Процессы в Linux и Unix
Для описания состояний процессов используется модель трех состояний. Модель состоит из:
1. состояния выполнения
2. состояния ожидания
3. состояния готовности
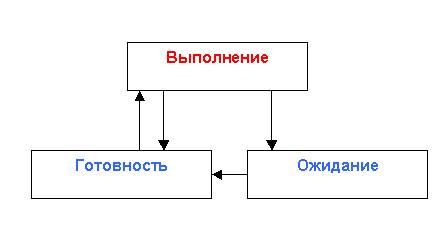
Выполнение – это активное состояние, во время которого процесс обладает всеми необходимыми ему ресурсами. В этом состоянии процесс непосредственно выполняется процессором.
Ожидание – это пассивное состояние, во время которого процесс заблокирован, он не может быть выполнен, потому что ожидает какое-то событие, например, ввода данных или освобождения нужного ему устройства.
Готовность – это тоже пассивное состояние, процесс тоже заблокирован, но в отличие от состояния ожидания, он заблокирован не по внутренним причинам, а по внешним, независящим от процесса, причинам.
Из состояния готовности процесс может перейти только в состояние выполнения. В состоянии выполнения может находиться только один процесс на один процессор.
Из состояния выполнения процесс может перейти либо в состояние ожидания или состояние готовности.
Планировщик следит за временем выполнения первого процесса, если "время вышло", планировщик переводит процесс 1 в состояние готовности, а процесс 2 - в состояние выполнения. Затем, когда, время отведенное, на выполнение процесса 2, закончится, процесс 2 перейдет в состояние готовности, а процесс 3 - в состояние выполнения.
Более сложная модель – это модель, состоящая из пяти состояний. В этой модели появилось два дополнительных состояния: рождение процесса и смерть процесса. Рождение процесса – это пассивное состояние, когда самого процесса еще нет, но уже готова структура для появления процесса. Смерть процесса – самого процесса уже нет, но может случиться, что его структура, осталась в списке процессов. Такие процессы называются зомби.
Диаграмма модели пяти состояний представлена на рисунке.
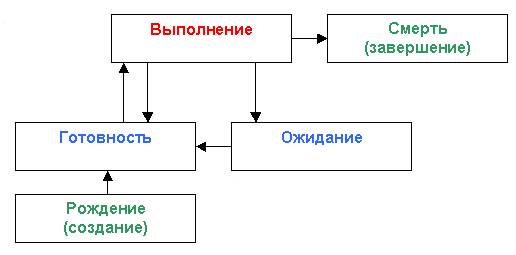
Рисунок. Модель пяти состояний
Над процессами можно производить следующие операции:
1. Создание процесса – это переход из состояния рождения в состояние готовности
2. Уничтожение процесса – это переход из состояния выполнения в состояние смерти
3. Восстановление процесса – переход из состояния готовности в состояние выполнения
4. Изменение приоритета процесса – переход из выполнения в готовность
5. Блокирование процесса – переход в состояние ожидания из состояния выполнения
6. Пробуждение процесса – переход из состояния ожидания в состояние готовности
7. Запуск процесса (или его выбор) – переход из состояния готовности в состояние выполнения
Для создания процесса операционной системе нужно:
1. Присвоить процессу имя
2. Добавить информацию о процессе в список процессов
3. Определить приоритет процесса
4. Сформировать блок управления процессом
5. Предоставить процессу нужные ему ресурсы
Команда, которая позволяет получить информацию о процессе, называется ps(1) – это сокращение от "process status" (англ. – состояние процесса). После выполнения команда ps возвращает результат (например):
PID TTY TIME CMD
2241 ttyp4 00:00:00 bash
2346 ttyp4 00:00:00 ps
Команда ps выдает список процессов, выполняющихся на текущем терминале. Видно, в последнем столбце имя, при помощи которого был запущен процесс. "ps" появляется в этом списке, так как эта команда выполнялась, когда выводился список выполняющихся процессов.
PID – Process IDentifier (англ. – идентификатор процесса). pid – уникальное положительное число, которое присваивается каждому выполняющемуся процессу. Если выполнение процесса завершилось, его pid может быть использован заново, однако гарантируется, что во время выполнения процесса, его pid остается неизменным.
Можно получить список всех процессов, запущенных на машине:
ps –e
Чтобы было удобнее анализировать этот список, можно перенаправить вывод в файл ps.log:
ps -e > ps.log
Количество и состав процессов в списке зависит от конфигурации системы, однако есть несколько процессов, присутствующих на всех машинах. Вне зависимости от конфигурации процесс с pid равным 1 – это всегда "init", прародитель всех процессов. Он имеет первый pid, так как это первый процесс, запускаемый операционной системой. Также можно легко заметить наличие множества процессов с именами, заканчивающимися на "d" – это так называемые "демоны" – одни из самых важных процессов в системе.
При написании многозадачного кода в Linux используется стандартная библиотека C (libc, реализованная в Linux в glibc) и возможности системы Unix System V. Unix System V (далее SysV) – коммерческая реализация Unix, породившая одно из двух самых важных семейтв Unix, второе – BSD Unix.
В libc тип pid_t определен как целое, способное вместить в себе pid. Впредь мы будем использовать этот тип для работы с pid, однако это нужно только для ясности: использование целого типа дало бы тот же результат.
Рассмотрим функцию, которая сообщает нам pid процесса, содержащего программу
pid_t getpid (void)
и напишем программу, которая выведет в стандартный вывод свой pid. При помощи любого редактора напишите следующий код
--------------------------------------------------------------
#include <unistd.h>
#include <sys/types.h>
#include <stdio.h>
int main()
{
pid_t pid;
pid = getpid();
printf("pid присвоенный процессу - %d\n", pid);
return 0;
}
--------------------------------------------------------------
Программу необходимо сохранить в print_pid.c и затем скомпилировать:
gcc -Wall -o print_pid print_pid.c
Команда создаст исполняемый файл print_pid. Запуск программы приведет к появлению на экране положительного числа, и, если продолжать запускать ее, то это число будет постоянно увеличиваться на единицу; хотя это может быть и не так, потому что в перерыве между запусками может быть создан другой процесс.
