Сохранность и защита программных систем
1. Формулировка задачи
Идеальная система безопасности должна обеспечивать полностью прозрачный санкционированный доступ к данным и непреодолимые трудности при попытках доступа несанкционированного. Кроме того, она должна предоставлять легкую и гибкую систему управления санкциями; во многих случаях бывает также полезно отслеживать все попытки несанкционированного доступа.
Понимаемая таким образом идеальная система безопасности, по-видимому, физически не реализуема. В лучшем случае удается исключить отдельные способы, но для идеального решения задачи это нужно сделать по отношению ко всем способам получения несанкционированного доступа. На практике обычно исходят из требований "разумной достаточности" или экономической целесообразности: с одной стороны, стоимость установки и эксплуатации систем безопасности не должна превосходить ценности защищаемых данных. С другой, "экономически идеальная" система безопасности должна быть достаточно сложной, для того чтобы выгоды потенциального взломщика от получения доступа были ниже затрат на преодоление защиты.
Несмотря на все методологические и практические сложности, с которыми сопряжено применение экономической оценки к системам безопасности, по крайней мере, некоторые практически важные рекомендации этот подход нам может дать.
Во-первых, мы можем утверждать, что хорошая система безопасности должна быть сбалансированной, причем прежде всего с точки зрения взломщика: стоимости всех мыслимых путей получения доступа к системе должны быть сопоставимы. И, наоборот, должны быть сопоставимы стоимости мероприятий по обеспечению защиты от проникновения разными способами. Бессмысленно ставить бронированные ворота в сочетании с деревянным забором.
Вторая полезная рекомендация – если это оправданно по стоимостным показаниям, делать системы безопасности многослойными или, используя военную терминологию, эшелонированными. Пройдя внешний слой защиты (например, преодолев брандмауэр и установив прямое соединение с одним из серверов приватной сети компании), взломщик должен получать доступ не непосредственно к данным, а лишь к следующему слою защиты (например, средствам аутентификации ОС или серверного приложения).
Третья рекомендация в известной мере противоречит двум предыдущим и гласит, что учитывая компоненты стоимости эксплуатации системы безопасности, нельзя забывать о тех действиях, которые эта система требует от сотрудников организации. Если требования безопасности чрезмерно обременительны для них, то они могут попытаться осуществить операцию, которую в неоклассической экономике называют экстернализацией издержек (например, выдвинуть ультимативное требование – либо вы снимаете наиболее раздражающие из требований, либо повышаете зарплату, либо мы все уволимся).
2. Сессии и идентификаторы пользователя
Как правило, далеко не каждая авторизация отдельных операций сопровождается актом аутентификации. Чаше всего используется принцип сессий работы с вычислительной системой. В начале работы пользователь устанавливает соединение и "входит" в систему. При "входе" происходит его аутентификация.
Для того чтобы быть аутентифицированным, пользователь должен иметь учетную запись (account) в системной базе данных. Затем пользователь проводит сеанс работы с системой, а по завершении этого сеанса аннулирует регистрацию.
Одним из атрибутов сессии является идентификатор пользователя (user id) или контекст доступа (security context), который и используется при последующих авторизациях. Обычно такой идентификатор имеет две формы: числовой код, применяемый внутри системы, и мнемоническое символьное имя, используемое при общении с пользователем.
Сессии в Unix-системах пользователь идентифицируется целочисленным значением uid (user identifier). С каждой задачей (процессом) связано два идентификатора пользователя: реальный и эффективный. В большинстве случаев эти идентификаторы совпадают. Таким образом, каждая задача обязательно исполняется от имени того или иного пользователя, имеющего учетную запись в системе.
Пользователь может иметь также символьное имя. В старых Unix системах соответствие между символьным и числовым идентификаторами устанавливалось на основе содержимого текстового файла /etc/passwd. Каждая строка этого файла описывает одного пользователя и состоит из семнадцати полей, разделенных символом ':'. В первом поле содержится символьное имя пользователя, во втором — числовой идентификатор в десятичной записи. Остальные поля содержат другие сведения о пользователе, например, его полное имя.
Пользовательские программы могут устанавливать соответствие между числовым и символьным идентификаторами самостоятельно, путем просмотра файла /etc/passwd, или использовать библиотечные функции, определенные стандартом POSIX. Во многих реализациях эти функции используют вместо /etc/passwd индексированную базу данных, а сам файл /etc/passwd сохраняется лишь для совместимости со старыми программами.
В современных системах семейства Unix библиотеки работы со списком пользователей имеют модульную архитектуру и могут использовать различные, в том числе и распределенные по сети базы данных. Интерфейс модуля работы с конкретным типом БД называется РАМ (Person Autentification Module – модуль аутентификации людей).
