Разработка программного обеспечения.
Исследования в области программного обеспечения в настоящее время развиваются в двух плоскостях: некоторые исследователи, которых называют практиками, разрабатывают методы создания приложений, а другие, теоретики, занимаются поиском основных принципов и теорий, из которых можно построить более прочную методику создания программного обеспечения.
Основным понятием в проектировании программного обеспечения является понятие жизненного цикла программы, который кроме создания программы включает в себя ее использование и модификацию.
К модификации программного обеспечения переходят, потому что обнаруживаются ошибки, меняется область применения программы, что требует соответствующих изменений в программе, или потому что изменения, внесенные во время предыдущей модификации, привели к ошибкам в работе.
Вне зависимости от того, почему начинается модификация программы, программист (часто не автор программы) изучает исходную программу и документацию к ней, пока не поймет ее. В противном случае любое изменение программы может создать больше проблем, чем оно призвано решить. Понимание программы представляет собой нелегкую задачу, даже если она хорошо продумана и снабжена необходимой документацией. В действительности, часто именно на этом этапе программа выбраковывается под предлогом, что легче создать новую систему с нуля, чем модифицировать существующий пакет программ.
Разработка программного обеспечения включает в себя анализ, проектирование, реализацию и тестирование программы.
Главная цель анализа– определить, какие действия должна выполнять будущая система (например, требование ограниченного доступа к данным)
На этапе проектированиясоздается структура системы программного обеспечения. Хорошо известно, что самой лучшей структурой для больших систем является модульная, то есть разделение программы на более мелкие элементы, каждый из которых выполняет только часть общей задачи. Без такой структуры количество технических деталей, которые нужно учитывать при реализации системы, превысило бы возможности человека. Модульная структура также облегчает последующую эксплуатацию системы, поскольку она позволяет при модификации вносить изменения только в конкретные модули. Модули могут иметь вид процедур и использоваться в качестве стандартных блоков для создания более крупных систем. При объектно-ориентированном программировании модули принимают форму объектов, каждый из которых имеет свою собственную внутреннюю организацию, не зависящую от строения других объектов.
Традиционным представлением модульной структуры, получаемой с помощью процедур, является структурная схема. На такой схеме каждый модуль изображается в виде прямоугольника, а зависимости между модулями в виде стрелок, соединяющих прямоугольники. Для изображения структуры объектно-ориентированных систем используются диаграммы классов.
Основная цель при проектировании модульной системы – сделать модули максимально независимыми друг от друга. Тогда при модификации изменения необходимо вносить только в конкретные модули. Однако для того чтобы модули составляли связную и логическую систему между ними должны существовать межмодульные связи. Следовательно, создать модули, максимально независимые друг от друга, значит минимизировать связи модулей системы.
Этап реализации включает в себя написание программ, создание файлов данных и баз данных.
Этап тестирования связан с этапом реализации, поскольку каждый модуль системы обычно тестируется сразу же после его реализации. В логичной и продуманной системе проверка каждого модуля должна осуществляться независимо от других модулей системы. По мере создания модулей тестирования отдельных компонентов заменяется тестированием всей системы.
Ранние подходы к разработке программного обеспечения требовали строго последовательного выполнения всех этапов. Такой метод разработки в настоящее время называется водопадной моделью, поскольку процесс разработки протекает в одном направлении. Примером альтернативного подхода может служить инкрементная модель проектирования, согласно которой разрабатываемая система программного обеспечения строится последовательными приращениями. Первая система является упрощенной версией конечного продукта с ограниченными функциональными возможностями. После тестирования этой версии и оценки ее будущими пользователями к ней добавляются дополнительные возможности, и она снова тестируется.
Наиболее известным методом проектирования является нисходящее проектирование. Суть его состоит в том, что задача разбивается на небольшие, более легко решаемые подзадачи. В результате применения нисходящего проектирования получается иерархическая система, которую часто можно сразу преобразовать в модульную структуру, соответствующую императивной парадигме программирования.
При восходящем проектировании создание системы начинается с определения отдельных задач системы и обсуждения того, как решения этих задач могут использоваться в качестве абстрактных инструментов для решения более сложных задач.
Разработка открытых программных продуктов. Этот метод в течение многих лет использовался компьютерщиками энтузиастами, а теперь признан законной методикой разработки программного обеспечения. В действительности, эта методика представляет собой разновидность эволюционного макетирования, но в отличие от традиционного подхода макетирование осуществляется открыто. Эта методика называется разработкой с открытым исходным текстом.
В некотором смысле разработка открытых программных продуктов является расширением бета-тестирования (которое рассмотрено ниже), но при этом испытатель бета-версии может модифицировать ее и сообщить о сделанных изменениях, а не просто о возникших проблемах, как при обычном бета-тестировании. Процесс создания открытых программных продуктов состоит из следующих этапов: автор пишет первоначальную версию программы (обычно выполняющую необходимые ему действия) и размещает исходный код и документацию в Интернете, откуда ее могут скачать другие программисты. Поскольку пользователи имеют в своем распоряжении исходный код и документацию, они могут изменять и дополнять программу согласно своим потребностям или исправлять обнаруженные ими ошибки. Затем они сообщают о сделанных изменениях автору, который заносит их в версию продукта, размещенную в Интернете. Таким образом, эта новая расширенная версия становится доступной для дальнейших модификаций. Практика показывает, что за неделю пакет программного обеспечения может изменяться несколько раз.
