Помните, что большинство команд администрирования доступны только привилегированным пользователям! Для получения привилегий воспользуйтесь командами su или sudo.
В процессе установки будет запрошен пароль для учётной записи root базы данных, как это показано на рисунке 4.6. Затем на следующем экране нужно повторить этот пароль, чтобы не было ошибки. Не путайте пароль администратора MySQL с паролем операционной системы!
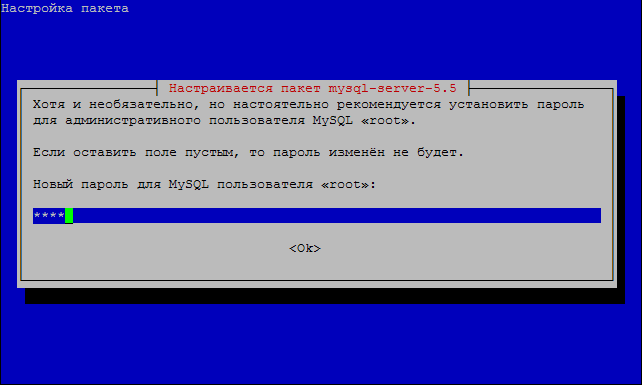
Рисунок 4.6 – Установка MySQL: запрос root пароля
Обратите внимание, что если MySQL не работает должным образом её можно полностью переустановить, выполнив следующие команды:
| apt-get remove --purge ^mysql-server-* mysql-common apt-get install mysql-server |
Теперь пришло время создать базу данных, таблицы и пользователя для скрипта. Это можно сделать, подключившись к БД следующей командой:
| mysql –user=root -p |
Либо установить на веб-сервер phpMyAdmin [6]. Затем выполните следующие SQL команды:
| # Создание БД с именем nfdump_pl CREATE DATABASE `nfdump_pl` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci; # Создание пользователя nfdump_pl, который имеет только локальный доступ на выборку, вставку, обновление и удаление записей в базе данных nfdump_pl с паролем password GRANT SELECT, INSERT, UPDATE, DELETE PRIVILEGES ON `nfdump_pl` TO nfdump_pl@localhost IDENTIFIED BY 'password'; # Переход в контекст БД nfdump_pl USE `nfdump_pl`; # Таблица для хранения забаненных IP-адресов # Создание таблицы banlist с полями id (автоматический идентификатор записи), ip (забаненный IP-адрес), time (автоматически проставляемое время создания записи) CREATE TABLE IF NOT EXISTS `banlist` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `ip` int(10) unsigned NOT NULL, `time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`), UNIQUE KEY `ip` (`ip`), KEY `time` (`time`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ; # Таблица для сохранения количества потоков в определённое время # Создание таблицы flow_cnt с полями ts (автоматически проставляемое время создания записи), flows (количество потоков) CREATE TABLE IF NOT EXISTS `flow_cnt` ( `ts` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, `flows` int(10) unsigned NOT NULL, PRIMARY KEY (`ts`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8; |
Для занесения IP-адреса в таблицу необходимо выполнить по крайней мере два запроса к БД:
1. Проверить, не заблокирован ли IP-адрес уже.
2. Если заблокирован, то обновить время блокировки, в противном случае добавить IP-адрес в таблицу.
Для уменьшения количества запросов к БД ниже приведено создание специальной функция ban. Она будет использоваться в скрипте. Код необходимо выполнить в SQL окне:
| # Создание функции ban, принимающей в качестве аргумента IP адрес, а возвращающей состояние: 0 – IP-адрес уже существует в таблице, 1 – IP-адрес внесён в таблицу. CREATE FUNCTION `ban`(parip VARCHAR(15)) RETURNS tinyint(1) BEGIN # Переменная для идентификатора записи DECLARE vid INT(10) UNSIGNED DEFAULT 0; # Переменная для преобразованного в число IP адреса DECLARE iip INT(10) UNSIGNED DEFAULT INET_ATON(parip); # Поиск IP-адреса в таблице banlist SELECT id INTO vid FROM banlist WHERE ip=iip LIMIT 1; # Если IP-адрес не найден IF vid = 0 THEN # Вставляется новая запись INSERT INTO banlist (ip) VALUES (iip); ELSE # Если адрес найден # Обновляется время в существующей записи UPDATE banlist SET time = CURRENT_TIMESTAMP WHERE id = vid; END IF; # Возвращается 0 – IP-адрес уже существует в таблице, 1 – IP-адрес внесён в таблицу RETURN vid=0; END |
Далее приведён код скрипта на языке Perl с комментариями:
| #!/usr/bin/perl use 5.8.8; use strict; use warnings; use DBI; # подключение Perl библиотек # данные для подключения к БД my $hostname = "localhost"; my $database = "nfdump_pl"; my $user = "nfdump_pl"; my $password = "password"; my $dbh = 0; # указатель на подключение к БД my $sth = 0; # запрос к БД my $path_nfcapd = "/var/cache/nfdump/"; # путь к бинарным файлам nfcapd my $path_nfdump = "/var/nfdump/"; # путь к текстовым файлам nfdump # поиск самого нового файла файла в архиве chdir $path; # задаёт текущей директорию $path my (@file_list) = glob "nfcapd.20*"; # сохраняем список файлов по маске в массив @file_list my $flowfile = $file_list[$#file_list]; # в переменную $flowfile сохраняем значение последнего элемента массива @file_list undef @file_list; # удаляем из памяти массив @file_list ############################## # преобразование бинарного формата nfdump в текстовый в той же директории system "nfdump -r ".$path_nfcapd.$flowfile." > ".$path_nfcapd.$flowfile.".txt"; # удаление бинарного файла (если конечно мы не хотим сохранить его в архиве) system "rm -f ".$path_nfcapd.$flowfile; open(FileData,$path_nfdump.$flowfile.".txt"); # открытие текстового файла nfdump my @lines = <FileData>; # считываем содержимое файла в массив строк close(FileData); # закрываем файл # копирование текстового файла nfdump в архивную директорию (если нам нужен архив) system "cp ".$path_nfcapd.$flowfile.".txt ".$path_nfdump.$flowfile.".txt"; # удаление текстового файла nfdump из директории с бинарными файлами system "rm -f ".$path_capd.$flowfile.".txt"; my $fcnt = 0; # общее количество потоков на весь файл (за минуту) my @IPs = (); # массив [IP-адрес, Дата] для потоков for ($i = 1; $i < @lines-4; $i++) { # заполнение массивов исходных данных if ( $lines[$i] =~ m/^(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\.\d{3}) {1,5}\d{1,5}\.\d{3} \w{1,6} +(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}):[\d ]{6}-> +(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}):\d{1,5} +\d+ +\d+ +(\d+)$/ ) { # каждая строка файла nfdump обрабатывается регулярным выражением и на каждой итерации переменным присваиваются следующие значения: # $1 – Дата и время фиксации потока в файле # $2 – IP-адрес источника # $3 – IP-адрес назначения # $4 – зафиксированное количество потоков if ($3 eq "IP нашего сервера") { # для всех потоков идущих на наш сервер if (($2 ne "IP DNS 1") && ($2 ne "IP DNS 2")) { # исключаем ДНС сервера $fcnt += $4; # прибавляем к переменной $fcnt количество зафиксированных потоков push(@IPs , [$2,$1]); # добавляем в массив @IPs запись о потоке } } } } # сортировка массива @IPs по IP-адресу источника @IPs = sort { ( $a->[0] cmp $b->[0] ) } @IPs; open ( LogFile, ">> /var/log/nfdump.pl.log" ); # открываем файл журнала для записи $dbh = DBI->connect("DBI:mysql:$database:$hostname", $user, $password) || print LogFile "Got error". $dbh->errstr ."\n"; # получение доступа к БД, в случае неудачи ошибка сохраняется в журнал # заносим общее число потоков в таблицу flow_cnt БД $sth = $dbh->prepare("INSERT INTO flow_cnt (flows) VALUES (".$fcnt.")"); # подготовка запроса $sth->execute; # выполнение запроса my $ref = 0; # служебная переменная для результатов запросов к БД my $count = 1; # счетчик числа потоков my $i = 0; # служебная переменная для цикла for ($i = 1; $i < $#IPs; $i++) { # проход по всем элементам массива IPs if ($IPs[$i-1][0] eq $IPs[$i][0]) { # если текущий IP адрес в элементе массива IPs равен предыдущему, то число потоков на этот IP увеличивается на единицу ++($count); } else { # в противном случае if ($count > 300) { # проверяется не превысило ли количество потоков 300 и если превысило, то my $ipT = $IPs[$i-1][0]; # в переменную $IPt сохраняется IP-адрес атакующего print LogFile $IPs[$i-1][1]," ",$ipT," ",$count,"\n"; # IP-адрес атакующего заносится в журнал #>>>>> Следующие строки используются только в данной работе для непосредственной блокировки IP-адреса атакующего и в дальнейшем в работе будет предложен универсальный способ блокировки при помощи fail2ban, который работает с файлами журналов. # IP-адрес атакующего заносится в таблицу забаненных в БД $sth = $dbh->prepare("select ban('".$ipT."');"); # подготовка запроса к БД $sth->execute; # выполнение запроса к БД if (($ref = $sth->fetchrow_arrayref) && ($$ref[0]==1)) { # проверяется выполнился ли запрос к БД и какой статус вернула функция ban (0 уже в таблице забаненных, 1 успешно помещён в список) system "iptables -I fail2ban-galcev -s ".$ipT." -j DROP"; # блокировка IP-адреса на сервере с помощью iptables } #<<<<< } $count = 1; # сброс счётчика количества потоков } } #>>>>> Далее в работе будет предложен универсальный способ блокировки при помощи ipset, который работает значительно быстрее. # функция разбана IP-адресов по прошествии 10 минут # из таблицы banlist выбираются все IP-адреса, занесённые более 10 минут назад $sth = $dbh->prepare("SELECT id, INET_NTOA(ip) FROM banlist WHERE time<CURRENT_TIMESTAMP - INTERVAL 10 MINUTE;"); # подготовка запроса к БД $sth->execute; # выполнение запроса к БД while ($ref = $sth->fetchrow_arrayref) { # цикл по всем выбранным IP-адресам system "iptables -D fail2ban-galcev -s ".$$ref[1]." -j DROP"; # разблокировка IP-адреса на сервере с помощью iptables # удаление IP-адреса из БД my $sth2 = $dbh->prepare("DELETE FROM banlist WHERE id='".$$ref[0]."';"); # подготовка запроса $sth2->execute; # выполнение запроса $sth2->finish; # очистка памяти } #<<<<< $sth->finish; # очистка памяти $dbh->disconnect; # закрытие подключения к БД close(LogFile); # закрытие файла журнала exit( 0 ); # успешное завершение скрипта |
Не забудьте создать директорию /var/nfdump/ для архива файлов nfdump в текстовом виде. Обратите внимание, что эта директория будет быстро заполняться новыми файлами и вам придётся периодически её очищать. Если вы не хотите содержать полный архив – закомментируйте копирование файлов в эту директорию в начале скрипта.