Причем соответствие между символьным и числовым идентификаторами в Unix не является взаимно однозначным. Одному и тому же числовому идентификатору может соответствовать несколько имен. Кроме того, в Unix разрешено создать объекты с числовым uid, которому не соответствует никакое символьное имя.
Большинство современных ОС позволяют также запускать задания без входа систему и создания сессии. В Windows NT/2000/XP задачи, которые могут запускаться и работать без входа пользователя в систему, называются сервисами. По умолчанию, сервисы запускаются от имени специального [псевдо] пользователя System, но в свойствах сервиса можно указать, от чьего имени он будет запускаться. Кроме того, некоторые комплектации системы (Terminal Server Edition, Citrix ICA) допускают одновременную интерактивную работу нескольких пользователей. Чтобы обеспечить разделение доступа во всех этих случаях, каждый процесс в системе имеет контекст доступа (security context), соответствующий той или иной учетной записи.
3. Аутентификация
По-английски процесс входа в систему называется login (log in) и происходит от слова log, которое обозначает регистрационный журнал или процесс записи в такой журнал. В обычном английском языке такого слова нет, но в компьютерной лексике слова login и logout прижились очень прочно. Наиболее точным переводом слова login является регистрация. Соответственно, процесс выхода называется logout. Его точная русскоязычная калька – разрегистрация. Теоретически можно придумать много разных способов идентификации, например, с использованием механических или электронных ключей или даже тех или иных биологических параметров, например, рисунка глазного дна. Однако подобные способы требуют специальной и зачастую довольно дорогой аппаратуры. Наиболее широкое распространение получил более простой метод, основанный на символьных паролях.
Пароль представляет собой последовательность символов. Предполагается, что пользователь запоминает ее и никому не сообщает. Этот метод ряд недостатков. Использование паролей основано на следующих трех предположениях:
· пользователь может запомнить пароль;
· никто не сможет догадаться, какой пароль был выбран;
· пользователь никому не сообщит свой пароль.
Количество легко запоминаемых паролей ограничено и перебрать все такие пароли оказывается не так уж сложно. Этот вид атаки на систему безопасности известен как словарная атака (dictionary attack) и при небрежном отношении пользователей к выбору паролей и в ряде других ситуаций представляет большую опасность.
Второй слой защиты заключается в том, чтобы усложнить пароль и тем самым увеличить количество вариантов. Даже очень простые усложнения сильно увеличивают перебор. Так, простое требование использовать в пароле буквы и верхнего, и нижнего регистров увеличивает перебор в 2n раз где n – длина пароля.
Наконец, последний слой защиты – это оповещение пользователя (а иногда и администратора системы) о неудачных попытках входа. Если пользователь сам только что нажал не ту кнопку, он при входе увидит, что была одна неудачная попытка, и не будет волноваться; однако, если есть сообщения о дополнительных неудачных попытках, время побеспокоиться и разобраться, что же происходит. При использовании паролей возникает отдельная проблема безопасного хранения базы данных со значениями паролей. Как правило, даже администратор системы не может непосредственно получить значения паролей пользователей.
Для обеспечения секретности паролей обычно используют одностороннее шифрование, или хэширование, при котором по зашифрованному значению нельзя восстановить исходное слово. При этом программа аутентификации кодирует введенный пароль и сравнивает полученное значение (хэш) с хранящимся в базе данных. Существует много алгоритмов хэширования, при использовании которых узнать реальное значение пароля можно только путем полного перебора всех возможных вариантов и сравнения зашифрованной строки со значением в базе данных.
В старых системах семейства Unix пароль использовался в качестве ключа шифрования фиксированной строки алгоритмом DES. Этот алгоритм ограничивает длину ключа 64 битами, соответственно пароли в таких системах могут содержать не более 8 символов. Современные системы используют алгоритм MD5 [RFC 1321], который допускает пароли практически неограниченной длины. Этот алгоритм специально разрабатывался с целью максимального усложнения задачи построения сообщения с заданным значением хэша.
Практически все современные системы хранят данные о паролях в односторонне зашифрованном виде в файле, недоступном для чтения обычным пользователям. Поставщики некоторых систем, например Windows NT/2000/XP, даже отказываются публиковать информацию о формате этой базы данных, хотя это само по себе вряд ли способно помешать квалифицированному взломщику.
Аутентификация в сети
Когда пользователь работает с консоли компьютера или с терминала, физически прикрепленного к терминальному порту, модель сессий является вполне приемлемой. При регистрации пользователя создается сессия, ассоциированная с данным терминалом, и далее проблем нет. Аналогично нет никаких проблем при подключении через сеть с коммутацией каналов, например, при "дозвоне" через модем, подключенный к телефонной сети. Когда соединение разрывается, сессия считается оконченной.