Когда программа (содержащаяся в процессе A) создает новый процесс (B), они оба идентичны, то есть у них одинаковый код, их память наполнена одинаковыми данными (однако области различны) и имеют одинаковое состояние процессора. С этого момента они могут выполнять различные участки кода, например, в зависимости от ввода пользователя или некоторых произвольных данных. Процесс A – "родительский процесс", а B – "дочерний". Ниже приведена функция, которая создает новый процесс
pid_t fork(void)
При ее вызове происходит разветвление выполнения процесса, отчего и происходит название функции (to fork, англ. – ветвиться). Число, которое она возвращает – это pid, однако тут надо обратить внимание на то, что текущий процесс дублируется в родительском и дочернем, которые будут выполняться, чередуясь с другими выполняющимися процессами, производя различные действия. Но какой процесс будет выполняться сразу после создания копии: родительский или дочерний? Ответ: один из двух. Решение, какой процесс должен выполняться, принимается частью операционной системы, которая называется планировщиком, и она не принимает во внимание, является процесс родительским или дочерним, работая по алгоритму, основанному на других параметрах.
Как бы то ни было, важно знать какой процесс выполняется. Оба процесса содержат код, как родительский, так и дочерний, однако оба они должны выполнить только свой набор кода, например, а соответствии со следующим алгоритмом:
- РАЗВЕТВИТЬ
- ЕСЛИ ТЫ ДОЧЕРНИЙ ПРОЦЕСС ВЫПОЛНИТЬ (...)
- ЕСЛИ ТЫ РОДИТЕЛЬСКИЙ ПРОЦЕСС ВЫПОЛНИТЬ (...), –
который представляет собой код программы, написанный на некотором метаязыке. Причем известно, что функция fork возвращает '0' в дочерний процесс и pid дочернего процесса в родительский. Поэтому достаточно сверить возвращенный pid с нулем, и мы будем знать, какой процесс выполняет этот код. На языке C это выглядит следующим образом:
int main()
{
pid_t pid;
pid = fork();
if (pid == 0)
{
КОД ДОЧЕРНЕГО ПРОЦЕССА
}
КОД РОДИТЕЛЬСКОГО ПРОЦЕССА
}
Пример многозадачного кода: файл fork_demo.c. Программа делает разветвление и оба процесса: родительский и дочерний, выводят кое-что на экран. Результатом является чередование этих выводов.
(01) #include <unistd.h>
(02) #include <sys/types.h>
(03) #include <stdio.h>
(04) int main()
(05) {
(05) pid_t pid;
(06) int i;
(07) pid = fork();
(08) if (pid == 0){
(09) for (i = 0; i < 8; i++){
(10) printf("-ДОЧЕРНИЙ-\n");
(11) }
(12) return(0);
(13) }
(14) for (i = 0; i < 8; i++){
(15) printf("+РОДИТЕЛЬСКИЙ+\n");
(16) }
(17) return(0);
(18) }
Строки (01)-(03) содержат включения заголовочных файлов необходимых библиотек (стандартный ввод/вывод, многозадачность).
Функция main (как обычно в GNU) возвращает целое, которое равно нулю, если все прошло без ошибок и код ошибки, если что-то случилось не то.
Пусть все выполняется без ошибок. Далее, определяется переменная для pid (05) и целое для счетчика в циклах. Типы этих переменных одинаковы, однако они указаны различными для ясности.
В строке (07) вызывается функция fork, которая возвратит нуль в программу, выполняющуюся в дочернем процессе, и pid дочернего процесса в родительском; проверка производится в строке (08). Теперь код строк (09)-(13) будет исполнен в дочернем процессе, а оставшийся код (14)-(16) в родительском.
Эти части кода просто выводят 8 раз в стандартный вывод слово "-ДОЧЕРНИЙ-" или "+РОДИТЕЛЬСКИЙ+" в зависимости от того, какой процесс выполняется, а затем завершают выполнение, возвращая 0. Последнее по-настоящему важно, так как без этого "return" дочерний процесс после завершения цикла будет выполнять далее код родительского.
Подобные ошибки очень сложно обнаруживать, так как выполнение многозадачных программ (особенно сложных) дает различные результаты при каждом выполнении, отлаживать их, пользуясь результатами, просто невозможно.
Задержка случайной длины перед каждым вызовом prinf, позволит нагляднее увидеть эффект многозадачности:
sleep(rand()%4)
это заставит программу "заснуть" на случайное число секунд: от 0 до 3 (% возвращает остаток от целочисленного деления). Теперь код выглядит так
(09) for (i = 0; i < 8; i++){
(->) sleep (rand()%4);
(10) printf("-ДОЧЕРНИЙ-\n");
(11) }
то же можно сделать и с кодом родительского процесса.
Порядок вывода строк может выглядеть следующим образом:
[leo@mobile ipc2]$ ./fork_demo2
-ДОЧЕРНИЙ-
+РОДИТЕЛЬСКИЙ+
+РОДИТЕЛЬСКИЙ+
-ДОЧЕРНИЙ-
-ДОЧЕРНИЙ-
+РОДИТЕЛЬСКИЙ+
+РОДИТЕЛЬСКИЙ+
-ДОЧЕРНИЙ-
-ДОЧЕРНИЙ-
+РОДИТЕЛЬСКИЙ+
+РОДИТЕЛЬСКИЙ+
-ДОЧЕРНИЙ-
-ДОЧЕРНИЙ-
-ДОЧЕРНИЙ-
+РОДИТЕЛЬСКИЙ+
+РОДИТЕЛЬСКИЙ+
[leo@mobile ipc2]$
Часто родительскому процессу необходимо обмениваться информацией с дочерними или хотя бы синхронизироваться с ними, чтобы выполнять операции в нужное время. Первый способ синхронизации процессов – функция wait
pid_t waitpid (pid_t PID, int *STATUS_PTR, int OPTIONS)
где PID – это PID ожидаемого процесса, STATUS_PTR – указатель на целое, которое будет содержать статус дочернего процесса (NULL, если эта информация не нужна), а OPTIONS – это набор опций. Пример программы, где родительский процесс создает дочерний и ждет его завершения
--------------------------------------------------------------
#include <unistd.h>
#include <sys/types.h>
#include <stdio.h>
int main()
{
pid_t pid;
int i;
pid = fork();
if (pid == 0){
for (i = 0; i < 14; i++){
sleep (rand()%4);
printf("-ДОЧЕРНИЙ-\n");
}
return 0;
}
sleep (rand()%4);
printf("+РОДИТЕЛЬСКИЙ+ Ожидаю завершения выполнения дочернего процесса...\n");
waitpid (pid, NULL, 0);
printf("+РОДИТЕЛЬСКИЙ+ ...завершен\n");
return 0;
}
--------------------------------------------------------------
Функция sleep введена в код родительского процесса, чтобы сделать различными результаты выполнения программы.
