dx1dx2¼dxn, x>0.
exp(- xi2)dx1dx2¼dxn, x>0.
Принимая во внимание, что подынтегральная функция принимает постоянное значение на любой n-мерной сфере (x12+x22+¼+xn2=r2), проведём интегрирование по сферическим слоям. Обозначим через Vn(r) объём n-мерной сферы радиуса r, а через Sn(r) – площадь её поверхности.
Отметим, что:
Sn(r)= 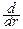 Vn(r), Vn(r)=
Vn(r), Vn(r)= 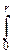 Sn(r)dx.
Sn(r)dx.
В частности, в двумерном и трёхмерном случаях имеем:
V2(r)=pr2, S2(r)=2pr, V3(r)= 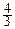 pr3, S3(r)=4pr2.
pr3, S3(r)=4pr2.
Ясно, что можно считать
Vn(r)=Cnrn, Sn(r)=nCnrn-1,
где Cn– константа, которую мы найдём ниже.
Продолжим теперь преобразование функции распределения cn2:
Fcn2(x)= 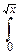 exp(- r2)nCnrn-1dr.
exp(- r2)nCnrn-1dr.
Мы превратили n-кратный интеграл в обычный однократный.
Из последнего равенства найдём плотность вероятности:
pcn2(x)= Fcn2(x)= 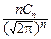 exp(-
exp(- 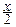 )
) 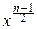
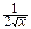 Û pcn2(x)=
Û pcn2(x)= 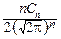
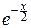
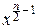 , x>0.
, x>0.
Если x£0, то ясно, что pcn2(x)º0.
Прежде, чем перейти к вычислению константы Cn, напомним определение и свойства гамма-функции, которыми нам ещё не раз придётся пользоваться.
––²––
Определение и свойства гамма-функции
Гамма-функция определена на положительной полуоси равенством:
G(x)= 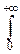 e-ttx-1dt, x>0.
e-ttx-1dt, x>0.
Свойства гамма-функции:
1°. G(x+1)=xG(x). Это свойство легко доказывается интегрированием по частям интеграла, определяющего G(x+1): G(x+1)= e-ttxdt.
2°. G(1)=1.
3°. Для любого натурального n: G(n+1)=n! Доказательство этого факта сразу следует из двух первых свойств. Данное свойство показывает, что гамма-функция является естественным обобщением факториала.
4°. G( )= 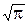 .
.
Для доказательства этого свойства достаточно сделать замену переменной в интеграле, определяющем G( ):
G( )= e-t 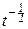 dt
dt
и положить t= y2:
G( )= 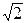
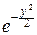 dy.
dy.
Вспоминая рассмотренный нами выше интеграл Пуассона I= 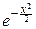 dx=
dx= 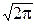 , находим, что G( )= .
, находим, что G( )= .
5°. Для полуцелого положительного n: G(n+ )= 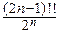 .
.
Это равенство доказывается по индукции с использованием свойств 1° и 4°.
6°. Формула Стирлинга:
при x®+¥: G(x+1)~ 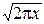 xxe-x.
xxe-x.
Мы приведём не вполне строгое, но достаточно простое доказательство этой формулы.
При любом фиксированном x (x>0):
G(x+1)= e-ttxdt= exlnt-tdt= ey(t)dt,
где y(t)=xlnt-t.
Легко убедиться, что функция y(t) имеет максимум при t=x. Разложим y(t) в ряд Тейлора в окрестности точки t=x, ограничиваясь первыми тремя слагаемыми:
y(t)»xlnx-x- 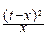 =xlnx-x- (
=xlnx-x- ( 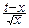 )2.
)2.
Поэтому
G(x+1)»exlnx-x 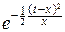 dt=xxe-x dt.
dt=xxe-x dt.
Введём новую переменную: y= . Имеем:
G(x+1)»xxe-x 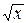
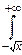
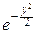 dy.
dy.
В последнем интеграле при больших x (x®+¥) нижний предел интегрирования можно заменить на -¥: dy» dy=I – интеграл Пуассона и, как мы знаем, он равен . Поэтому при больших положительных x:
G(x+1)»xxe-x ,
что и требовалось доказать.
––²––
Выше мы получили выражение для плотности вероятности pcn2(x):
pcn2(x)= при x>0 и pcn2(x)º0 при x£0
и нам осталось найти величину константы Cn.
Воспользуемся свойством нормированности pcn2(x):
dx=1.
Подстановка x= 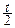 приводит интеграл к гамма-функции:
приводит интеграл к гамма-функции:
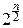 × e-t
× e-t 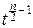 dt=1 Û
dt=1 Û 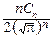 G(
G( 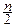 )=1 Û Cn=
)=1 Û Cn= 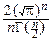 =
= 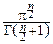 .
.
Итак, мы можем в окончательном виде записать плотность вероятности и функцию распределения случайной величины cn2:
pcn2(x)= 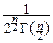 , при x>0, и pcn2(x)º0, при x£0,
, при x>0, и pcn2(x)º0, при x£0,
Fcn2(x)= 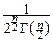
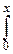 dx, при x>0, и Fcn2(x)º0, при x£0.
dx, при x>0, и Fcn2(x)º0, при x£0.
Этот закон табулирован и нет необходимости вычислять интеграл точно даже для чётных n, при которых он берётся в элементарных функциях.
Попутно мы нашли общие формулы для объёма n-мерного шара и площади поверхности n-мерной сферы:
Vn(r)= rn, Sn(r)= 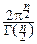 rn-1.
rn-1.
C– распределение
При y>0:
Fcn(y)=P{cn<y}=P{cn2<y2}= 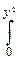 dx.
dx.
Отсюда:
pcn(y)= Fcn(y)= 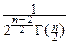 yn-1, при y>0, и pcn(y)º0, при y£0.
yn-1, при y>0, и pcn(y)º0, при y£0.
и, следовательно,
Fcn(x)= 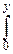 yn-1dy, при y>0 и Fcn(x)º0, при y£0.
yn-1dy, при y>0 и Fcn(x)º0, при y£0.
Дата добавления: 2017-09-19; просмотров: 550;