В сетях с коммутацией пакетов, к которым относится большинство современных сетевых протоколов (TCP/IP, IPX/SPX, ISO/OSI и т. д.), вообще нет физического понятия соединения. В лучшем случае сетевой протокол предоставляет возможность создавать виртуальные соединения с "надежной" связью, в которых гарантируется отсутствие потерь пакетов и сохраняется порядок их поступления. С таким виртуальным соединением вполне можно ассоциировать сессию, как это сделано в протоколах telnet, rlogin/rsh и ftp.
Протокол telnet
Протокол telnet используется для эмуляции алфавитно-цифрового терминала через сеть. Пользователь устанавливает соединение и регистрируется в удаленной системе таким же образом, как он регистрировался бы с физически подключенного терминала. Например, в системах семейства Unix создается виртуальное устройство, псевдотерминал (pseudotermina/) /dev/ptyXX, полностью эмулирующее работу физического терминала, и система запускает ту же программу идентификации пользователя /bin/login, которая используется для физических терминалов. При окончании сессии соединение разрывается и псевдотерминальное устройство освобождается.
Обычно для автоматической регистрации используется модель доверяемых систем (trusted hosts). Если система В доверяет системе А, то все пользователи, зарегистрированные на системе А, автоматически получают доступ к системе В под теми же именами (рис. 1). Иногда аналогичную возможность можно предоставлять каждому пользователю отдельно – он сообщает, что при регистрации входа из системы А пароля запрашивать не надо. Разновидностью модели доверяемых систем можно считать единую базу учетных записей, разделяемую между машинами.
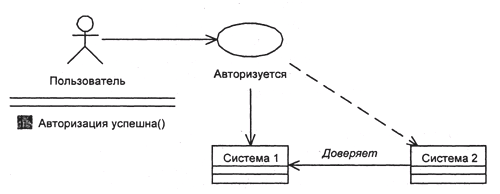
Рис. 2. Доверяемые системы
Межмашинное доверие в rlogin/rsh
Протоколы rlogin/rsh, обеспечивающие запуск отдельных команд или командного процессора на удаленной системе, используют файл /etc/hosts.equiv или .rhosts в домашнем каталоге пользователя на удаленной системе. Файл /etc/hosts.equiv содержит имена всех машин, которым наша система полностью доверяет. Файл .rhosts состоит из строк формата имя.удаленной.машины имя пользователя При этом имя.удаленной.машины не может быть произвольным, оно обязано содержаться в файле /etc/hosts, в котором собраны имена и адреса всех удаленных машин, "известных" системе. То же требование обязательно и для машин, перечисленных в /etc/hosts.equiv.
Модель доверяемых систем обеспечивает большое удобство для пользователей и администраторов и в различных формах предоставляется многими сетевыми ОС. Например, в протоколе разделения файлов SMB. применяемом в системах семейства СР/М, Linux и др., используется своеобразная модель аутентификации, которую можно рассматривать как специфический случай доверяемых систем.
Аутентификация SMB
Аутентификация в SMB основана на понятии домена (domain). Каждый разделяемый ресурс (каталог, принтер и т. д.) принадлежит к определенному домену, хотя и может быть защищен собственным паролем. При доступе к каждому новому ресурсу необходимо подтвердить имя пользователя и пароль, после чего создается сессия, связанная с этим ресурсом. Для создания сессии используется надежное соединение, предоставляемое транспортным протоколом, - именованная труба NetBEUI или сокет TCP. Ввод пароля при каждом доступе неудобен для пользователя, поэтому большинство клиентов – просто запоминают пароль, введенный при регистрации в домене, и при подключении к ресурсу первым делом пробуют его. Благодаря этому удается создать у пользователя иллюзию однократной регистрации. Кроме того, если сессия по каким-то причинам оказалась разорвана, например, из-за перезагрузки сервера, то можно реализовать прозрачное для пользователя восстановление этой сессии. С точки зрения клиента нет смысла говорить о межмашинном доверии – клиенту в среде SMB никто не доверяет и вполне справедливо: обычно это система класса ДОС, не заслуживающая доверия. Однако серверы обычно передоверяют проверку пароля и идентификацию пользователя выделенной машине, называемой контроллером домена (domain controller). Домен обязан иметь один основной (primary) контроллер и может иметь несколько резервных (backup), каждый из которых хранит реплики (периодически синхронизуемые копии) базы учетных записей. При поступлении запроса на соединение сервер получает у клиента имя пользователя и пароль, но вместо сверки с собственной базой данных он пересылает их контроллеру домена и принимает решение о принятии или отказе в аутентификации на основании вердикта, вынесенного контроллером.