Синхронизация процессов
Библиотека SysV – стандартная библиотека, содержащая примитивы структуры IPC ключами. IPC ключ – это число, однозначно идентифицирующее IPC структуру управления (описывается ниже). Также ключ можно использовать для образования универсальных идентификаторов, т.е. для организации не IPC структур.
Ключ создаётся функцией ftok(3).
key_t ftok(const char *pathname, int proj_id);
Для генерирования ключа ftok берёт имя существующего файла (pathname) и идентификатор процесса (proj_id). Алгоритм построения ключа не исключает возможности появления дубликатов, поэтому следует иметь маленькую библиотеку, просматривающую уже созданные ключи и не допускающую повторений.
Семафоры
Семафор – особая структура, содержащая число большее или равное нулю и управляющая цепочкой процессов, ожидающих особого состояния на данном семафоре. Хотя они и кажутся очень простыми, семафоры – это очень мощное средство, а потому, на самом деле, весьма сложное.
Семафоры используются для контроля доступа к ресурсам: число в семафоре представляет собой количество процессов, которые могут получить доступ к данным. Каждый раз, когда процесс обращается к данным, значение в семафоре, должно быть уменьшено на единицу, и увеличено, когда работа с данными будет прекращена. Если ресурс эксклюзивный, то есть к данным должен иметь доступ только один процесс, то начальное значение в семафоре следует установить единицей.
Семафоры можно использовать и для других целей, например для счётчика ресурсов. В этом случае число в семафоре – количество свободных ресурсов (например, количество свободных ячеек памяти).
Пусть имеется буфер, в который несколько процессов S1,...,Sn могут записывать, и только один процесс L может из него считывать. Также операции нельзя выполнять одновременно (в данный момент времени только один процесс должен оперировать с буфером). Очевидно, что процессы Si могут писать всегда, когда буфер не полон, а процесс L может читать, когда буфер не пуст.
Таким образом, необходимо три семафора: один управляет доступом к буферу, а два других следят за числом элементов в нём.
Учитывая, что доступ к буферу должен быть эксклюзивным, первый семафор будет бинарным (его значение будет нулём или единицей), в то время как второй и третий будут принимать значения, зависящие от размера буфера.
В библиотеке C, в SysV семафор создаёт функция semget(2)
int semget(key_t key, int nsems, int semflg)
где key – IPC ключ, nsems – число семафоров, которое нежно создать, и semflg – права доступа, закодированные в 12 бит: первые три бита отвечают за режим создания, остальные девять – права на запись и чтение для пользователя, группы и остальных. Таким образом, SysV создаёт сразу несколько семафоров, что уменьшает код.
--------------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <linux/types.h>
#include <linux/ipc.h>
#include <linux/sem.h>
int main(void)
{
key_t key;
int semid;
key = ftok("/etc/fstab", getpid());
/* создать только один семафор: */
semid = semget(key, 1, 0666 | IPC_CREAT);
return 0;
}
--------------------------------------------------------------
Управление семафором происходит с помощью функции semctl(2),
int semctl(int semid, int semnum, int cmd, ...),
которая выполняет действие cmd на наборе семафоров semid или (если требуется командой) на одном семафоре с номером semnum.
В зависимости от команды, может понадобится указать ещё один аргумент следующего типа:
{
union semun
int val; /* значение для SETVAL */
struct semid_ds *buf; /* буферы для IPC_STAT, IPC_SET */
unsigned short *array; /* массивы для GETALL, SETALL */
/* часть, особенная для Linux: */
struct seminfo *__buf; /* буфер для IPC_INFO */
};
Чтобы изменить значение семафора, используется директива SETVAL, новое значение должно быть указано в semun.
[...]
/* создать только один семафор */
semid = semget(key, 1, 0666 | IPC_CREAT);
/* в семафоре 0 установить значение 1 */
arg.val = 1;
semctl(semid, 0, SETVAL, arg);
[...]
Удаление семафора и освобождение структуры, использовавшейся для управления им выполняет директива IPC_RMID. Она удаляет семафор и посылает сообщение об этом всем процессам, ожидающим доступа к ресурсу. Последний раз изменим программу:
[...]
/* в семафоре 0 установить значение 1 */
arg.val = 1;
semctl(semid, 0, SETVAL, arg);
/* удалить семафор */
semctl(semid, 0, IPC_RMID);
[...]
Использовать семафор можно с помощью процедуры semop(2),
int semop(int semid, struct sembuf *sops, unsigned nsops);
здесь semid – идентификатор набора семафоров, sops – массив, содержащий операции, которые необходимо произвести, nsops – число этих операций. Каждая операция представляется структурой sembuf.
unsigned short sem_num; short sem_op; short sem_flg;
т.е номером семафора в множестве (sem_num), операцией (sem_op) и флагом, устанавливающим режим ожидания; пока он будет нулём.
Операции, которые можно указать, являются целыми числами и подчиняются следующим правилам:
1. sem_op < 0
Если модуль значения в семафоре больше или равен модулю sem_op, то sem_op добавляется к значению в семафоре (т.е. значение в семафоре уменьшается). Если модуль sem_op больше, то процесс переходит в спящий режим, пока не будет достаточно ресурсов.
2. sem_op = 0. Процесс спит пока значение в семафоре не достигнет нуля.
3. sem_op > 0 Значение sem_op добавляется к значению в семафоре, используемый ресурс освобождается.
Следующая программа представляет пример использования семафоров, реализуя предыдущий пример с буфером для чего создается пять процессов W и один процесс R. Процессы W будут пытаться получить доступ к ресурсу (буферу), закрывая его через семафор, и, если буфер не полон, будут класть в него элемент и освобождать ресурс. Процесс R будет закрывать ресурс, брать из него элемент, если буфер не пуст, и разблокировать ресурс.
Чтение и запись в буфер на самом деле ненастоящие: так происходит потому, что каждый процесс выполняется в своей собственной области памяти и не может обращаться к памяти другого процесса. Это делает настоящее управление буфером шестью процессами невозможным, так как каждый процесс будет видеть свою копию буфера.
Первый семафор (с номером 0) действует как замок к буферу, и его максимальное значение равно единице, остальные два отвечают за переполнение и наличие элементов в буфере. Одним семафором этого не добиться.
Потребность в двух семафорах связана с особенностью работы функции semop. Если, например, процессы W уменьшают значение в семафоре, отвечающем за свободное место в буфере, до нуля, то процесс R может увеличивать это значение до бесконечности. Поэтому такой семафор не может указывать на отсутствие элементов в буфере.