Проверить работу скрипта можно выполнив следующие команды:
| # Подключение к MySQL mysql –user=nfdump_pl –p # Вход в контекст БД nfdump_pl USE `nfdump_pl` # Запрос 10 последних записей из таблицы flow_cnt SELECT * FROM `flow_cnt` ORDER BY `ts` DESC LIMIT 10; |
Перед вами должна появиться таблица следующего вида:
| +---------------------+-------+ | ts | flows | +---------------------+-------+ | 2014-06-04 23:49:01 | 143 | | 2014-06-04 23:48:01 | 164 | | 2014-06-04 23:47:00 | 138 | | 2014-06-04 23:46:00 | 198 | | 2014-06-04 23:45:00 | 163 | | 2014-06-04 23:44:00 | 256 | | 2014-06-04 23:43:00 | 183 | | 2014-06-04 23:42:00 | 175 | | 2014-06-04 23:41:01 | 232 | | 2014-06-04 23:40:01 | 203 | +---------------------+-------+ 10 rows in set (0.00 sec) |
В ней отображены последние 10 записей, которые скрипт сделал в БД. Первая запись должна быть сделана меньше минуты назад.
Для того чтобы иметь возможность отлаживать скрипт и видеть ошибки, происходящие в нём рекомендуется вышеуказанный скрипт назвать /usr/local/sbin/nfdump2.pl, а в качестве файла /usr/local/sbin/nfdump.pl использовать нижеследующий:
| #!/usr/bin/perl use 5.8.8; use strict; use warnings; use DBI; # подключение Perl библиотек # Выполнение скрипта nfdump2.pl и добавление стандартного вывода и вывода ошибок в файл журнала. system "/usr/local/sbin/nfdump2.pl >> /var/log/nfdump.pl.errors.log 2>&1"; exit( 0 ); # успешное завершение скрипта |
Этот скрипт избавит нас от проблем с программой nfdump при поломке главного скрипта, а так сохранит информацию для отладки в файл журнала.
В связи с тем, что в директории /var/cache/nfdump/ постоянно создаются и удаляются файлы (она участвует в конвертации из бинарного формата nfdump в текстовый) создаётся большая нагрузка на систему хранения данных компьютера. Все эти файлы временные, поэтому в этой директории правильно будет использовать файловую систему tmpfs. Её смысл в том, чтобы не записывать временные файлы на диск, а отвести часть оперативной памяти для их хранения. Таким образом, производительность доступа к этим файлам значительно повышается, а износ системы хранения данных уменьшается. Для этого необходимо добавить в файл /etc/fstab следующую информацию:
| # <file system> <mount point> <type> <options> <dump> <pass> nfdump /var/cache/nfdump tmpfs size=24M 0 0 |
Что означает, что в директории /var/cache/nfdump/ будет использоваться файловая система tmpfs размеров в 24Мб. Далее приведён список команд для внесения изменений:
| # Добавляет необходимую строку в файл fstab echo "nfdump /var/cache/nfdump tmpfs size=24M 0 0" >> /etc/fstab # Монтирование новой файловой системы mount nfdump # Проверка df -h /var/cache/nfdump # Размонтирование файловой системы при необходимости umount nfdump |
Когда вы убедитесь, что скрипт работает, и БД наполняется можно перейти к следующему этапу – создание страницы для отображения общей статистики по потокам. Ниже приведёт PHP скрипт flows.php, который делает выборку из базы данных и выводит на страницу среднее значение потоков в минуту за прошлые 1, 5, 10, 30 и 60 минут. Страница автоматически обновляется каждые 10 секунд.
| <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Refresh" content="10" /> <title>Flows Statistics</title> </head> <body> <? // Параметры подключения к БД $hostname = "localhost"; $database = "nfdump_pl"; $user = "nfdump_pl"; $password = "password"; // Подключение к MySQL $link = mysql_connect($hostname, $user, $password); if (!$link) { die('Ошибка соединения: ' . mysql_error()); } // Переход в контекст БД $db_selected = mysql_select_db($database, $link); if (!$db_selected) { die ('Не удалось выбрать базу foo: ' . mysql_error()); } // Выборка последних 60 записей из таблицы flow_cnt $result = mysql_query("SELECT flows FROM flow_cnt ORDER BY ts DESC LIMIT 60"); if (!$result) { die ('Ошибка запроса: ' . mysql_error()); } $cnt=0; // количество элементов (минут в данном случае) в выборке $sum=0; // сумма потоков во всех полученных записях while($row=mysql_fetch_array($result)) { // цикл по всем полученным записям $sum+=$row[0]; // прибавляем к сумме количество потоков в текущей записи $cnt++; // количество элементов (минут) в выборке +1 if($cnt==1)echo $sum." flow/min (last minute)<br />\n"; // если было просуммировано пять элементов (минут) выборки, то делим сумму на 5 и выводим округлённый результат на страницу else if($cnt==5)echo round($sum/5)." flow/min (last 5 minute)<br />\n"; else if($cnt==10)echo round($sum/10)." flow/min (last 10 minute)<br />\n"; else if($cnt==30)echo round($sum/30)." flow/min (last 30 minute)<br />\n"; else if($cnt==60)echo round($sum/60)." flow/min (last hour)<br />\n"; } mysql_close($link); // закрываем подключение к MySQL ?> </body> </html> |
Указанный скрипт необходимо разместить на веб-сервере, в директории, в который исполняются PHP скрипты. Чтобы увидеть результат обратитесь к скрипту при помощи браузера, например http://localhost/flows.php.
4.5.Мониторинг трафика на уровне пакетов
Ранее в данной главе были рассмотрены способы мониторинга активности пользователей на уровне запросов к веб-серверу и потоков NetFlow. В этом пункте главы приводятся способы мониторинга сети на уровне пакетов. Зачем это нужно? Дело в том, что существует такой тип атак UDP-flood, при котором на адрес компьютера-жертвы отправляется большое количество UDP пакетов, которые забивают канал и блокируют прохождение нормальных запросов от пользователей, возникает отказ в обслуживании. Так как веб-сервер работает с TCP подключениями, то в журналах доступа такой трафик никак не отображается. В частом случае, когда порты источника и получателя у всех пакетов одинаковы в течении длительного времени, анализ на основе NetFlow потоков тоже не покажет ничего необычного, ведь это один большой поток данных и не более того. В свою очередь с помощью мониторинга трафика на уровне пакетов можно мгновенно отреагировать на превышение лимита, коим может выступать, как количество информации, так её скорость передачи или другие статистические особенности.
