Regression analysis
The main feature of the regression analysis: specific information can be obtained with its help on what form and nature of a relationship between the studied variables.
The sequence of the regression analysis
Consider briefly the steps of the regression analysis.
1. Formulation of the task. At this stage, formed the preliminary hypothesis about the dependence of the studied phenomena
2. Definition of dependent and independent (explanatory) variables.
3. Collection of statistical data. Data should be collected for each of the variables included in the regression model.
4. The wording of the communication form hypotheses (simple or multiple linear or nonlinear).
5. Determination of the regression function (is to calculate numerical values of the parameters of the regression equation)
6. Evaluation of the accuracy of the regression analysis.
7. Interpretation of the results. The resulting regression analysis results are compared with the preliminary hypotheses. We estimate the accuracy and credibility of the results.
8. The prediction of unknown values of the dependent variable.
Using regression analysis, possible solution to the problem of forecasting and classification. Predicted values are calculated by substituting into the regression equation parameters explanatory variables. The decision of the classification task is carried out as follows: the regression line divides the entire set of objects into two classes, and that part of the set where the function value is greater than zero, belongs to the same class, and that, where it is less than zero, - in another class.
2.Methods of collection, classification and prediction. Decision trees. Processing of large volumes of data.
Classification. Classification can be used to get an idea of the type of customer, product or object, describing a number of attributes to identify a specific class. For example, cars are easily classified by type (sedan, SUV, convertible), defining various attributes (seats, body style, drive wheels). Studying the new car, you can take it to a certain class by comparing the attributes with well-known definition. The same principles can be applied to customers, for example, classifying them by age and social group.
In addition, classification may be used as input for other methods. For example, to determine the classification can employ decision trees.
Prediction - this is a broad topic, which extends from the prediction hardware component failures to detect fraud, and even predict the company's profits. In combination with other methods of data mining prediction involves trend analysis, classification, matching and model relationships. By analyzing past events or items, you can predict the future.
For example, using data on the credit card authorization, you can combine the analysis of the decision tree of past human transactions with the classification and comparison with historical patterns to identify fraudulent transactions. If you buy tickets in the US coincides with the transaction in the US, it is likely that these transactions are genuine.
Decision trees
Decision tree method is one of the most popular methods for solving problems of classification and prediction. Sometimes this method is also called Data Mining trees decision rules, classification and regression trees.
As can be seen from the last name, using this method solved the problem of classification and prediction.
Тarget variable takes discrete values, using the method of decision tree classification problem is solved.
If the dependent variable takes continuous values, the decision tree establishes the dependence of this variable on the independent variables, i.e., it solves the problem of numerical weather prediction.
In the simplest form of a decision tree - it is a way of representing rules in a hierarchical, coherent structure. The basis of this structure - an answer "Yes" or "No" on a number of issues.
Fig. 9.1 shows an example of a decision tree, whose mission - to answer the question: "Is the game of golf?" To solve the problem; decide whether to play golf, the current situation should be referred to one of the known classes (in this case - to "play" or "do not play").This requires a series of questions that are at the nodes of the tree, from its root.
Our first tree node "Sunny?" a check node, ie condition. If the answer to the question moves to the left side of the tree, called the left branch, with a negative - to the right of the tree. Thus, internal node of the a tree is node test certain conditions. Next comes the next question, and so on until the final node of the tree is reached, which is the hub solutions. For our tree there are two types of end node "play" and "not play" golf.
As a result of the passage from the root (sometimes called the root node) to its top classification problem is solved, ie, select one of the classes - "play" and "not play" golf
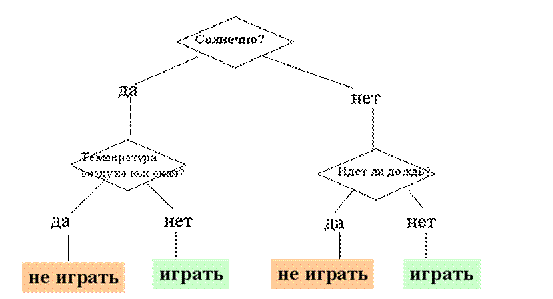
Figute 5- Decision Tree "Do Play golf?"
Intuitive decision trees. Classification model, presented in the form of a decision tree is an intuitive and easy understanding of the problem being solved. The result of the design of algorithms of decision trees, in contrast, for example, neural networks, which are "black boxes" can easily be interpreted by the user. This decision trees the property is not only important when referring to a particular class of the new object, but also useful in the interpretation of the classification model as a whole. The decision tree allows us to understand and explain why a particular object belongs to a particular class.