--------------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <linux/types.h>
#include <linux/ipc.h>
#include <linux/sem.h>
int main(int argc, char *argv[])
{
/* IPC */
pid_t pid;
key_t key;
int semid;
union semun arg;
struct sembuf lock_res = {0, -1, 0};
struct sembuf rel_res = {0, 1, 0};
struct sembuf push[2] = {1, -1, IPC_NOWAIT, 2, 1, IPC_NOWAIT};
struct sembuf pop[2] = {1, 1, IPC_NOWAIT, 2, -1, IPC_NOWAIT};
/* Остальное */
int i;
if(argc < 2){
printf("Usage: bufdemo [dimensione]\n");
exit(0);
}
/* Семафоры */
key = ftok("/etc/fstab", getpid());
/* Создать набор из трёх семафоров */
semid = semget(key, 3, 0666 | IPC_CREAT);
/* Установить в семафоре номер 0 (Контроллер ресурсов)
значение "1" */
arg.val = 1;
semctl(semid, 0, SETVAL, arg);
/* Установить в семафоре номер 1 (Контроллер свободного места)
значение длины буфера */
arg.val = atol(argv[1]);
semctl(semid, 1, SETVAL, arg);
/* Установить в семафоре номер 2 (Контроллер элементов в буфере)
значение "0" */
arg.val = 0;
semctl(semid, 2, SETVAL, arg);
/* Fork */
for (i = 0; i < 5; i++){
pid = fork();
if (!pid){
for (i = 0; i < 20; i++){
sleep(rand()%6);
/* Попытаться заблокировать ресурс (семафор номер 0) */
if (semop(semid, &lock_res, 1) == -1){
perror("semop:lock_res");
}
/* Уменьшить свободное место (семафор номер 1) /
Добавить элемент (семафор номер 2) */
if (semop(semid, &push, 2) != -1){
printf("---> Process:%d\n", getpid());
}
else{
printf("---> Process:%d BUFFER FULL\n", getpid());
}
/* Разблокировать ресурс */
semop(semid, &rel_res, 1);
}
exit(0);
}
}
for (i = 0;i < 100; i++){
sleep(rand()%3);
/* Попытаться заблокировать ресурс (семафор номер 0)*/
if (semop(semid, &lock_res, 1) == -1){
perror("semop:lock_res");
}
/* Увеличить свободное место (семафор номер 1) /
Взять элемент (семафор номер 2) */
if (semop(semid, &pop, 2) != -1){
printf("<--- Process:%d\n", getpid());
}
else printf("<--- Process:%d BUFFER EMPTY\n", getpid());
/* Разблокировать ресурс */
semop(semid, &rel_res, 1);
}
/* Удалить семафоры */
semctl(semid, 0, IPC_RMID);
return 0;
}
--------------------------------------------------------------
Часть кода
struct sembuf lock_res = {0, -1, 0};
struct sembuf rel_res = {0, 1, 0};
struct sembuf push[2] = {1, -1, IPC_NOWAIT, 2, 1, IPC_NOWAIT};
struct sembuf pop[2] = {1, 1, IPC_NOWAIT, 2, -1, IPC_NOWAIT};
выполняет следующие действия, которые можно производить над семафорами: первые две – содержат по одному действию каждая, вторые – по два. Первое действие, lock_res, блокирует ресурс: оно уменьшает значение первого (номер 0) семафора на единицу (если значение в семафоре не нуль), а если ресурс уже занят, то процесс ждёт. Действие rel_res аналогично lock_res, только значение в первом семафоре увеличивается на единицу, т.е. убирается блокировка ресурса.
Действия push и pop несколько отличаются от первых: это массивы из двух действий. Первое действие над семафором номер 1, второе – над семафором номер 2; одно увеличивает значение в семафоре, другое уменьшает, но теперь процесс не будет ждать освобождения ресурса: IPC_NOWAIT заставляет его продолжить работу, если ресурс заблокирован.
/* Установить в семафоре номер 0 (Контроллер ресурсов)
значение "1" */
arg.val = 1;
semctl(semid, 0, SETVAL, arg);
/* Установить в семафоре номер 1 (Контроллер свободного места)
значение длины буфера */
arg.val = atol(argv[1]);
semctl(semid, 1, SETVAL, arg);
/* Установить в семафоре номер 2 (Контроллер элементов в буфере)
значение "0" */
arg.val = 0;
semctl(semid, 2, SETVAL, arg);
Инициализация значений в семафорах: в первом – единицей, так как он контролирует доступ к ресурсу, во втором – длиной буфера (заданной в командной строке), в третьем – нулём (т.е. числом элементов в буфере).
/* Попытаться заблокировать ресурс (семафор номер 0) */
if (semop(semid, &lock_res, 1) == -1){
perror("semop:lock_res");
}
/* Уменьшить свободное место (семафор номер 1) /
Добавить элемент (семафор номер 2) */
if (semop(semid, &push, 2) != -1){
printf("---> Process:%d\n", getpid());
}
else{
printf("---> Process:%d BUFFER FULL\n", getpid());
}
/* Освободить ресурс */
semop(semid, &rel_res, 1);
Процесс W пытается заблокировать ресурс посредством действия lock_res; как только это ему удаётся, он добавляет элемент в буфер посредством действия push и выводит сообщение об этом на стандартный вывод. Если операция не может быть произведена, процесс выводит сообщение о заполнении буфера. В конце процесс освобождает ресурс.
/* Попытаться заблокировать ресурс (семафор номер 0) */
if (semop(semid, &lock_res, 1) == -1){
perror("semop:lock_res");
}
/* Увеличить свободное место (семафор номер 1) /
Взять элемент (семафор номер 2) */
if (semop(semid, &pop, 2) != -1){
printf("<--- Process:%d\n", getpid());
}
else printf("<--- Process:%d BUFFER EMPTY\n", getpid());
/* Отпустить ресурс */
semop(semid, &rel_res, 1);
Процесс R ведёт себя практически так же как и W процесс: блокирует ресурс, производит действие pop, освобождает ресурс.
Каждый процесс способен создать любое количество структур называемых очередями: каждая структура может содержать любое количество сообщений разных типов, которые имеют разную природу и содержат любую информацию; каждый процесс способен послать сообщение в очередь, зная ее идентификатор. Также процесс способен получить доступ к очереди и прочитать сообщения в хронологическом порядке (начиная с самого первого, последнего, самого недавнего и последнего, поступившего в очередь), но выборочно, т.е. сообщения только определенного типа, что обеспечивает контроль за возможностью прочитать эти сообщения.