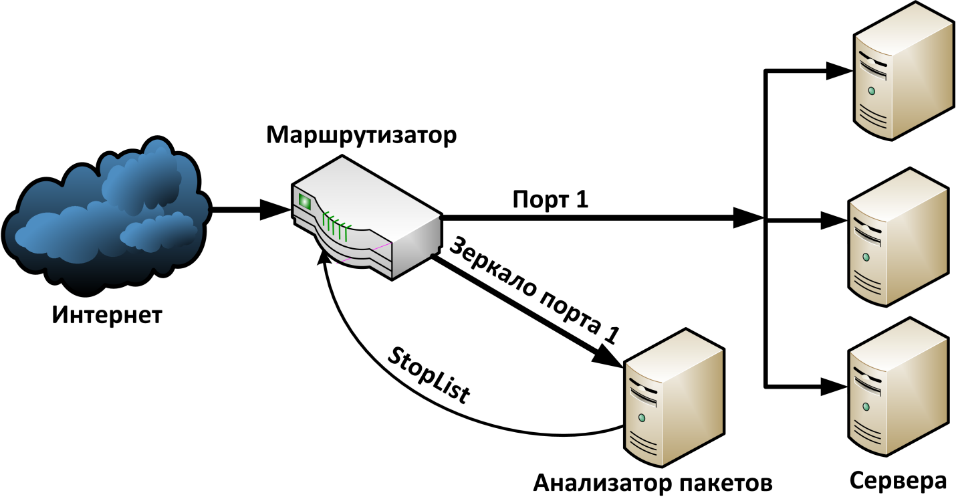
Рисунок 4.7 - Принципиальная схема установки анализатора пакетов
Схема установки анализатора пакетов в сети приведена на рисунке 4.7. Она похожа на схему на рисунке 4.1, с той лишь разницей, что теперь с маршрутизатора на анализатор поступает не статистическая информация NetFlow, а дублируются все пакеты с порта, к которому подключены сервера. Зеркалирование порта это стандартная функция для маршрутизаторов и коммутаторов уровня предприятия. В случае если на маршрутизаторе нет свободных портов, функция зеркалирования может быть возложена на промежуточный коммутатор. Анализатор пакетов в свою очередь должен отправлять на маршрутизатор информацию по блокируемым IP-адресам. В рамках работы будет рассмотрен минимальный вариант с установкой анализатора пакетов непосредственно на рабочем компьютере, который необходимо защитить.
В этой работе будет рассмотрена программа с минимальным набором функций. Это шаблон или «болванка», которая нуждается в доработке с точки зрения статистического анализа и алгоритмики обнаружения атак, но она небольшая в объёме и достаточно проста, чтобы проводить обучение на её основе.
Программа использует свободную библиотеку Pcap [7] (Packet Capture) для получения информации о приходящих по сети пакетах. На основе этой библиотеки работают такие проекты, как tcpdump, Wireshark, Snort, fprobe и многие другие. Ниже приведён текст программы, написанной на языке Си, с комментариями.
| #define APP_NAME "netmon" // название программы #define APP_DESC "Network monitor" // описание программы // информация об авторстве #define APP_COPYRIGHT "Copyright (c) 2005 The Tcpdump Group, 2014 Evgeny Sagatov" // отказ от ответственности #define APP_DISCLAIMER "THERE IS ABSOLUTELY NO WARRANTY FOR THIS PROGRAM." // Подключение дополнительных заголовочных файлов #include <pcap.h> #include <stdio.h> #include <string.h> #include <stdlib.h> #include <ctype.h> #include <errno.h> #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <stdbool.h> #include <signal.h> #include <syslog.h> /* default snap length (maximum bytes per packet to capture) */ #define SNAP_LEN 1518 /* размер заголовка канального уровня. Поддерживаются заголовок Ethernet, размер которого всегда 14 байт, и Linux cooked-mode capture (SLL), размер которого 16 байт. Таким образом программа может функционировать с большинством устройств. */ #define SIZE_ETHERNET 14 #define SIZE_LINUX_SLL 16 int header_size; // реальный размер заголовка после определения типа сети /* IP header */ struct sniff_ip { u_char ip_vhl; /* version << 4 | header length >> 2 */ u_char ip_tos; /* type of service */ u_short ip_len; /* total length */ u_short ip_id; /* identification */ u_short ip_off; /* fragment offset field */ #define IP_RF 0x8000 /* reserved fragment flag */ #define IP_DF 0x4000 /* dont fragment flag */ #define IP_MF 0x2000 /* more fragments flag */ #define IP_OFFMASK 0x1fff /* mask for fragmenting bits */ u_char ip_ttl; /* time to live */ u_char ip_p; /* protocol */ u_short ip_sum; /* checksum */ struct in_addr ip_src,ip_dst; /* source and dest address */ }; // макрос для извлечения размера IP заголовка #define IP_HL(ip) (((ip)->ip_vhl) & 0x0f) // макрос для извлечения версии IP протокола #define IP_V(ip) (((ip)->ip_vhl) >> 4) /* Далее идёт блок кода с описанием списка, для хранения IP-адресов, пакеты с которых пришли на компьютер, и различных статистических параметров, например количество пакетов разного типа и объём полученной информации. Список выполнен в виде массива ссылок на структуры типа stat_ip, каждая из которых хранит IP-адрес и статистическую информацию по нему. Все элементы списка упорядочиваются при добавлении по IP-адресу. Такой подход даёт возможность использовать очень быстрый алгоритм бинарного поиска с незначительно большими затратами вычислительной мощности и памяти при добавлении элементов. Дублирование IP-адресов запрещено. */ struct stat_ip { // ячейка списка struct in_addr ip; // IP-адрес удалённого компьютера unsigned long tcp, tcp_size, udp, udp_size, other, other_size; /* количество пакетов различного типа и общий размер полученной информации в этих пакетах. */ unsigned long udp_attack; /* количество полученных UDP пакетов. Используется для определения атаки UDP-flood. Когда лимит на количество пакетов превышен IP-адрес блокируется, а данная переменная обнуляется. */ }; struct { /* структура без имени описывающая только одну глобальную переменную stat_list. Является описанием массива ссылок stat_ip. */ struct stat_ip **list; // массив ссылок на структуры stat_ip unsigned long size; // количество элементов stat_ip в массиве list } stat_list = { .size=0 }; // при создании stat_list поле size инициализируется нулём /* Функция реализует алгоритм бинарного поиска. Если IP-адрес в списке найден, то функция возвращает порядковый номер элемента. Если не найден, то возвращается позиция вставки нового IP-адреса. В качестве аргумента функция принимает IP-адрес клиента в виде структуры in_addr. */ unsigned long stat_about(struct in_addr ip_src){ long min=0, max=stat_list.size-1, cur; /* описание классических для бинарного поиска переменных min, max и cur */ while(min<=max){ // поиск выполняется пока min меньше или равно max cur=min+(max-min)/2; // выбирается элемент посередине между min и max /* если IP-адрес выбранного элемента в списке меньше переданного */ /* в функцию IP-адреса, то значит искомый элемент больше cur */ if(stat_list.list[cur]->ip.s_addr < ip_src.s_addr){ /* задаём минимальный исследуемый элемент, как cur+1 */ min=cur+1; /* если IP-адрес выбранного элемента в списке больше переданного */ /* в функцию IP-адреса, то значит искомый элемент меньше cur */ }else if(stat_list.list[cur]->ip.s_addr > ip_src.s_addr){ /* задаём максимальный исследуемый элемент, как cur-1 */ max=cur-1; /* если IP-адреса равны, значит искомый элемент найден */ }else{ /* выходим из функции, возвращаем номер искомого элемента */ return cur; } } /* если IP-адрес в списке найден не был, то возвращается позиция */ /* вставки нового элемента с тем IP-адресом, что был передан в функцию */ return min; } /* Функция stat_set является основным обработчиком списка. Информация (исходящий IP-адрес, протокол, размер пакета) о всех пришедших пакетах должна быть передана в эту функцию. Первым делом в функции производится поиск переданного IP-адреса в списке stat_list. Если он находится, то в статистику по нему добавляются переданные значения. Если IP-адреса ещё нет в списке, то он вставляется в позицию, при которой список будет оставаться упорядоченным по IP-адресам. При каждой вставке происходит создание нового массива адресов new_list, который на один элемент больше старого old_list. Если новый элемент должен быть добавлен в позицию index, то из старого массива копируются все элементы до index, в их текущих позициях, а начиная с index в новый массив элементы переносятся со здвигом +1 элемент. Затем создаётся новый элемент в позиции index. */ void stat_set(struct in_addr ip_src, u_char ip_p, u_short ip_len){ /* Вызывается функция stat_about для поиска переданного IP-адреса в списке stat_list. index будет содержать порядковый номер элемента в списке, либо место в списке, куда необходимо вставить новый элемент. */ unsigned long index = stat_about(ip_src); /* Если index выходит за размер списка или IP-адрес по указанному индексу не равен искомому IP-адресу, то */ if(stat_list.size==index || stat_list.list[index]->ip.s_addr!