Только контроллеры домена хранят у себя базу данных о пользователях и паролях. При этом основной контроллер хранит основную копию базы, а резервные серверы – ее дубликаты, используемые лишь в тех случаях, когда основной сервер выключен или потерян. Благодаря тому, что все данные собраны в одном месте, можно централизованно управлять доступом ко многим серверам, поэтому домены представляют неоценимые преимущества при организации больших многосерверных сетей.
С точки зрения безопасности доверяемые системы имеют два серьезных недостатка.
1. Прорыв безопасности на одной из систем означает, по существу, прорыв на всех системах, которые доверяют первой (рис. 2).
2. Возникает дополнительный тип атаки на систему безопасности: машина, которая выдает себя за доверяемую, но не является таковой (рис. 3).
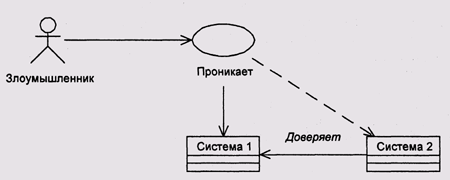
Рис. 2. Прорыв безопасности в сети с доверяемыми системами
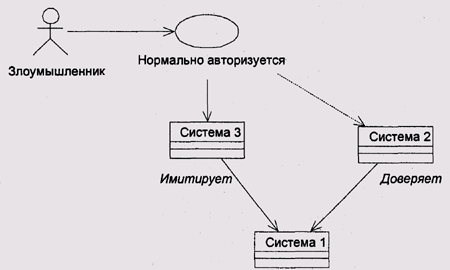
Рис. 3. Имитация доверяемой системы
Первая проблема является практически неизбежной платой за разрешение автоматической регистрации. Вторая проблема может быть отчасти решена использованием средств, предоставляемых сетевыми протоколами, например, привязкой всех логических имен доверяемых систем к их сетевым адресам канального уровня. В протоколах TCP/IP это может быть сделано с использованием протокола аrр (Address Resolution Protocol – протокол разрешения адресов), однако надежда на это слаба: многие сетевые карты имеют настраиваемые адреса, а многие реализации сетевых протоколов допускают отправку пакетов с поддельным адресом отправителя.
Более изощренный и намного более надежный метод основан на использовании алгоритма двухключевого шифрования RSA или родственных ему механизмов.
Криптографические методы аутентификации
Многие системы аутентификации используют для самой аутентификации или представления контекста доступа алгоритм шифрования с открытым ключом RSA. Способы аутентификации, основанные на RSA, сводятся к следующему алгоритму.
· Система А генерирует последовательность байтов, обычно случайную, кодирует ее своим ключом и посылает системе В.
· Система В раскодирует ее своим ключом. Это возможно, только если системы владеют парными ключами.
· Системы тем или иным способом обмениваются "правильными" значениями зашифрованной посылки.
Аутентификация SSH
Для примера рассмотрим принцип RSA-аутентификации в пакете ssh – Secure Shell. Пакет представляет собой функциональную замену программ rlogin/rsh и соответствующего этим программам демона rshd. В пакет входят программы ssh (клиент) и sshd (сервер), а также утилиты для генерации ключей RSA и управления ими. ssh использует RSA для прозрачной аутентификации пользователя при входе в удаленную систему. Кроме того, ssh/sshd могут осуществлять шифрование данных, передаваемых по линии во время сеанса связи и выполнять ряд других полезных функций. Сервер хранит список известных общедоступных ключей для каждого из пользователей в файле SHOME/.ssh/authorized_keys, где $НОМЕ обозначает домашний каталог пользователя. Файл состоит из строк формата host_name: key – по строке для каждого из разрешенных клиентов. В свою очередь, каждый клиент хранит в файле $HOME/.ssh/private_key свой приватный ключ.
Когда из удаленной системы-клиента приходит запрос на аутентификацию, sshd запрашивает публичный ключ. Если полученный ключ совпадает с хранящимся в файле значением для этой системы, сервер генерирует случайную последовательность из 256 бит, шифрует ее публичным ключом и посылает клиенту. Клиент расшифровывает посылку своим личным ключом, вычисляет 128-битовую контрольную сумму и возвращают ее серверу. Сервер сравнивает полученную последовательность с правильной контрольной суммой и принимает аутентификацию в случае совпадения (рис.4). Теоретически контрольные суммы могут совпасть и в случае несовпадения ключей, но вероятность такого события крайне мала.
Авторизация
Механизмы авторизации в различных ОС и прикладных системах различны, но их трудно назвать разнообразными. Два основных подхода к авторизации – это ACL (Access Control List, список управления доступом) или список контроля доступа и полномочия (capability).