Использование очереди легко понять представив ее в виде почтовой системы между процессами: каждый процесс обладает адресом для взаимодействия с другими процессами. Процесс читает сообщения, предназначенные ему, и дальнейшая его работа зависит от этих сообщений.
Таким образом, синхронизация двух процессов достигается использованием сообщений: ресурсы по-прежнему будут обладать семафорами, чтобы процессы знали их статус, а разделение времени работы происходит при помощи сообщений.
Синхронизация определяется еще одним аспектом – коммуникационным протоколом.
Протоколом называется набор правил, с помощью которого происходит взаимодействие объектов.
Использование очередей сообщений позволяет создавать сложные протоколы; причем все сетевые протоколы (TCP/IP, DNS, SMTP,...) построены на архитектуре обмена сообщениями. Все достаточно просто – нет никакой разницы на одном ли компьютере происходит взаимодействие процессов или между разными.
Рассмотрим простой протокол, основанный на обмене сообщениями: два процесса (А и В) выполняются параллельно и работают с разными данными: после окончания работы каждого им необходимо обменяться данными. Простой протокол их взаимодействия выглядит следующим образом:
ПРОЦЕСС B:
* работает со своими данными
* по окончании работы посылает сообщение процессу А
* получив ответ от процесса A – начинает передачу ему данных
ПРОЦЕСС A:
* работает со своими данными
* ожидает сообщение от процесса B
* отвечает на сообщение
* принимает данные и объединяет со своими
Выбор процесса ответственного за объединение данных, в приведенном примере, достаточно условен; в реальной жизни это зависит от природы взаимодействующих процессов ( клиент/сервер ).
Рассмотренный протокол легко применим к n процессам. Любой процесс, кроме А, обрабатывает свои данные и затем посылает сообщение процессу А. После ответа процесса А ему пересылаются данные, нет необходимости менять структуру процессов, кроме А.
Рассмотрим реализацию этого механизма в ОС Linux. Как было сказано ранее, для работы в Linux доступен набор примитивов.
Структура для описания сообщения называется msgbuf; и объявлена в linux/msg.h
/* message buffer for msgsnd and msgrcv calls */
struct msgbuf {
long mtype; /* type of message */
char mtext[1]; /* message text */
};
Поле mtype описывает тип сообщения и всегда имеет положительное значение: соответствие между типами сообщений и их числовым представлением необходимо определить заранее – это часть протокола.
Второе поле представляет само сообщение. Структура msgbuf может быть переопределена и содержать более сложные данные; например ее можно определить так:
struct message {
long mtype; /* message type */
long sender; /* sender id */
long receiver; /* receiver id */
struct info data; /* message content */
...
};
Прототип сообщения может иметь максимальный размер до 4056 байт. Естественно, можно перекомпилировать ядро и увеличить это значение, но, тогда приложение станет непереносимым.
Для создания новой очереди процесс использует функцию msgget()
int msgget(key_t key, int msgflg)
в которую необходимо передать аргументы и IPC ключ, который можно установить в
IPC_CREAT | 0660
( создать очередь, если она еще не существует и предоставить доступ владельцу и группе 'users' ). Эта функция возвращает идентификатор очереди.
Чтобы послать сообщение в очередь, зная ее идентификатор, необходимо использовать функцию msgsnd()
int msgsnd(int msqid, struct msgbuf *msgp, int msgsz, int msgflg)
где msqid идентификатор очереди, msgp указатель на сообщение, которое мы хотим послать (тип которого определен как struct msgbuf но который мы переопределили), msgsz размер сообщения (исключая длину mtype типа long, т.е. 4 байта) и msgflg флаг правила ожидания. Размер сообщения достаточно просто получить, используя следующее выражение:
length = sizeof(struct message) - sizeof(long);
что касается правила ожидания в случае полной очереди: если msgflg установлен в IPC_NOWAIT посылающий сигнал процесс не будет ждать освобождения очереди, и выйдет с кодом ошибки.
Чтобы прочитать сообщения, находящиеся в очереди необходимо использовать системную функцию msgrcv()
int msgrcv(int msqid, struct msgbuf *msgp, int msgsz, long mtype, int msgflg)
где msgp указатель на буфер, в котором мы будем читать сообщения, а mtype определяет список интересующих нас сообщений.
Удаление очереди осуществляется вызовом функции msgctl() с флагом
IPC_RMID
msgctl(qid, IPC_RMID, 0)
В следующем примере создается очередь сообщений, затем в нее посылается сообщение и далее происходит считывание сообщения; таким образом можно проконтролировать корректную работу системы.
--------------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <linux/ipc.h>
#include <linux/msg.h>
/* Redefines the struct msgbuf */
typedef struct mymsgbuf
{
long mtype;
int int_num;
float float_num;
char ch;
} mess_t;
int main()
{
int qid;
key_t msgkey;
mess_t sent;
mess_t received;
int length;
/* Initializes the seed of the pseudo-random number generator */
srand (time (0));
/* Length of the message */
length = sizeof(mess_t) - sizeof(long);
msgkey = ftok(".",'m');
/* Creates the queue*/
qid = msgget(msgkey, IPC_CREAT | 0660);
printf("QID = %d\n", qid);
/* Builds a message */
sent.mtype = 1;
sent.int_num = rand();
sent.float_num = (float)(rand())/3;
sent.ch = 'f';
/* Sends the message */
msgsnd(qid, &sent, length, 0);
printf("MESSAGE SENT...\n");
/* Receives the message */
msgrcv(qid, &received, length, sent.mtype, 0);
printf("MESSAGE RECEIVED...\n");
/* Controls that received and sent messages are equal */
printf("Integer number = %d (sent %d) -- ", received.int_num,
sent.int_num);
if(received.int_num == sent.int_num) printf(" OK\n");
else printf("ERROR\n");
printf("Float numero = %f (sent %f) -- ", received.float_num,
sent.float_num);
if(received.float_num == sent.float_num) printf(" OK\n");
else printf("ERROR\n");
printf("Char = %c (sent %c) -- ", received.ch, sent.ch);
if(received.ch == sent.ch) printf(" OK\n");
else printf("ERROR\n");
/* Destroys the queue */
msgctl(qid, IPC_RMID, 0);
}
--------------------------------------------------------------
в следующем примере создается два взаимодействующих через очередь сообщений процесса. При этом значения всех переменных родительского процесса переходят к порожденному (memory copy). Это означает, что необходимо создать очередь до порождения, чтобы и процесс-родитель и процесс-потомок могли знать идентификатор очереди и обращаться к ней.