=ip_src.s_addr){ /* сохраняется ссылка на массив list во временную переменную */ struct stat_ip **old_list=stat_list.list; /* создаётся новый массив, на один элемент больше старого */ struct stat_ip **new_list=malloc(sizeof(struct stat_ip*)* (stat_list.size+1)); /* копируются ссылки на элементы из старого массива */ /* в новый до элемента index */ memcpy(new_list,old_list,index*sizeof(struct stat_ip*)); /* копируются после index со сдвигом вправо на один элемент*/ memcpy(&new_list[index+1],&old_list[index], sizeof(struct stat_ip*)*(stat_list.size-index)); /* создаётся новый элемент массива с порядковым номером index */ new_list[index]=malloc(sizeof(struct stat_ip)); /* обнуляется содержимое элемента с номером index */ memset(new_list[index],0,sizeof(struct stat_ip)); /* новому элементу присваивается IP-адрес */ new_list[index]->ip=ip_src; /* задаётся новый массив list и увеличивается размер списка */ stat_list.list=new_list; stat_list.size++; /* удаление старого массива ссылок */ free(old_list); /* Примечание: Такой порядок действий, когда старый массив удаляется уже после обновления списка и использование временных переменных необходимы, так как в программе присутствует функция signal_handler. Она вызывается в момент срабатывания события USR1 и прерывает выполнение программы в её текущем состоянии для вывода статистики по IP-адресам. При этом необходимо быть уверенным, что все переменные списка stat_list доступны и верны. */ } /* выбор действий в зависимости от типа пакета */ switch(ip_p) { case IPPROTO_TCP: // для TCP пакета /* прибавляется к статистике по IP-адресу */ /* один TCP пакет и его размер */ stat_list.list[index]->tcp++; stat_list.list[index]->tcp_size+=ip_len; break; case IPPROTO_UDP: // для TCP пакета /* прибавляется к статистике по IP-адресу */ /* один UDP пакет и его размер */ stat_list.list[index]->udp++; stat_list.list[index]->udp_size+=ip_len; /* определяется атака UDP-flood */ /* прибавляем один пакет к статистической переменной, */ /* определяющей количество пришедших UPD пакетов, */ /* со времени прошлого блокирования IP-адреса */ stat_list.list[index]->udp_attack++; /* если количество таких пакетов больше 20, */ /* то вероятно это атака */ if(stat_list.list[index]->udp_attack > 20){ /* в системный журнал записывается оповещение */ /* о блокировке IP-адреса */ syslog(LOG_WARNING,"Ban (UDP-flood attack) %s", inet_ntoa(stat_list.list[index]->ip)); /* переменная udp_attack обнуляется */ stat_list.list[index]->udp_attack=0; } break; default: // для других типов пакетов /* прибавляется к статистике по IP-адресу */ /* один пакет отличный от TCP и UDP и его размер */ stat_list.list[index]->other++; stat_list.list[index]->other_size+=ip_len; } } /* Завершено описание списка. */ /* определение основных функций программы */ void got_packet(u_char *args, const struct pcap_pkthdr *header, const u_char *packet); void print_app_banner(void); void print_app_usage(void); /* реализация основных функций программы */ /* app name/banner. Информация о программе выводится в консоль при запуске. */ void print_app_banner(void) { printf("%s - %s\n", APP_NAME, APP_DESC); printf("%s\n", APP_COPYRIGHT); printf("%s\n", APP_DISCLAIMER); printf("\n"); return; } /* Функция выводит на консоль информацию по использованию */ /* программы и передаваемых аргументах. */ void print_app_usage(void) { printf("Usage: %s [interface]\n", APP_NAME); printf("\n"); printf("Options:\n"); printf(" interface Listen on <interface> for packets.\n"); printf("\n"); return; } /* Функция, в которую поступает информация о каждом пришедшем пакете. */ void got_packet(u_char *args, const struct pcap_pkthdr *header, const u_char *packet) { /* declare pointers to packet headers */ const struct sniff_ip *ip; /* The IP header */ int size_ip; // размер IP заголовка пакета /* define/compute ip header offset */ ip = (struct sniff_ip*)(packet + header_size); size_ip = IP_HL(ip)*4; /* если размер заголовка пакета меньше 20 байт, */ /* то пакет с ошибкой и не будет обработан */ if (size_ip < 20)return; /* добавляем информацию о пакете в список stat_list */ stat_set(ip->ip_src,ip->ip_p,ip->ip_len); return; } /* обработчик сигналов */ /* Функция реализует один из вариантов межпроцессорного взаимодействия, путём отправки программе сигнала. Это может быть сигнал закрытия или отключения от консоли, но в данном случае это сигнал USR1, который мы будем отправлять самостоятельно, чтобы получить статистику по IP-адресам в любое время, не останавливая сбор статистики. */ void signal_handler(int sig) { /* проверяется какой сигнал пришёл программе */ switch(sig){ /* если пришёл сигнал USR1, то */ case SIGUSR1:{ /* описываются временные переменные */ unsigned long i, tcp=0, tcp_size=0, udp=0, udp_size=0, other=0, other_size=0; /* цикл по всем элементам списка stat_list */ for(i=0;i<stat_list.size;i++){ /* в консоль выводится вся собранная статистика по */ /* пакетам с одного IP-адреса в каждую итерацию цикла */ printf("%s %u %u %u %u %u %u\n", inet_ntoa(stat_list.list[i]->ip), stat_list.list[i]->tcp, stat_list.list[i]->tcp_size, stat_list.list[i]->udp, stat_list.list[i]->udp_size, stat_list.list[i]->other, stat_list.list[i]->other_size ); /* суммируется статистика по всем IP-адресам */ tcp+=stat_list.list[i]->tcp;; tcp_size+=stat_list.list[i]->tcp_size; udp+=stat_list.list[i]->udp; udp_size+=stat_list.list[i]->udp_size; other+=stat_list.list[i]->other; other_size+=stat_list.list[i]->other_size; } /* выводится общая статистика по пакетам для всех IP-адресов*/ printf("%s %u %u %u %u %u %u\n", "TOTAL", tcp, tcp_size, udp, udp_size, other, other_size); break; } } } /* Функция main выполняется при запуске программы. В неё передаются аргументы запуска программы. */ int main(int argc, char **argv) { /* программа запрашивает доступ к отправке */ /* своих сообщений в системный журнал */ openlog(APP_NAME, LOG_PID|LOG_CONS|LOG_NDELAY, LOG_USER); /* функция signal_handler устанавливается */ /* в качестве обработчика сигнала USR1 */ struct sigaction act; memset(&act, 0, sizeof(act)); act.sa_handler = signal_handler; sigset_t set; sigemptyset(&set); sigaddset(&set, SIGUSR1); act.sa_mask = set; sigaction(SIGUSR1, &act, 0); char *dev = NULL; /* capture device name */ char errbuf[PCAP_ERRBUF_SIZE]; /* error buffer */ pcap_t *handle; /* packet capture handle */ char filter_exp[256]; /* filter expression [3] */ struct bpf_program fp; /* compiled filter program (expression) */ bpf_u_int32 mask; /* subnet mask */ bpf_u_int32 net; /* ip */ print_app_banner(); // в консоль выводится информация о программе /* check for capture device name on command-line */ if (argc == 2) { // если переданы два аргумента /* если в качестве аргумента программе переданы –h или –help, */ /* то выводится информация об использовании программы */ if(!strcmp(argv[1],"-h") || !strcmp(argv[1],"--help")){ print_app_usage(); exit(0); } dev = argv[1]; }else if (argc > 2) { // если передано более двух аргументов, // то выход с выводом ошибки fprintf(stderr, "error: unrecognized command-line options\n\n"); print_app_usage(); exit(EXIT_FAILURE); }else { /* find a capture device if not specified on command-line */ dev = pcap_lookupdev(errbuf); if (dev == NULL) { fprintf(stderr, "Couldn't find default device: %s\n", errbuf); exit(EXIT_FAILURE); } } /* get network number and mask associated with capture device */ if (pcap_lookupnet(dev, &net, &mask, errbuf) == -1) { fprintf(stderr, "Couldn't get netmask for device %s: %s\n", dev, errbuf); net = 0; mask = 0; } /* составляется фильтр для libpcap с учётом IP-адреса компьютера*/ int sock = socket(AF_INET, SOCK_DGRAM, 0); // создаётся сокет /* заполняется структура для получения IP-адреса */ struct ifreq ifr={.ifr_addr.sa_family = AF_INET}; strncpy(ifr.ifr_name, dev, IFNAMSIZ-1); // копирование имени интерфейса /* попытка получить IP-адрес на выбранном интерфейсе */ if(!ioctl(sock, SIOCGIFADDR, &ifr)){ strcpy(filter_exp,"ip dst host "); strcat(filter_exp, inet_ntoa(((struct sockaddr_in *)&ifr.ifr_addr)->sin_addr)); }else strcpy(filter_exp,"ip"); close(sock); // закрытие сокета /* print capture info */ printf("Device: %s\n", dev); printf("Filter expression: %s\n", filter_exp); /* open capture device */ handle = pcap_open_live(dev, SNAP_LEN, 1, 1000, errbuf); if (handle == NULL) { fprintf(stderr, "Couldn't open device %s: %s\n", dev, errbuf); exit(EXIT_FAILURE); } /* make sure we're capturing on an Ethernet or Linux SLL device */ int dl=pcap_datalink(handle); /* в зависимости от оборудования устанаваливается */ /* значение размера заголовка пакетов */ if(dl == DLT_EN10MB){ header_size=SIZE_ETHERNET; }else if (dl == DLT_LINUX_SLL){ header_size=SIZE_LINUX_SLL; }else{ fprintf(stderr, "%s is not an Ethernet or Linux SLL. This is %d type.\n", dev, pcap_datalink(handle)); exit(EXIT_FAILURE); } /* compile the filter expression */ if (pcap_compile(handle, &fp, filter_exp, 0, net) == -1) { fprintf(stderr, "Couldn't parse filter %s: %s\n", filter_exp, pcap_geterr(handle)); exit(EXIT_FAILURE); } /* apply the compiled filter */ if (pcap_setfilter(handle, &fp) == -1) { fprintf(stderr, "Couldn't install filter %s: %s\n", filter_exp, pcap_geterr(handle)); exit(EXIT_FAILURE); } /* now we can set our callback function */ pcap_loop(handle, -1, got_packet, NULL); /* cleanup */ pcap_freecode(&fp); pcap_close(handle); unsigned int i; for(i=0;i<stat_list.size;i++)free(stat_list.list[i]); free(stat_list.list); closelog(); return 0; } |
Необходимо сохранить текст программы в файл с именем ~/netmon/netmon.c и провести компиляцию исходного кода в Linux программу. Для этого установите дополнительный пакет с исходными текстами библиотеки Pcap:
| apt-get install libpcap-dev |
Все остальные необходимые библиотеки и компиляторы ставятся по умолчанию при установке базовой системы Debian. Перейдите в директорию с файлом netmon.c и выполните компиляцию программы:
| gcc -march=native -O2 -lpcap netmon.c -o netmon |
gcc – это название компилятора,
-O2 – опция, позволяющая оптимизировать программу для производительности,
-march=native – компиляция производится с учётом особенностей архитектуры компьютера на котором производится,
-lpcap – подключение библиотеки Pcap,
-o netmon – задаёт имя программы после компиляции.
Компиляция должна завершиться без ошибок и предупреждений. Столько небольшая программа компилируется всего несколько секунд, после чего командный интерфейс консоли Linux снова ждёт ввода следующих команд.
Проверим, что программа действительно скомпилировалась, и файл netmon был создан:
| find netmon |
В случае если программа на своём месте, то вы увидите её имя, в противном случае ошибку. Для запуска программы используется следующая команда:
| ./netmon |
По умолчанию программа автоматически определит первый доступный сетевой интерфейс и запустит его мониторинг. Если на вашем компьютере несколько активных интерфейсов, то укажите тот, который нужно мониторить:
| ./netmon eth1 |
После запуска программы на консоли вы увидите следующую информацию:
| netmon - Network monitor Copyright (c) 2005 The Tcpdump Group, 2014 Evgeny Sagatov THERE IS ABSOLUTELY NO WARRANTY FOR THIS PROGRAM. Device: eth0 Filter expression: ip dst host 192.168.2.1 |
Сначала информацию о программе, затем выбранный сетевой интерфейс и значение фильтра Pcap – в данном случае выбран мониторинг только IP пакетов, адресованных именно на наш интерфейс. На вашем компьютере вероятно IP-адрес будет другим. Программа перешла в режим работы, приглашения для ввода команд нет, ввод с клавиатуры возможен, но игнорируется. Завершить программу можно сочетанием клавиш Ctrl+C.
Оставим программу собирать статистику, а сами попробуем запустить другую консоль и сделать запрос статистики. Если у вас запущена графическая среда, можно просто открыть ещё одно окно консоли. Либо выполнить переход из режима рабочего стола в режим одной из виртуальных консолей с помощью сочетания клавиш Ctrl + Alt + F1..F6, где F1-F6 соответствует номеру консоли. Обратно в графический режим можно переключиться с помощью сочетания клавиш Ctrl + F7. Переход между виртуальными консолями выполняется клавишами Ctrl + F1-F6.
В итоге в другой консоли мы можем выяснить идентификатор процесса нашей программы:
| ps ax | grep "[n]etmon" | egrep -o "^[ 0-9]+" |
Зная идентификатор процесса можно отправлять программе различные команды, например, для закрытия или в нашем случае для вывода статистики. Для этого необходимо использовать команду kill:
| kill 12345 # закрывает процесс с идентификатором 12345 kill –USR1 12345 # отправляет сигнал USR1 процессу с идентификатором 12345 # следующая команда автоматически находит идентификатор # процесса netmon и отправляет ему сигнал USR1 kill -s USR1 `ps ax | grep "[n]etmon" | egrep -o "^[ 0-9]+"` |
При выполнении последней команды на экран будет выведена статистическая таблица:
| ~/netmon# ./netmon eth1 netmon - Network monitor Copyright (c) 2005 The Tcpdump Group, 2014 Evgeny Sagatov THERE IS ABSOLUTELY NO WARRANTY FOR THIS PROGRAM. Device: eth1 Filter expression: ip dst host 10.7.163.13 192.168.0.1 16 283648 0 0 258282 1968611032 81.28.160.1 0 0 230 7434038 0 0 10.4.203.13 0 0 1 37120 0 0 10.15.255.33 556 10201995 0 0 0 0 10.1.197.46 8 118530 3 36864 0 0 10.5.32.88 0 0 6 73728 0 0 81.28.160.111 0 0 184 5885803 0 0 10.2.135.145 0 0 1 37120 0 0 10.6.128.164 0 0 18 170514 0 0 10.245.193.201 0 0 2 29696 0 0 10.1.66.203 0 0 1 11777 0 0 10.13.72.204 0 0 6 244992 0 0 10.0.128.250 26 376832 6 73728 0 0 TOTAL 606 10981005 458 14035380 258282 1968611032 |
В таблице приведён список IP-адресов, с которых были получены пакеты на адрес компьютера. Через пробел к каждому адресу указано количество пакетов разного типа и количество полученной информации:
1. IP-адрес
2. Количество принятых TCP пакетов
3. Количество принятых байт информации в TCP пакетах
4. Количество принятых UDP пакетов
5. Количество принятых байт информации в UDP пакетах
6. Количество принятых пакетов не UDP или TCP
7. Количество принятых байт информации в пакетах не UDP или TCP
Последней строкой указана статистическая сумма для всех IP-адресов.
Если с какого-то из IP-адресов пришло более 20 UDP пакетов, то информация об этом должна была попасть в журнал user.log. Убедиться в этом можно следующей командой:
| cat /var/log/user.log | grep netmon |
Вывод должен быть примерно таким:
| Sep 14 02:17:38 debian netmon[30341]: Ban (UDP-flood attack) 81.28.160.65 Sep 14 02:19:15 debian netmon[30341]: Ban (UDP-flood attack) 81.28.160.2 Sep 14 02:21:32 debian netmon[30341]: Ban (UDP-flood attack) 81.28.160.5 Sep 14 02:22:59 debian netmon[30341]: Ban (UDP-flood attack) 81.28.167.128 Sep 14 02:25:03 debian netmon[30341]: Ban (UDP-flood attack) 10.13.72.204 |
В настоящий момент программа только выводит предупреждения в журнал, процесс блокировки будет подробно рассмотрен в следующем пункте работы.