Список контроля доступа ассоциируется с объектом или группой объектов и представляет собой таблицу, строки которой соответствуют учетным записям пользователей, а столбцы – отдельным операциям, которые можно осуществить над объектом. Перед выполнением операции система ищет идентификатор пользователя в таблице и проверяет, указана ли выполняемая операция в списке его прав.
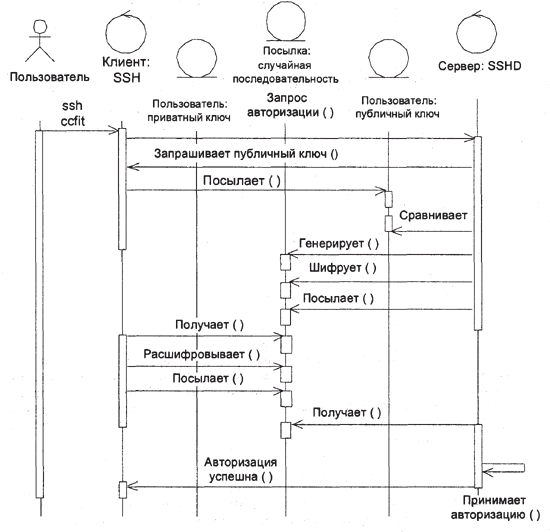
Рис. 4. Аутентификация SSH
Реализация списков управления доступом вполне прямолинейна и не представляет непреодолимых сложностей. Разработчики системы безопасности могут (и часто бывают вынуждены) предпринимать достаточно сложные меры для сокращения ACL, предлагая те или иные явные и неявные способы объединения пользователей и защищаемых объектов в группы. Полномочие представляет собой абстрактный объект, наличие которого в контексте доступа задачи позволяет выполнять ту или иную операцию над защищаемым объектом или классом объектов, а отсутствие – соответственно, не позволяет.
Типичная практически используемая архитектура управления доступом предоставляет пользователю и системному администратору управление правами в форме списков контроля доступа и содержит один или несколько простых типов полномочий, чтобы предотвратить доступ в обход этих списков. Простейшей структурой таких полномочий является разделение пользовательского и системного режимов работы процессора и исполнение всего не пользующегося доверием кода в пользовательском режиме. Системный режим процессора является полномочием или, во всяком случае, может применяться в качестве такового: обладание им позволяет выполнять операции, недопустимые в пользовательском режиме, и этот режим не может произвольно устанавливаться. Он позволяет реализовать не только ACL, но и дополнительные полномочия: пользователь не имеет доступа в системное адресное пространство, поэтому система может рассматривать те или иные атрибуты дескриптора пользовательского процесса как полномочия (рис. 5). Идентификатор пользователя, устанавливаемый при аутентификации и хранящийся в дескрипторе процесса в адресном пространстве ядра, также может рассматриваться как полномочие. Для того чтобы этот идентификатор действительно можно было использовать таким образом, необходимо ввести весьма жесткие ограничения на то, кто и каким образом может производить аутентификацию. Два подхода к решению этой задачи – это осуществление аутентификации модулями ядра и введение специального идентификатора пользователя (или специального типа процессов).
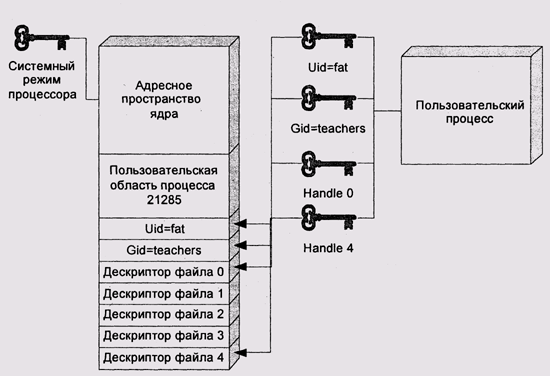
Рис. 5. Хранение полномочий в системном адресном пространстве
Включение средств аутентификации в ядро кажется весьма привлекательным: мы можем быть уверены, что никто не получит чужие полномочия, иначе как пройдя штатную процедуру проверки идентичности. С другой стороны, каждый процесс, считающий, что ему следует произвести смену идентичности (например, сервер, исполняющий запрос от имени конкретного пользователя) может запросить у пользователя имя и пароль и переау-тентифицироваться без каких-либо трудностей.
Проблема при таком подходе состоит в том, что при этом ограничиваются используемые в системе способы аутентификации и форматы пользовательской базы данных.
Разработка модулей, реализующих альтернативные способы аутентификации (например, применяющих папиллярный детектор или сканер глазного дна вместо запроса пароля) или нестандартные способы хранения списков пользователей резко усложняются – теперь это должны быть не простые разделяемые библиотеки, а модули ядра.