Что происходит в этой небольшой программе: посредством очереди порожденный процесс пересылает данные процессу потомку – порожденный процесс генерирует случайные числа и пересылает их процессу родителю и они оба выводят их в стандартный поток вывода.
--------------------------------------------------------------
#include <stdio.h>
#include <stdlib.h>
#include <linux/ipc.h>
#include <linux/msg.h>
#include <sys/types.h>
/* Redefines the message structure */
typedef struct mymsgbuf
{
long mtype;
int num;
} mess_t;
int main()
{
int qid;
key_t msgkey;
pid_t pid;
mess_t buf;
int length;
int cont;
length = sizeof(mess_t) - sizeof(long);
msgkey = ftok(".",'m');
qid = msgget(msgkey, IPC_CREAT | 0660);
if(!(pid = fork())){
printf("SON - QID = %d\n", qid);
srand (time (0));
for(cont = 0; cont < 10; cont++){
sleep (rand()%4);
buf.mtype = 1;
buf.num = rand()%100;
msgsnd(qid, &buf, length, 0);
printf("SON - MESSAGE NUMBER %d: %d\n", cont+1, buf.num);
}
return 0;
}
printf("FATHER - QID = %d\n", qid);
for(cont = 0; cont < 10; cont++){
sleep (rand()%4);
msgrcv(qid, &buf, length, 1, 0);
printf("FATHER - MESSAGE NUMBER %d: %d\n", cont+1, buf.num);
}
msgctl(qid, IPC_RMID, 0);
return 0;
}
--------------------------------------------------------------
2. Модель памяти Linux
Операционная система Linux использует монолитный подход, при котором определяется набор примитивов или системных вызовов для реализации служб операционной системы, таких как управление процессами, параллельная работа и управление памятью, в нескольких модулях, работающих в режиме супервизора. И хотя Linux в целях совместимости поддерживает модель модуля управления сегментами (segment control unit) как символическое представление, она использует эту модель на минимальном уровне.
Основными задачами управления памятью являются:
· управление виртуальной памятью – логический уровень между запросами памяти в приложениях и физической памятью;
· управление физической памятью;
· управление виртуальной памятью на уровне ядра (модуль ядра, занимающийся распределением памяти – компонент, который пытается удовлетворить запросы к памяти). Запрос может быть выполнен из ядра или из программы пользователя;
· управление виртуальным адресным пространством;
· свопинг и кэширование.
1. Общая модель модуля управления сегментами и ее особенности в Linux.
2. Общая модель управления страницами памяти и ее особенности в Linux.
3. Физические детали области памяти.
Архитектура памяти x86
В x86-архитектуре память разделяется на три типа адресов:
Логический адрес – адрес расположения ячейки памяти, который может быть (но может и нет) связан непосредственно с физическим расположением. Логический адрес обычно используется при запросе информации из контроллера.
Линейный адрес (или линейное адресное пространство) – это память, адресация которой начинается с 0. Каждый следующий байт адресуется следующим последовательным номером (0, 1, 2, 3 и т.д.) до конца памяти. Так адресуют память большинство CPU не Intel-архитектуры. В Intel®-архитектурах используется сегментированное адресное пространство, в котором память разделяется на сегменты размером 64KB, а сегментный регистр всегда указывает на базовый адрес адресуемого сегмента. 32-битный режим в этой архитектуре рассматривается как линейное адресное пространство, но в нем тоже используются сегменты.
Физический адрес – адрес, представленный битами физической адресной шины. Физический адрес может отличаться от логического; в этом случае модуль управления памятью транслирует логический адрес в физический.
В Linux все сегментные регистры указывают на один и тот же диапазон адресов сегментов (рис.1) – другими словами, каждый использует один и тот же набор линейных адресов. Это позволяет Linux использовать ограниченное число дескрипторов сегментов, то есть, все дескрипторы могут храниться в GDT. Двумя преимуществами этой модели являются:
· управление памятью проще при использовании всеми процессами одинаковых значений сегментных регистров (когда они совместно используют одинаковый набор линейных адресов);
· может быть достигнута совместимость с большинством архитектур. Некоторые RISC-процессоры тоже поддерживают такой ограниченный метод сегментирования.
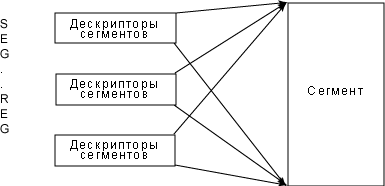
Рисунок 1. В Linux сегментные регистры указывают на один и тот же набор адресов
Дескрипторы сегментов
Linux использует следующие дескрипторы сегментов:
· Сегмент кода ядра
· Сегмент данных ядра
· Сегмент кода пользователя
· Сегмент данных пользователя
· Сегмент TSS
· Сегмент LDT по умолчанию
Дескриптор сегмента кода ядра в GDT имеет следующие значения:
· Base = 0x00000000
· Limit = 0xffffffff (232-1) = 4GB
· G (флаг единицы сегментирования) = 1 для размера сегмента, выраженного в страницах
· S = 1 для обычного сегмента кода или данных
· Type = 0xa для сегмента кода, который можно прочитать и выполнить
· Значение DPL = 0 для режима ядра
Линейный адрес для этого сегмента равен 4 GB. S =1 и type = 0xa обозначают сегмент кода. Селектор находится в регистре cs. Доступ к соответствующему селектору сегмента в Linux осуществляется через макрос _KERNEL_CS.
Дескриптор сегмента данных ядра имеет аналогичные значения за исключением поля Type, значение которого установлено в 2. Это указывает на то, что сегмент является сегментом данных и селектор хранится в регистре ds. Доступ к соответствующему селектору сегмента в Linux осуществляется через макрос _KERNEL_DS.
Сегмент кода пользователя используется совместно всеми процессами в пользовательском режиме. Соответствующий дескриптор сегмента, хранящийся в GDT, имеет следующие значения:
· Base = 0x00000000
· Limit = 0xffffffff
· G = 1
· S = 1
· Type = 0xa для сегмента кода, который можно прочитать и выполнить
· DPL = 3 для пользовательского режима
Доступ к соответствующему селектору сегмента в Linux осуществляется через макрос _USER_CS.
В дескрипторе сегмента данных пользователя есть только одно изменение по сравнению с предыдущим дескриптором - поле Type установлено в 2 и определяет сегмент данных, которые можно прочитать и записать. Доступ к соответствующему селектору сегмента в Linux осуществляется через макрос _USER_DS.
Кроме этих дескрипторов сегментов GDT содержит два дополнительных дескриптора сегментов для каждого созданного процесса - для сегментов TSS и LDT.