Внимательный студент, вспомнив таблицы NetFlow, заметит, что они так же содержат в себе информацию по типам пакетов и объёму переданных данных для завершившихся потоков. Приведём скрипт, который из архива NetFlow формирует статистическую таблицу по IP-адресам, аналогичную программе netmon.
| <?php // php netflow-to-netmon.php /var/nfdump/ //Пример использования скрипта if ($argc!=2) exit("Неверное число параметров!\n"); //Проверяется передано ли нужное количество параметров $from=$argv[1]; //Путь к архиву NetFlow заносится в переменную $from $files=scandir($from); //Инициализация массива IP-адресов $ips=array(); //Инициализация переменных суммарной статистики $tcp=0; $tcp_size=0; $udp=0; $udp_size=0; $other=0; $other_size=0; foreach ($files as $file){ //Цикл по всем файлам в директории с архивом //Проверка соответствует ли имя файла регулярному выражению $rgx $rgx='/^nfcapd\.201\d[01]\d[0-3]\d[0-2]\d[0-5]\d\.txt$/'; if(preg_match($rgx,$file)){ $file_handle=@fopen($from.$file, "r"); //Открывается файл для чтения if($file_handle){ //Проверяется удалось ли открыть файл //Цикл по всем строкам в файле while (($buf=fgets($file_handle,1024))!==false) { $rgx='/^201\d-[01]\d-[0-3]\d [0-2]\d:[0-5]\d:[0-5]\d\.\d\d\d +\d+\.\d\d\d (\w+) +(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}):\d{1,5} +-\> +(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}):\d{1,5} +(\d+) +(\d+) +(\d+)$/'; //Разбор строки файла по регулярному выражению $rgx //$res[1] – протокол //$res[2] – IP-адрес источника //$res[3] – IP-адрес назначения //$res[4] – количество пакетов в потоке //$res[5] – количество переданных байт в потоке if(preg_match($rgx,$buf,$res)){ //Фильтр потоков адресованных на сервер if($res[3]=='IP-АДРЕС-СЕРВЕРА'){ //Если IP-адрес источника уже существует в массиве $ips, то if(isset($ips[$res[2]])){ if($res[1]=='TCP'){//Если протокол потока TCP, то //количество пакетов и байт информации добавляются в массив $ips[$res[2]][0]+=$res[4]; $ips[$res[2]][1]+=$res[5]; }else if($res[1]=='UDP'){ //Если протокол потока UDP, то $ips[$res[2]][2]+=$res[4]; $ips[$res[2]][3]+=$res[5]; }else{ //Если протокол потока не TCP и не UDP, то $ips[$res[2]][4]+=$res[4]; $ips[$res[2]][5]+=$res[5]; } }else{//Если IP-адреса источника ещё нет в массиве if($res[1]=='TCP'){ //Если протокол потока TCP, то //количество пакетов и байт информации //добавляются в новый элемент массива $ips[$res[2]]=array($res[4],$res[5],0,0,0,0); }else if($res[1]=='UDP'){ //Если протокол потока UDP, то $ips[$res[2]]=array(0,0,$res[4],$res[5],0,0); }else{ //Если протокол потока не TCP и не UDP, то $ips[$res[2]]=array(0,0,0,0,$res[4],$res[5]); } } //Обновление общей статистики пакетов //и количества информации по протоколам if($res[1]=='TCP'){ $tcp+=$res[4]; $tcp_size+=$res[5]; }else if($res[1]=='UDP'){ $udp+=$res[4]; $udp_size+=$res[5]; }else{ $other+=$res[4]; $other_size+=$res[5]; } } } } //Если цикл чтения прерван, а конец файла ещё не достигнут if (!feof($file_handle)) { //Выводится ошибка чтения файла echo "Error: unexpected fgets() fail\n"; } fclose($file_handle); //Закрывается ранее открытый файл } } } //Вывод статистики //Проход по всем элементам массива $ips foreach ($ips as $ip => $v) { echo "$ip $v[0] $v[1] $v[2] $v[3] $v[4] $v[5]\n"; } //Вывод итоговой суммы по всем IP-адресам echo "TOTAL $tcp $tcp_size $udp $udp_size $other $other_size\n"; |
Теперь есть возможность сравнить показания обеих программ на одинаковом отрезке времени. Помните, что показания NetFlow запаздывают минимум на минуту и расчётный период необходимо сдвинуть соответствующим образом.
4.6.Формирование пользовательского ядра и использование списков доступа
В прошлых пунктах главы были рассмотрены способы построения базы данных IP-адресов пользовательского ядра веб-сайта на основе запросов к веб-серверу. Была создана архитектура для обнаружения IP-адресов атакующих компьютеров.
Пользовательское ядро сайта состоит из IP-адресов, с которых заходили посетители, за какой-то продолжительный промежуток времени. За это время количество новых IP-адресов должно стабилизироваться между 30% и 40% от общего количества уникальных IP-адресов за сутки. Для проведённых авторами исследований в конкретном случае стабилизация наступала через шесть недель (см. рисунок 4.8).
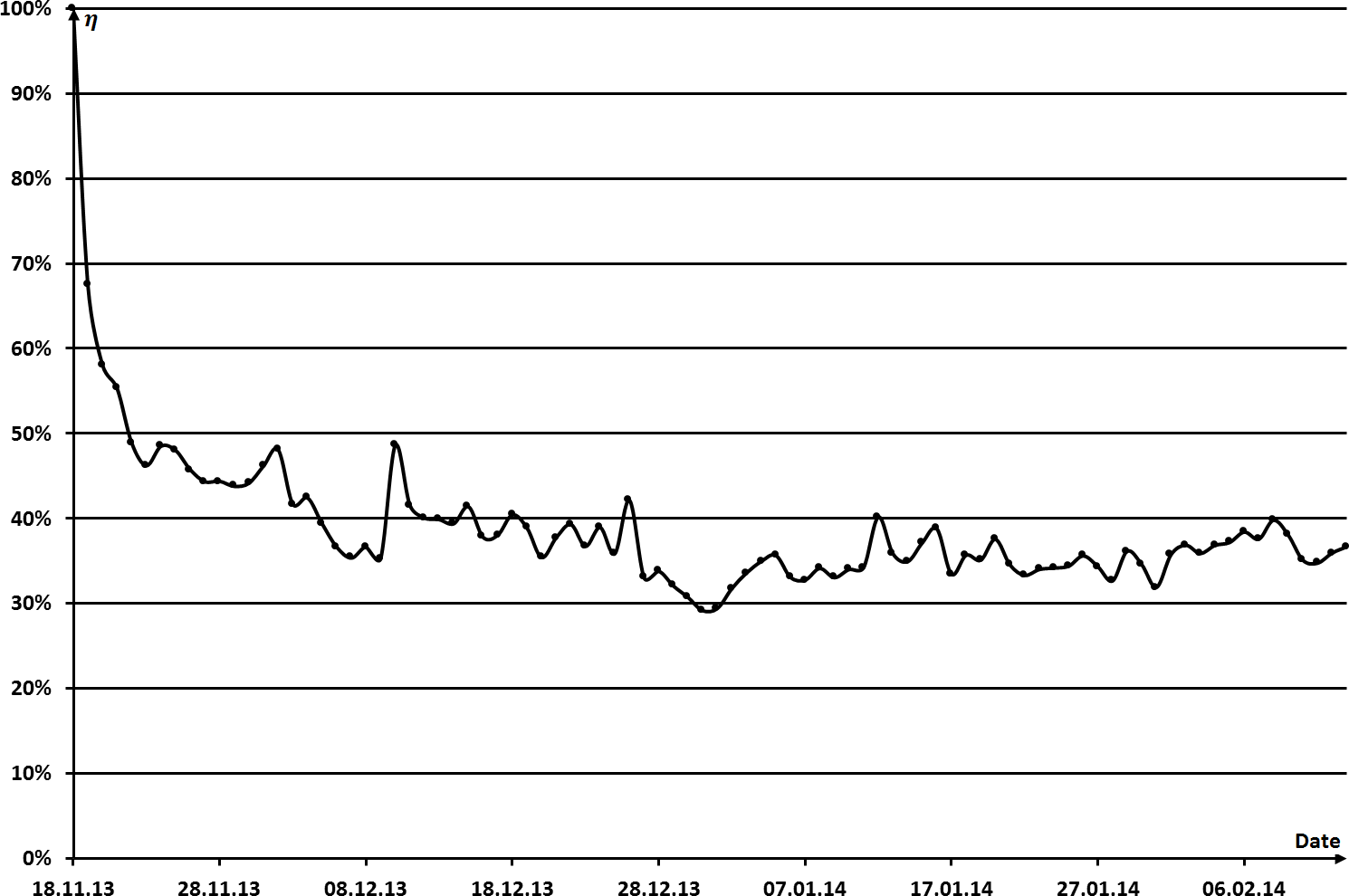
Рисунок 4.8 - График зависимости доли новых IP адресов за сутки от времени, пошедшего с начала измерений
Провайдеры последней мили чаще всего выдают пользователям IP-адреса в момент их входа в сеть из динамического пула своих адресов. Как правило, такие пользователи при каждом входе получают разные адреса, но из чётко ограниченного множества, принадлежащего провайдеру. Такие адреса называются динамическими.
