Сжатие на основе смыслового содержания данных
Пусть имеется алфавит A из n знаков (символов), т.е. A={ai}, i=1,…,n ,и по некоторому каналу связи нужно передать m сообщений (S={sj}, i=1,…,m). Каждое сообщение имеет длину lj, т.е. составляется из lj знаков алфавита A. Требуется передать сообщения через канал связи двоичными кодовыми словами минимальной длины.
Обозначим через R минимальное количество двоичных разрядов, достаточное для кодирования каждого из сообщений. Возможны два подхода к кодированию.
Первый из них основан на кодировании сообщений целиком, когда двоичное кодовое слово ставится в соответствие каждому из m передаваемых сообщений. При этом справедлива формула (1.1).
(1.1) 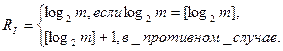
Здесь […] – целая часть числа.
Второй подход основан на посимвольном кодировании сообщений, когда двоичное кодовое слово формируется путем объединения кодов, соответствующих каждому из символов передаваемого сообщения. При этом справедлива формула (1.2).
(1.2) 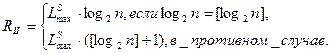
Здесь 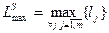 - длина самого большого сообщения.
- длина самого большого сообщения.
Очевидно, что выбор наиболее экономного способа кодирования зависит от сравнения целочисленных величин RI и RII : при наличии небольшого числа длинных сообщений предпочтителен первый подход, если же имеется много коротких сообщений, составленных из небольшого количества знаков, то предпочтительнее второй подход. Однако, количество передаваемых сообщений может быть заранее неизвестно. В этом случае необходимо производить посимвольное кодирование.
Пусть способ кодирования выбран. Теперь решим вопрос о том, каким образом можно дополнительно сократить количество разрядов Rдвоичного кодового слова.
Из вышеприведенных формул следует, что:
при первом подходе нужно постараться уменьшить число передаваемых сообщений m, например, путем отбрасывания повторяющихся сообщений. В тех случаях, когда точное число сообщений неизвестно, необходимо по возможности снижать значение верхней границы их оцениваемого количества. Однако существенное сокращение размерности множества сообщений, как правило, невозможно, потому что на практике каждое сообщение несет информацию о некоторой ситуации, число которых может быть фиксировано;
при втором подходе можно, во-первых, уменьшить размерность алфавита, что на практике почти невозможно, потому что связано с сокращением выразительных возможностей языка – попробуйте, например, выбрасывать буквы из алфавита от А до Я – и, во-вторых, уменьшить количество знаков в передаваемых сообщениях путем их сжатия по контексту (на основе смыслового содержания данных). Это гораздо более реальный путь, который лежит в основе большого количества практических методов сжатия данных. Рассмотрим некоторые из них.
Дата добавления: 2017-11-04; просмотров: 584;