Каждый дескриптор сегмента TSS указывает на отдельный процесс. TSS хранит информацию об аппаратном контексте для каждого CPU, который принимает участие в переключении контекста. Например, при переключении режимов U->K x86 CPU получает адрес стека режима ядра из TSS.
Каждый процесс имеет свой собственный TSS-дескриптор, хранящийся в GDT. Значения этого дескриптора таковы:
· Base = &tss (адрес поля TSS дескриптора соответствующего процесса; например, &tss_struct), который определен в файле schedule.h ядра Linux
· Limit = 0xeb (сегмент TSS занимает 236 байт)
· Type = 9 или 11
· DPL = 0. Пользовательский режим не обращается к TSS. Флаг G очищен
Все процессы совместно используют сегмент LDT по умолчанию. По умолчанию он содержит нулевой дескриптор сегмента. Этот дескриптор сегмента LDT по умолчанию хранится в GDT. Сгенерированный ядром Linux LDT занимает 24 байта. По умолчанию всегда присутствуют три записи:
LDT[0] = null
LDT[1] = сегмент кода пользователя
LDT[2] = дескриптор сегмента данных/стека пользователя
Вычисление TASKS
Знание NR_TASKS (переменной, определяющей количество одновременных процессов, поддерживаемых в Linux. Ее значение по умолчанию в исходном коде ядра равно 512, что позволяет иметь 256 одновременных подключений к одному экземпляру) необходимо для вычисления максимального количества разрешенных записей в GDT.
Максимальное количество разрешенных в GDT записей может быть определено по следующей формуле:
Общее количество записей в GDT = 12 + 2 * NR_TASKS.
Возможное количество записей в GDT = 2^13 -1 = 8192.
Из 8192 дескрипторов сегментов Linux использует 6 дескрипторов сегментов, еще 4 дополнительных для APM-функций (функции расширенного управления питанием), а 4 записи в GDT остаются не использованными. Таким образом, конечное число возможных записей в GDT равно 8192 - 14, или 8180.
В любой момент времени нельзя иметь более чем 8180 записей в GDT, следовательно:
2 * NR_TASKS = 8180 и NR_TASKS = 8180/2 = 4090
Модель разбиения на страницы в Linux
Разбиение на страницы в Linux аналогично обычному разбиению, но x86-архитектура имеет трехуровневый табличный механизм, состоящий из (рис.2):
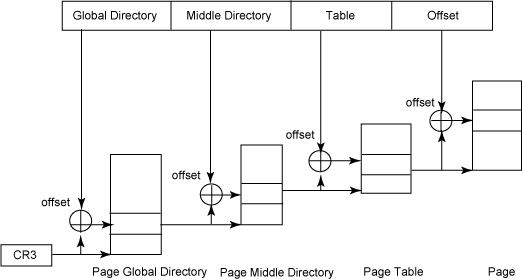
Рис. 2. Три уровня разбиения на страницы
· Page Global Directory (pgd - глобальный каталог страниц), абстрактный верхний уровень многоуровневых таблиц страниц. Каждый уровень таблицы страниц имеет дело с различными размерами памяти - этот глобальный каталог может работать с областями размером 4 MB. Каждая запись будет являться указателем на более низкоуровневую таблицу каталогов меньшего размера, то есть pgd - это каталог таблиц страниц. Когда код проходит эту структуру (это делают некоторые драйверы), говорится, что выполняется "проход" по таблицам страниц.
· Page Middle Directory (pmd - промежуточный каталог страниц), промежуточный уровень таблиц страниц. На x86-архитектуре pmd не представлен аппаратно, но входит в pgd в коде ядра.
· Page Table Entry (pte - запись таблицы страниц), нижний уровень, работающий со страницами напрямую (ищите PAGE_SIZE), является значением, которое содержит физический адрес страницы вместе со связанными битами, указывающими, например, что запись корректна, и соответствующая страница присутствует в реальной памяти.
Эта трехуровневая схема разбиения на страницы также реализована в Linux для поддержки областей памяти больших размеров. Если поддержка больших областей памяти не требуется, вы можете вернуться к двухуровневой схеме, установив pmd в "1".
Эти уровни оптимизируются во время компиляции, разрешая второй и третий уровни (с использованием того же самого набора кода) простым разрешением или запретом промежуточного каталога. 32-битные процессоры используют pmd-разбиение, а 64-битые используют pgd-разбиение.
В 64-битных процессорах:
· 21 бит MSB не используются
· 13 бит LSB представлены смещением страницы
· Оставшиеся 30 бит разделены на
o 10 бит для Page Table
o 10 бит для Page Global Directory
o 10 бит для Page Middle Directory
Как видно из архитектуры, для адресации фактически используются 43 бита. То есть, на 64-битных процессорах реально доступно 2 в степени 43 ячеек виртуальной памяти.
Каждый процесс имеет свой собственный набор каталогов страниц и таблиц страниц. Для обращения к страничному фрейму с реальными пользовательскими данными операционная система начинает с загрузки (на x86-архитектурах) pgd в регистр cr3. Linux сохраняет в TSS-сегменте содержимое регистра cr3 и затем загружает другое значение из TSS-сегмента в регистр cr3 каждый раз во время выполнения нового процесса в CPU. В результате модуль разбиения на страницы ссылается на корректный набор таблиц страниц.
Каждая запись в таблице pgd указывает на страничный фрейм, содержащий массив записей pmd, которые, в свою очередь, указывают на страничный фрейм, содержащий pte, который, наконец, указывает на страничный фрейм, содержащий пользовательские данные. Если искомая страница находится в файле подкачки, в таблице pte сохраняется запись файла подкачки, которая используется (при ошибке отсутствия страницы) при поиске страничного фрейма для загрузки в память.
На рисунке 3 показано, что мы добавляем смещение на каждом уровне таблиц страниц для отображения на соответствующую запись страничного фрейма. Эти смещения мы получаем, разбив линейный адрес, принятый из модуля сегментации. Для разбиения линейного адреса, соответствующего каждому компоненту таблицы страниц, в ядре используются различные макросы. Не рассматривая детально эти макросы, давайте посмотрим на схему разбиения линейного адреса.

Рисунок 3. Линейные адреса имеют различные размеры
Резервные страничные фреймы
Linux резервирует несколько станичных фреймов для кода ядра и структур данных. Эти страницы никогда не сбрасываются в файл подкачки на диск. Линейные адреса с 0x0 до 0xc0000000 (PAGE_OFFSET) используются кодом пользователя и кодом ядра. Адреса с PAGE_OFFSET до 0xffffffff используются кодом ядра.