Если более 30% такого динамического пула попали в базу данных пользовательского ядра, то необходимо все адреса пула добавить в БД, так как с них, вероятно, будут заходить благонадёжные клиенты. То есть необходимо произвести дополнение пользовательского ядра.
Адреса, с которых за всё время исследования были посещения в течение только одних суток, и не состоящие ни в одном пуле динамических IP-адресов, будем называть случайными. Эти адреса необходимо исключить из БД.
Обобщённый алгоритм дополнения БД выглядит следующим образом. Все IP-адреса БД разбиваются на подсети класса С (маска 255.255.255.0 или /24). Проверяется, заполнена ли эта подсеть адресами из БД хотя бы на 30%. Если заполнена, то вся подсеть вносится в БД. Если не заполнена, то эта подсеть разбивается на две подсети по маске /25 и по тому же алгоритму проверяется каждая отдельно. Разбивка и проверка продолжаются до сетевой маски /29 включительно (это сеть из 8 IP-адресов).
На практике в скрипте составляется двумерный массив, в котором в качестве первого ключа используются первые три октета IP-адреса. Второй ключ может быть от 0 до 31 (всего 32 значения) и представляет собой подсети /29. Каждая ячейка содержит количество IP-адресов в БД, которые попадают в эту подсеть. Просуммировав ячейки с 0 по 31 получим количество IP-адресов входящих в подсеть /24, с 0 по 14 – в первую подсеть /25, с 15 по 31 – во вторую подсеть /25 и т.д.
Для каждой подсети класса С вызывается рекурсивная функция proc, которая проверяет есть ли в подсети нужное количество IP-адресов. Если есть, то возвращает сеть и её маску, а если нет, то вызывает сама себя, в качестве аргументов передавая сначала одну подсеть /25, затем вторую. Для подсети /25 проводится аналогичная операция вплоть до /29. Затем объединяются и возвращаются все получившиеся подсети. Ниже приведён скрипт, проводящий дополнение БД IP-адресами подсетей.
| <?php // php bd-refill.php 2014-06-20 //Пример использования скрипта if($argc!=2) exit("Неверное число параметров!\n"); //Проверяется передано ли нужное количество параметров $nets=array(); //Массив сетей класса C, составленный из всех IP-адресов посетителей $file_handle = fopen($argv[1].".all", "r"); //Открывается БД IP-адресов для чтения if($file_handle) { //Проверяется открыта ли БД //Цикл по всем IP-адресам в БД while(($data=fgets($file_handle, 20))!==false) { //IP-адрес (192.128.5.16) разбивается на сеть класса С (192.168.5) и номер хоста (16) if(preg_match ('/^(\d{1,3}\.\d{1,3}\.\d{1,3})\.(\d{1,3})/', $data, $res)){ $ind=$res[1]; //Сеть класса С берётся в качестве индекса в массиве $nets $val=$res[2]; //Номер хоста извлекается в переменную $val //Вычисляется, к какой подсети /29 в массиве принадлежит хост $net29=ceil(($val+1)/8)-1; if(!isset($nets[$ind])){ //Если подсеть класса С не существует в массиве //Инициализируется нулями массив подсетей класса /29 $nets[$ind]=array(0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 ,0,0,0,0,0,0,0,0); } $nets[$ind][$net29]++; //В подсеть /29 добавляется один хост } } if(!feof($file_handle)) { //Если предыдущий цикл закончился, а конец файла всё ещё не достигнут, значит произошла ошибка чтения из файла. echo "Error: unexpected fgets() fail\n"; //Выводится ошибка } fclose($file_handle); //Закрывается файл БД }else exit("Не удалось открыть файл!\n"); //Выводится ошибка, если не удалось открыть файл БД // Рекурсивная функция, которая проверяет, есть ли в подсети 30% и более IP-адресов. // $net – одна сеть класса С из массива $nets, передаётся по ссылке // $from – с какого элемента массива $net начинать подсчёт // $to – на каком элементе массива $net подсчёт завершается // $net_c – в строковом виде передаётся подсеть класса С function proc(&$net,$from,$to,$net_c){ $hosts=0; //Инициализация количества хостов в подсети // Цикл, который суммирует все хосты в подсетях /29, которые входят в исследуемую подсеть for($i=$from;$i<=$to;$i++){ $hosts+=$net[$i]; } // Вычисление минимального количества хостов для внесения подсети в БД. // Это 30% размера подсети. $need_hosts=floor(((float)(($to+1)-$from))*8.0*0.3); // Если реальная заполненность подсети больше 30%, то if($hosts>=$need_hosts){ // Возвращается подсеть с маской, например 192.168.5.128/25. $conv=array(31=>24,15=>25,7=>26,3=>27,1=>28,0=>29); return $net_c.'.'.($from*8).'/'.$conv[$to-$from]."\n"; }else{ // Выход из функции, если достигнута минимальная подсеть /29 if($from==$to)return ''; // Ищется серединный элемент подсети, т.е. разбиение на две подсети $middle=$from+floor(($to-$from)/2); // Функция proc вызывается сначала для одной меньшей подсети, затем // для второй. Результат объединяется и возвращается. $ret=proc($net,$from,$middle,$net_c); return $ret.proc($net,$middle+1,$to,$net_c); } } // Создаётся новый файл с расширением *.nets и открывается для записи $file_handle = fopen($argv[1].".nets", "w"); // Цикл по всем сетям класса С массива $nets // $net_c – сеть класса С в виде строки // $nets29 – массив количества хостов в сети класса С с разбивкой на подсети /29 foreach ($nets as $net_c => $nets29) { // Вызывается функция proc для подсети класса С $ret=proc($v,0,31,$nets29); // Если функция нашла заполненные на 30% и более подсети, то сохраняем их в открытый файл *.nets if($ret!='')fwrite($file_handle,$ret); } fclose($file_handle); //Закрывается открытый файл с сетями |
После выполнения прошлых пунктов работы у вас на компьютере должна была сформироваться посуточная база данных IP-адресов. Это файлы с расширениями *.ip, *.sort, *.all, *.new, *.count и *.assigned. Для чего нужен тот или иной файл вы сможете понять в следующих пунктах данной главы. Для скрипта необходимо выбрать самую старшую дату и выполнить:
| php bd-refill.php 2014-06-20 |
При этом скрипт создаст ещё один файл 2014-06-20.nets, в котором будут перечислены все найденные по вышеописанному алгоритму подсети. Он выглядит следующим образом:
| 100.43.81.0/28 100.43.83.136/29 101.170.213.56/29 101.171.213.64/29 101.199.108.48/28 101.199.112.48/28 101.226.166.128/25 101.226.167.128/25 101.226.168.128/25 ... |
Этот список, согласно проведённым авторами исследованиям, включает в себя ~70% всех IP-адресов, попавших в БД. Именно он является пользовательским ядром, а соответственно списком доступа к веб-серверу в момент DDoS-атаки. Но кроме подсетей в БД остались ещё индивидуальные IP-адреса, которые тоже должны быть включены в пользовательское ядро. Для того чтобы их вычислить, необходимо развернуть файл сетей *.nets до IP-адресов, а затем найти IP-адреса из файла БД *.all, которые не встречаются в этом списке.
Сконвертировать список подсетей в IP-адреса поможет следующий скрипт:
| <?php //php nets-to-ips.php 2014-06-20 //Пример использования скрипта if($argc!=2) exit("Неверное число параметров!\n"); //Проверяется передано ли нужное количество параметров // Массив соответствия сети количеству хостов в ней $net_to_ip_cnt=array(24=>256,25=>128,26=>64,27=>32,28=>16,29=>8); // Открывается для чтения файл сетей $input_file = fopen($argv[1].'.nets', "r"); if($h===NULL)exit("Не удалось открыть файл ".($argv[1]).".nets!\n"); // Создаётся и открывается для записи файл IP-адресов, входящих в сети $output_file = fopen($argv[1].'.ipnets', "w"); if($h===NULL)exit("Не удалось открыть файл ".($argv[1]).".ipnets!\n"); // Цикл по всем подсетям в файле подсетей while(($data=fgets($input_file, 50))!==false) { // Строка из файла разбивается на два значения: сеть и маску сети if ( preg_match ('/^(\d{1,3}\.\d{1,3}\.\d{1,3}\.)(\d{1,3})\/(\d\d)/', $data, $res) ) { // В файл IP-адресов записываются все адреса, входящие в выбранную подсеть for($i=0;$i<$net_to_ip_cnt[$res[3]];$i++){ fwrite($ouput_file,$res[1].($res[2]+$i)."\n"); } } } if(!feof($input_file)) { //Если предыдущий цикл закончился, а конец файла всё ещё не достигнут, значит произошла ошибка чтения из файла. echo "Error: unexpected fgets() fail\n"; //Выводится ошибка } fclose($input_file); // Закрывается файл подсетей fclose($output_file); // Закрывается файл IP-адресов |
После выполнения скрипта:
| php nets-to-ips.php 2014-06-20 |
будет создан новый файл 2014-06-20.ipnets, который будет содержать все IP-адреса, входящие в подсети из файла 2014-06-20.nets.