Ресурсные квоты
Все ресурсы, управление которыми осуществляет операционная система: дисковое пространство, оперативная память, время центрального процессора, пропускная способность внешних соединений и т.д. – с одной стороны, конечны и, таким образом, исчерпаемы, а с другой – стоят денег. Необоснованное расходование того или иного ресурса пользователем может привести к его исчерпанию и лишению других пользователей системы доступа к нему.
Стандартным способом предотвратить исчерпание ресурсов в масштабах системы является введение квот (quota) на эти ресурсы: ограничений количества ресурса, которое конкретный пользователь может занять. Иногда квоты выделяются не отдельным пользователям, а группам, но – из-за возникающей при этом проблемы разрешения ресурсных конфликтов между пользователями группы – это делается очень редко. Практически всегда квота выделяется отдельному пользователю.
Чаще всего квотированию подвергается дисковое пространство. В системах семейства Unix квотированию подлежит также количество файлов, которые могут принадлежать данному пользователю.
В системах коллективного пользования квоты устанавливаются практически на все ресурсы: объем адресного пространства и рабочего множества страниц отдельной пользовательской задачи, количество одновременно запущенных процессов, время исполнения отдельной задачи или суммарное занятое время центрального процессора и т. д. Объясняется это тем, что любой ресурс, который пользователь может занимать неограниченно, представляет собой потенциальную точку атаки на безопасность системы. На практике квоты многих ресурсов могут устанавливаться весьма высокими, так что пользователь при разумном применении системы может никогда с ними не столкнуться.
4. Типичные уязвимые места ОС
В системах общего назначения существует пять основных источников проблем безопасности:
· недостаточная аккуратность пользователей в выборе паролей, создающая условия для успешной словарной атаки, а также утечки паролей, обусловленные другими причинами, начиная от пресловутых "паролей на бумажках" и кончая шантажом пользователей и прослушиванием сети злоумышленниками;
· запуск пользователями вирусов и других троянских программ, чаще всего в составе или под видом игр;
· ошибки администратора в формировании ACL (с некоторой натяжкой сюда же можно причислить неудачные комбинации принятых в системе прав по умолчанию);
· наличие в сети ОС и приложений с неадекватными средствами обеспечения безопасности;
· ошибки в модулях самой ОС и работающих под ее управлением приложениях.
Первый источник проблем преодолим только организационными мерами, и лишь некоторые из них — например, проведение с пользователями воспитательной работы — находятся в сфере компетенции системного администратора. Исключение составляет борьба с прослушиванием сети: предотвращение технической возможности несанкционированного подключения к сети также обычно находится на грани области компетенции системного администратора, но использование шифрованных сетевых протоколов или хотя бы таких, в которых имя и пароль передаются в хэшированием виде, может значительно уменьшить пользу прослушивания для злоумышленника.
Второй источник также следует преодолевать организационными мерами. Разумной политикой, по-видимому, следует считать не полный запрет компьютерных игр, а постановку процесса под контроль путем создания легального более или менее централизованного хранилища этих игр, систематически проверяемого на предмет "заразы". Поддержание этого хранилища может выполняться как самим системным администратором, так и на общественных началах.
Третий источник проблем находится преимущественно в голове самого системного администратора. Он должен знать точную семантику записей в ACL используемой ОС, исключения из правил, хотя бы наиболее распространенные стандартные ошибки, а также то, какие и кому права даются по умолчанию.
Четвертый источник, как правило, находится вне контроля системного администратора: хотя он и может иметь право голоса в решении вопроса о судьбе таких систем, но обычно его голос не оказывается решающим. Если отсутствие или неадекватность средств безопасности в операционной системе настольного компьютера часто можно скомпенсировать, исключив хранение на нем чувствительных данных, не запуская на нем доступных извне сервисов и — в пределе — сведя его к роли малоинтеллектуального конечного устройства распределенной системы, а его локальный диск — к роли кэша программ и второстепенных данных, то с приложениями все гораздо хуже.
Наконец, пятая причина – ошибки в модулях ОС и приложениях – хотя и находится за пределами непосредственной сферы влияния системного администратора, но заслуживает более подробного обсуждения, особенно потому, что мы предназначаем нашу книгу не только эксплуатационщикам, но и разработчикам программного обеспечения.
Ошибки программирования
Наибольшую опасность с точки зрения безопасности представляют ошибки в модулях, связанных с проверкой ACL, авторизацией и повышением уровня привилегий процессора (например, в диспетчере системных вызовов), а в системах семейства Unix – в setuid-программах.
Одна из наиболее опасных – и в то же время довольно распространенная в современных программах (пример 1).