Тree algorithm design decisions do not require the user to select the input attributes (independent variables). The input of the algorithm can be fed all the existing attributes, the algorithm will choose the most important among them, and only they will be used to build a tree. In comparison, for example with neural networks, this greatly facilitates user operation, since the amount of neural networks input attributes selection significantly affects the time of training.
The accuracy of the models created using decision trees, is comparable to other methods of constructing classification models (statistical methods, neural networks).
A number of scalable algorithms that can be used to construct a decision tree on the very large scale database; scalability here is that with the increasing number of examples or database records the time spent on training, ie building decision trees, grows linearly. Examples of such algorithms: SLIQ, SPRINT.
Handling large amounts of data.
The term "big data" - a blueprint of English term. Big data does not have a strict definition. It is impossible to draw a clear line - is 10 terabytes, or 10 megabytes? The name itself is very subjective. The word "great" - is as "one, two, many" among primitive tribes.
However, there are well-established view that the big data - a set of technologies that are designed to perform three operations. Firstly, manipulate large in comparison with "standard" data volume scenarios. Secondly, to be able to work rapidly with the incoming data in a very large volumes. That is not just a lot of data, and they are constantly becoming more and more. Thirdly, they should be able to work with structured and poorly structured data in parallel in different aspects. Large data suggest that the input stream is obtained algorithms do not always structured information and that it can be extracted from more than one idea.
The advent of big data in the public space was due to the fact that these data are affected almost all people, not just the scientific community, where such problems are solved for a long time. In the public sphere Big Data technology came when it began to go on quite specific number - the number of inhabitants of the planet. 7 billion, gathering in social networks and other projects which aggregate people. YouTube, Facebook, VKontakte, where the number of people is measured in billions, and the number of transactions that they perform at the same time, enormous. The data flow in this case - a user action. For example, data of the same YouTube hosting that shimmer across the network in both directions. Under treatment is meant not only the interpretation but also the ability to properly handle each of these actions, that is, put it in the right place and to make sure that these data are available to each user quickly as social networking sites do not tolerate waiting.
Much of the data that concerns large, approaches that are used for analysis, there is actually quite long. For example, processing of images from surveillance cameras, we are not talking about the same picture, but the data stream. Or navigation of robots. All of this exists for decades, just now data processing tasks affected a much larger number of people and ideas.
Many developers are accustomed to working with static objects and think conditions categories. In larger paradigm of other data. You should be able to work with a steady stream of data, and it is an interesting challenge. It affects more and more areas.
In our life more and more hardware and software are starting to generate a large amount of data - for example, "Internet of things".
Things are already generating a huge flow of information. Police system "stream" sends information from all cameras and lets you find the machine according to these data. More and more are coming into fashion fitness bracelets, GPS-trackers and other things that serve human tasks and business.
Moscow Informatization Department of gaining a large amount of data analysts, because the statistics on people accumulate a lot and it is multi-criteria (for each person, collected statistics for a very large number of criteria for each group of people). In these data, it is necessary to find patterns and trends. For such tasks needed Mathematics with IT-education. Because eventually the data is stored in a structured database, and we must be able to handle it and to receive information.
3. Methods and Data Mining stage. Data Mining Tasks. Data Visualization.
All Data Mining techniques are divided into two large groups according to the principle of working with the original training data. The upper level of this classification is determined based on whether the data Data Mining after they are stored or distilled for later use.
1. The direct use of the data, or save the data.
In this case, the original data is stored in a detailed and explicit directly used for predictive modeling steps and / or analysis exceptions. The problem with this group of methods - using them can be difficult analysis of very large databases.
Methods of this group: cluster analysis, nearest neighbor method, the method of k-nearest neighbor, reasoning by analogy.
2. Identify and use of formal laws or distillation templates.
When distillation technology templates one sample (template) information is extracted from the raw data is converted into a certain formal structure whose form depends on the Data Mining method. This process is performed on the stage of the free search, in the first group stage of this method, in principle, no. On stage predictive modeling and analysis results are used exceptions stage of free search, they are much more compact databases themselves. Recall that the construction of these models can be interpreted by the analyst.
Дата добавления: 2017-05-18; просмотров: 1307;