Получить все IP-адреса из БД, которые не вошли в найденные подсети теперь можно одной bash командой:
| cat 2014-06-20.all 2014-06-20.ipnets 2014-06-20.ipnets | sort | uniq –u > 2014-06-20.ipwonets |
Команда uniq –u на вход должна получить отсортированный список строк, а на выходе будут только те строки, которые не повторяются. Так список подсетей – это, по сути, дополненный список всех адресов БД, то в нём встречаются IP-адреса, которых нет в основном списке БД. Чтобы удалить их файл *.ipnets на вход подаётся дважды. Таким образом, в файл *.ipwonets будут сохранены только IP-адреса, которые есть в файле *.all, но отсутствуют в *.ipnets.
Теперь из этого “остатка” IP-адресов необходимо исключить случайные адреса. Это адреса, которые были замечены во время исследования в течение только одних суток. В прошлой части работы приводится способ формирования списка IP-адресов с указанием количества дней, в течение которых с него были обращения к веб-серверу. В результате создаётся файл с расширением *.assigned. Удалим случайные IP-адреса с помощью командной строки bash:
| # Выбрать только IP-адреса, которые встречались одни сутки cat 2014-05-01_2014-06-20.assigned | egrep "(^1 | 1 )" | grep -P -o "[\.\d]+$" > 2014-05-01_2014-06-20.casual # Удалить случайные адреса из пользовательского ядра cat 2014-06-20.ipwonets 2014-05-01_2014-06-20.casual 2014-05-01_2014-06-20.casual | sort | uniq –u > 2014-06-20.ips |
В получившимся файле 2014-06-20.ips будет список IP-адресов, которые не вошли в список сетей 2014-06-20.nets, но с них были запросы более чем за одни сутки. Именно эти два файла являются списками доступа, а также пользовательским ядром веб-сайта.
Теперь разберёмся с тем, как именно нужно использовать списки доступа и блокировок. На рисунке 4.9 изображена принципиальная схема соединения сетей. Стрелочками показано направление трафика при DDoS-атаке, а ширина линий обозначает ширину Интернет-канала между двумя устройствами.
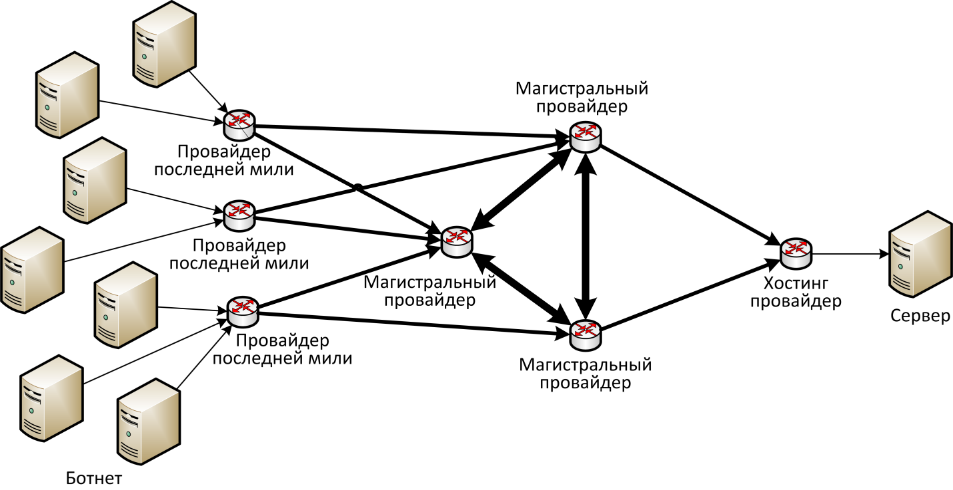
Рисунок 4.9 - Принципиальная схема DDoS-атаки
Из схемы можно понять, что провайдеры между собой соединены несколькими высокоскоростными каналами связи. Компьютеры из ботнет-сети, как правило, имеют подключение последней мили к вышестоящему провайдеру 1-100Мбит/с. За счёт своего количества эти боты создают много UDP-трафика, идущего к атакуемому серверу. Этот трафик забивает Интернет-канал сервера. Соответственно для отражения такой атаки, необходима блокировка IP-адресов у провайдеров, как можно ближе к самим ботам. В идеальном случае блокировка должна проводиться у провайдеров последней мили, тогда ненужный трафик вообще не будет попадать в Интернет, и доходить до сервера. Но на практике чем административно дальше от сервера находится атакующий компьютер, тем сложнее его ограничивать. В настоящий момент необходимо иметь договорённость с хостинг провайдером, а лучше с вышестоящим магистральным провайдером о применении ваших списков доступа.
В рамках работы будет рассмотрена возможность применения списков доступа на рабочем компьютере в операционной системе Debian GNU/Linux 7.6.0. Таким способом можно отразить только сравнительно небольшую атаку.
Основным средством управления сетевым трафиком, а точнее межсетевым экраном NetFilter[8] в ОС Linux является утилита iptables. С её помощью системный администратор задаёт правила, исходя из которых, каким-то пользователям будет предоставлен доступ к веб-серверу, а каким-то будет отказано. В нашем случае основным критерием будет выступать IP-адрес.
Сразу необходимо отметить, что для того, чтобы пропустить или заблокировать каждый пакет от пользователя, ядру Linux придётся сравнить IP-адрес источника этого пакета с каждым IP-адресом в правилах, которое задал администратор. Например, в исследованиях, которые проводили авторы работы, получилась ~21 тысяча сетей и ~34 тысячи индивидуальных IP-адресов. Что составляет ~55 тысяч правил. Если учесть, что каждую секунду на канал в 100Мбит/с может приходить в среднем 15 тысяч запросов, то ядру Linux необходимо будет обработать 825 миллионов правил. Это слишком много и любой сервер уровня предприятия зависнет, обрабатывая сетевой поток.
Для решения вышеописанной проблемы был разработан модуль для NetFilter, который обеспечивает очень быстрое сравнение списка IP-адресов с заданным правилом. Это обеспечивается за счёт того, что модуль хранит не правила, которые необходимо последовательно проверять, а именно упорядоченные хэш списки адресов или сетей, поиск по которым происходит очень быстро. Для всех IP-адресов будет всего одно правило в iptables, которое будет сравнивать адрес в пришедшем пакете сразу со списком в ipset.
Для начала необходимо установить ipset:
| apt-get install ipset |
Теперь можно создавать списки. Утилита ipset поддерживает две нотации написания команд: как в iptables и в виде слов. Рассмотрим несколько команд более подробно:
| # Создание списка хэшированных IP-адресов с именем banlist ipset -N banlist iphash # Другая запись предыдущей команды ipset create banlist hash:ip # В самое начала таблицы INPUT (входящие пакеты) добавляется запись о том, что # если адрес источника пакета содержится в списке banlist, то пакет отбрасывается iptables -I INPUT -m set --set banlist src -j DROP # В список вносятся два IP-адреса разными нотациями ipset -A banlist 101.17.225.177 ipset add banlist 101.1.215.37 # Получить информацию о списке и IP-адреса входящие в него ipset -L banlist ipset list banlist # IP-адреса удаляются из списка ipset -D banlist 101.17.225.177 ipset del banlist 101.1.215.37 # Очистка списка ipset -F banlist # или по другому ipset flush banlist # Удаление списка ipset -X banlist # или по другому ipset destroy banlist # Создание списка хэшированных IP-сетей с именем netbanlist ipset -N netbanlist nethash ipset create netbanlist hash:net # В список вносятся две IP-сети разными нотациями ipset -A netbanlist 101.17.225.0/24 ipset add netbanlist 101.1.215.0/26 # Сохраняет список сетей или IP-адресов в файл ipset save netbanlist > netbanlist # Считывает список сетей или IP-адресов из файла ipset restore < netbanlist # Пример списка, элементы в котором автоматически удаляются через 5 минут (300 сек.) ipset create banlist hash:ip timeout 300 # В список добавляется IP-адрес, но автоудаление этого адреса произойдёт через 1 минуту ipset add banlist 101.1.215.37 timeout 60 |
Если вы попробуете создать список адресов, внести в него несколько адресов, а затем сохранить этот список, то увидите файл следующего формата:
| add banlist 101.17.225.47 add banlist 101.17.225.149 add banlist 101.17.225.98 add banlist 101.17.225.67 |
То есть сохранение происходит в том же формате, что вводит администратор для пополнения списка. Ком
Дата добавления: 2017-03-29; просмотров: 860;