Пример 1. Пример программы, подверженной срыву стека
/* Фрагмент примитивной реализации сервера SMTP (RFC822) */
int parse_line(FILE * socket)
{
/* Согласно RFC822, команда имеет длину не более 4 байт,
а вся строка — не более 255 байт */
char cmd[5], args[255];
fscanf(socket, "%s %s\n", and, args);
/* Остаток программы нас не интересует */
Видно, что программа считывает из сетевого соединения строку, которая должна состоять из двух полей, разделенных пробелом, и заканчиваться символом перевода строки. В соответствии со спецификациями протокола SMTP, первое поле (команда) не может превышать четырех символов (к сожалению, не определено в протоколе более длинных команд), а строка целиком не может быть длиннее 255 байт.
Если партнер на другом конце соединения полностью соответствует требованиям [RFC 0822], наш код будет работать без проблем. Проблемы – причем серьезнейшие – возникнут, если будет передана строка, которая этим требованиям не соответствует.
Превышение допустимой длины кодом команды не представляет большой опасности: лишние байты будут записаны в начало массива args и потеряны при записи в него его собственного поля. Настоящая опасность – это превышение длины всей строки. Для партнера не представляет никаких сложностей сгенерировать последовательность из более чем 255 символов, не содержащую переводов строки (рис. 7).
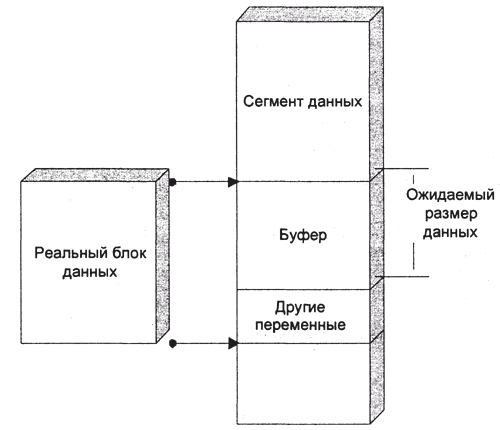
Рис. 7. Срыв буфера
Тогда буфер arg переполнится, но за ним в памяти следует вовсе не другой буфер, а – ни много, ни мало, заголовок стекового кадра, в котором содержится адрес возврата подпрограммы.
Переполнение массива arg приведет к нарушению заголовка стекового кадра. Если диверсант достаточно квалифицирован, он может передать вместо команды кусок кода и поддельный стековый кадр, который в качестве адреса возврата содержит адрес переданного кода. И тогда, при попытке возвратить управление, программа передаст управление на подставленный ей код (рис. 8).
Даже если вредитель не может передать и исполнить код (например, потому, что не знает адреса стека или потому, что стек защищен от исполнения), порчи стекового кадра достаточно, чтобы аварийно завершить исполнение сетевого сервиса, а это тоже неприятно. Ошибки такого рода называются переполнениями буфера (buffer overrun) или срывами буфера. Если буфер находится в стеке, говорят еще о срыве стека. Срывы буфера возможны не только в сетевых сервисах, но и в приложениях, просто считывающих файлы и, с другой стороны, не только в высокоуровневых сетевых сервисах, но и в драйверах сетевых протоколов нижнего уровня – последний тип ошибок особенно опасен, потому что атаке подвергается модуль ядра ОС. Особенную опасность представляет срыв буфера в модулях, осуществляющих парольную авторизацию: в этом случае злоумышленник может даже но разрушать стековый кадр, ему достаточно лишь модифицировать переменную, которая сигнализирует, что пароль успешно проверен.
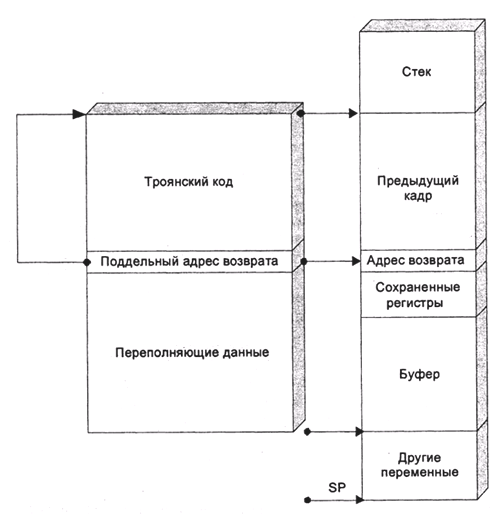
Рис. 8. Срыв стека с передачей троянского кода
Наиболее велика опасность срыва буфера в ситуациях, когда спецификация сетевого протокола или формата файла гласит, что длина того или иного поля или пакета не может превышать определенного количества байтов, однако нарушение этого правила физически возможно. Возможность такого нарушения может возникать как из-за того, что используется не счетчик байтов в пакете, а маркер конца пакета, так и из-за того, что разрядность счетчика байтов позволяет представлять значения, превышающие установленный протоколом предел.