Это означает, что из 4 GB только 3 GB доступны для пользовательского приложения.
Как разрешается разбиение на страницы
Механизм разбиения на страницы, используемый процессами Linux, имеет две фазы:
· Во время начальной загрузки система устанавливает таблицу страниц для 8 MB физической памяти.
· Затем вторая фаза завершает отображение для оставшейся физической памяти.
В фазе первоначальной загрузки за инициализацию разбиения на страницы отвечает вызов startup_32(). Эта функция реализована в файле arch/i386/kernel/head.S. Отображение этих 8 MB происходит с адреса выше PAGE_OFFSET. Инициализация начинается со статически определенного во время компиляции массива, называемого swapper_pg_dir. Во время компиляции он размещается по конкретному адресу (0x00101000).
Определяются записи для двух таблиц, определенных в коде статически - pg0 и pg1. Размер этих страничных фреймов по умолчанию равен 4 KB, если не установлен бит расширения размера страниц (page size extension) (дополнительная информация по PSE находится в разделе "Расширенное разбиение на страницы"). Тогда размер каждой равен 4 MB. Адрес данных, указываемый глобальным массивом, сохраняется в регистре cr3, что, я полагаю, является первым этапом установки модуля разбиения на страницы для процессов Linux. Остальные страничные записи устанавливаются во второй фазе.
Вторая фаза реализована в методе paging_init().
Отображение RAM выполняется между PAGE_OFFSET и адресом, представляющим границу 4 GB (0xFFFFFFFF) в 32-битной x86-архитектуре. Это означает, что RAM размером примерно в 1 GB может быть отображена при загрузке Linux, и это происходит по умолчанию. Однако, если установить HIGHMEM_CONFIG, то физическая память размером более 1 GB может быть отображена для ядра - имейте в виду, что это временная мера. Это делается вызовом kmap().
Зона физической памяти
Я уже показал вам, что ядро Linux (на 32-битной архитектуре) делит виртуальную память в отношении 3:1 - 3 GB виртуальной памяти для пространства пользователя и 1 GB для пространства ядра. Код ядра и его структуры данных должны размещаться в этом 1 GB адресного пространства, но даже еще большим потребителем этого адресного пространства является виртуальное отображение физической памяти.
Это происходит потому, что ядро не может манипулировать памятью, если она не отображена в его адресное пространство. Таким образом, максимальным количеством физической памяти, которое может обработать ядро, является объем памяти, который мог бы отобразиться в виртуальное адресное пространство ядра минус объем, необходимый для отображения самого кода ядра. В итоге Linux на основе x86-системы смогла бы работать с объемом менее 1 GB физической памяти. И это максимум.
Поэтому, для обслуживания большого количества пользователей, для поддержки большего объема памяти, для улучшения производительности и для установки архитектурно-независимого способа описания памяти модель памяти Linux должна была совершенствоваться. Для достижения этих целей в более новой модели каждому CPU был назначен свой банк памяти. Каждый банк называется узлом; каждый узел разделяется на зоны. Зоны (представляющие диапазоны памяти) далее разбивались на следующие типы:
· ZONE_DMA (0-16 MB): Диапазон памяти, расположенный в нижней области памяти, чего требуют некоторые устройства ISA/PCI.
· ZONE_NORMAL (16-896 MB): Диапазон памяти, который непосредственно отображается ядром в верхние участки физической памяти. Все операции ядра могут выполняться только с использованием этой зоны памяти; таким образом, это самая критичная для производительности зона.
· ZONE_HIGHMEM (896 MB и выше): Оставшаяся доступная память системы не отображается ядром.
Концепция узла реализована в ядре при помощи структуры struct pglist_data. Зона описывается структурой struct zone_struct. Физический страничный фрейм представлен структурой struct Page, и все эти структуры хранятся в глобальном массиве структур struct mem_map, который размещается в начале NORMAL_ZONE. Эти основные взаимоотношения между узлом, зоной и страничным фреймом показаны на рисунке 4.
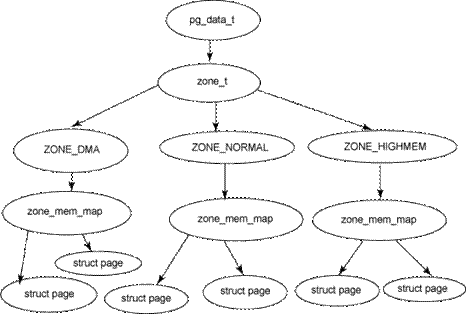
Рисунок 4. Взаимоотношения между узлом, зоной и страничным фреймом
Зона верхней области памяти появилась в системе управления памятью ядра тогда, когда были реализованы расширение виртуальной памяти Pentium II (для доступа к 64 GB памяти средствами PAE - Physical Address Extension - на 32-битных системах) и поддержка 4 GB физической памяти (опять же, на 32-битных системах). Эта концепция применима к платформам x86 и SPARC. Обычно эти 4 GB памяти делают доступными отображение ZONE_HIGHMEM в ZONE_NORMAL посредством kmap(). Обратите внимание, пожалуйста, на то, что не желательно иметь более 16 GB RAM на 32-битной архитектуре даже при разрешенном PAE.
(PAE - разработанное Intel расширение адресов памяти, разрешающее процессорам увеличить количество битов, которые могут быть использованы для адресации физической памяти, с 32 до 36 через поддержку в операционной системе приложений, использующих Address Windowing Extensions API.)
Управление этой зоной физической памяти выполняется распределителем (allocator) зоны. Он отвечает за разделение памяти на несколько зон и рассматривает каждую зону как единицу для распределения. Любой конкретный запрос на распределение использует список зон, в которых распределение может быть предпринято, в порядке от наиболее предпочтительной к наименее предпочтительной.
Например:
· Запрос на пользовательскую страницу должен быть сначала заполнен из "нормальной" зоны (ZONE_NORMAL);
· если завершение неудачно - с ZONE_HIGHMEM;
· если опять неудачно - с ZONE_DMA.
Список зон для такого распределения состоит из зон ZONE_NORMAL, ZONE_HIGHMEM и ZONE_DMA в указанном порядке. С другой стороны, запрос DMA-страницы может быть выполнен из зоны DMA, поэтому список зон для таких запросов содержит только зону DMA.
| <== предыдущая лекция | | | следующая лекция ==> |
| Создание тестовой страницы | | | Сохранность и защита программных систем |
Дата добавления: 2017-11-04; просмотров: 485;