При программировании на языке С основные источники ошибок такого рода – это использование стандартных процедур gets и fscanf. Процедура gets лечению не подлежит – ей невозможно указать размер буфера, выделенного для приема данных, поэтому она в принципе не способна проконтролировать его заполнение. Вместо нее современные версии библиотек С предоставляют функцию fgets, которой размер буфера передается в качестве параметра. Настоятельно рекомендуется использовать именно ее.
Процедура fscanf в данном случае лечится. Вместо
fscanf(socket, "%s %s\n", cmd, args);
следует написать
fscanf(socket, "%4s %255s\n", cmd, args);
Однако автоматизировать проверку того, что в каждом случае все форматные спецификаторы указаны правильно, невозможно, и поэтому использовать процедуру fscanf и другие процедуры того же семейства не рекомендуется.
В тесном концептуальном родстве со срывами буфера находятся ошибки, срабатывающие при использовании во входном потоке данных недопустимых величин смещения (рис. 9). Такие ошибки встречаются при анализе входного потока, который содержит взаимосвязанные структуры данных, связи между которыми реализованы в виде смешений в потоке. Практически важный пример такого протокола – система квитирования (посылки подтверждений) со скользящим окном, используемая в транспортном протоколе TCP [RFC 0793]. Адресация посредством смещений широко применяется также при работе с последовательными файлами, поэтому драйверы файловых систем и сетевые файловые серверы также могут содержать такие ошибки.
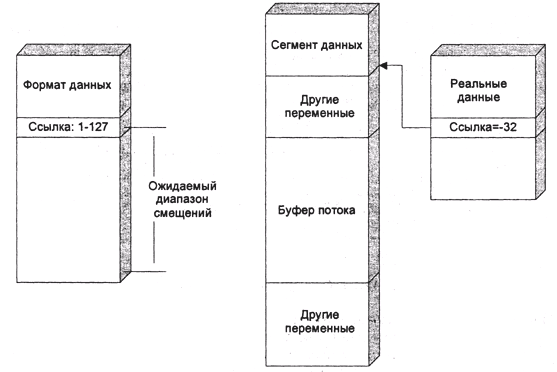
Рис. 9. Использование недопустимых смещений
Задание смещений, превосходящих размер буфера анализирующей программы, или недопустимых по каким-либо другим правилам – например, отрицательных, если по протоколу допустимы только положительные – может приводить к формированию указателей за пределы анализируемого буфера. Модификация данных по этим указателям может приводить к разнообразным последствиям – например, таким способом можно попытаться убедить файловый сервер, что файл, открытый для чтения, в действительности открыт для записи.
В многопоточных сервисах распространены также ошибки соревнования. Для их срабатывания необходима определенная последовательность и временное согласование запросов к сервису.
В некоторых типах сервисов встречаются свойственные им ошибки. Так, во многих серверах HTTP была обнаружена ошибка подъема по каталогам (directory traversal bug), когда злоумышленник, запрашивая URL, содержащие последовательности '..', мог подняться по файловой системе выше корневого каталога HTTP-сервера и, таким образом, считать или даже модифицировать файлы, не входящие в иерархию HTML-документов (рис. 10). Аналогичные ошибки встречаются и в сетевых файловых серверах.
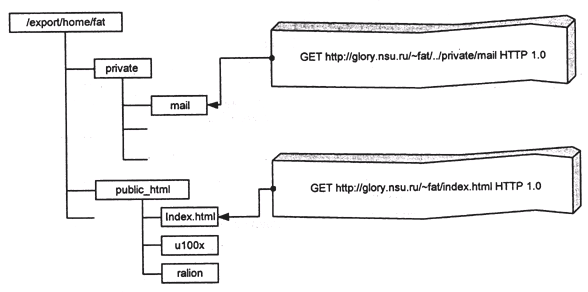
Рис. 10. Ошибка подъема по каталогам
Общим правилом, позволяющим если не искоренить ошибки такого рода, то во всяком случае, уменьшить вероятность их совершения, является недоверие к входным потокам данных. Если спецификации протокола или формата гласят что то или иное условие обязано выполняться, мы не можем просто считать что оно выполняется, а обязаны как минимум вставить явную проверку того, что оно выполняется. Программа тестирования программного комплекса должна включать не только проверку правильной обработки допустимых входных данных в каждом из модулей, осмысленную реакцию на недопустимые входные данные.
| <== предыдущая лекция | | | следующая лекция ==> |
| Процессы в Linux и Unix | | | Назначение и основные свойства ОС |
Дата добавления: 2017-11-04; просмотров: 909;