Поскольку действия разработчиков открытых систем программного обеспечения не согласованы и они не получают за свою работу никакого вознаграждения, может показаться, что они недостаточно мотивированы, чтобы создать высококачественную систему программного обеспечения. Однако опыт показывает обратное. В качестве примера можно привести операционную систему Linux, признанную самой надежной операционной системой из всех имеющихся в наличии. На самом деле, Линуса Торвальда, создателя этой операционной системы, можно считать родоначальником разработки отрытых программных продуктов, поскольку он руководил разработкой Linux именно с помощью этой методики.
Одной из причин, по которым разработка отрытых программных продуктов не применяется широко, является сложность установления права собственности на конечный продукт, ведь разработка открытых программных продуктов означает, что это программное обеспечение должно быть всеобщим достоянием и находиться в открытом доступе.
Другая трудность создания отрытых исходных текстов заключается в том, что руководителям такого проекта, привыкшим работать в деловом обществе, трудно принять стиль работы с рискованным финансированием, который необходим для успешной разработки открытого программного обеспечения. Условием такого метода разработки программного обеспечения является свободная, ничем не ограниченная работа программиста, которым управляет энтузиазм, желание выразить себя и чувство удовлетворения и гордости за проделанную работу. Однако часто руководители проектов своим чрезмерным контролем подрывают энтузиазм разработчиков. Например, руководитель может удержать некоторые части системы, чтобы установить право собственности, но разработка открытых программных продуктов подразумевает, что программист может скачать, использовать и модифицировать всю программную систему.
Тестирование.В настоящее время большая часть программного обеспечения проверяется с помощью тестирования. К сожалению, тестирование не всегда дает точный результат. Проводя тестирование, мы не можем с достоверностью сказать, что система программного обеспечения работает правильно, если только мы не проведем достаточное количество испытаний, которые будут включать все возможные сценарии. Но существует более тысячи разных вариантов, по которым может пойти простой цикл, содержащий оператор if-then-else, повторяющийсятолько десять раз. Поэтому проверить все возможные пути сложной программы просто невозможно.
Поэтому разработчики программного обеспечения создали методы тестирования, которые с достаточно большой вероятностью позволяют обнаружить ошибки в программе. Одна из методик основывается на наблюдении, что ошибки в программном обеспечении имеют свойство скапливаться в одном месте. То есть опыт показывает, что некоторые модули большой системы содержат больше ошибок, чем другие модули. Поэтому, определив эти модули и проверив их более тщательно, чем остальные, можно выявить больше ошибок, чем, если проверять все модули достаточно тщательно, но одинаковым образом. Это пример применения принципа Парето, названного в честь итальянского социолога и экономиста Вильфредо Парето (1848-1923. В общем, принцип Парето говорит о том, что часто можно достичь больших результатов, если прикладывать усилия в ограниченном пространстве.
Другой метод тестирования называется тестированием базового пути. В этом случае создается набор контрольных данных, которые бы подтверждали, что каждая команда программы выполняется, по меньшей мере, один раз. Для определения контрольных данных была разработана методика, в которой используется теория графов. (Теория графов – это геометрический подход к изучению объектов. Граф задается множеством вершин (узлов) и множеством ребер (связей), соединяющих некоторые пары вершин. Пример графа - схема линий метрополитена.) Хотя при таком способе тестирования и невозможно гарантировать, что будут проверены все ветви программной системы, однако можно утверждать, что в процессе проверки каждый оператор выполнился, по крайней мере, один раз.
В методах тестирования, основанных на принципе Парето и проверке базового пути, подразумевается, что нам известно внутреннее строение тестируемой системы. Поэтому эти способы тестирования можно отнести к категории тестирования методом «прозрачного ящика». В отличие от этого, при тестировании методом «черного ящика» внутреннее строение системы остается неизвестным. Основное внимание при таком тестировании уделяется не тому, как именно система выполняет задачу, а тому, выполняется ли задача правильно, точно и вовремя.
К тестированию методом «черного ящика» часто относят анализ граничного значения. В этом случае определяются граничные точки технических требований системы, и она проверяется в этих точках. Например, если система должна принимать входящие значения, заданные в определенном интервале, тогда она проверяется с наименьшим и наибольшим значениями. Или если система должна координировать какие-либо действия, тогда она проверяется с использованием самых сложных действий.
Другой способ тестирования методом «черного ящика» — применение избыточности. Согласно этому подходу разные проектные группы или даже разные компании создают независимо друг от друга две программные системы, выполняющие одинаковые действия. Затем эти две системы проверяются с использованием одних данных и результаты проверки сравниваются. Ошибки определяются по расхождениям результатов тестирования. Этот метод часто используется при проверке космических систем.
Другая методика тестирования - бета-тестирование - все более широко применяется разработчиками программного обеспечения, предназначенного для продажи. В этом случае часть предполагаемых покупателей снабжается предварительной версией программы, которая называется бета-версией. Прежде чем утвердить окончательную версию продукта и выпустить ее на рынок, разработчики пытаются выяснить, как программное обеспечение будет работать в реальных условиях. Бета-тестирование позволяет также узнать мнение покупателя (как положительное, так и отрицательное), что помогает усовершенствовать рыночную стратегию. Кроме того, распространение бета-версии программного обеспечения помогает другим разработчикам создавать продукты, совместимые с этим программным обеспечением. Например, распространение бета-версии новой операционной системы способствует разработке совместимых с ней обслуживающих программ, и окончательная версия операционной системы появляется на прилавках магазинов вместе с сопутствующими продуктами. Наконец, существование бета-версии программного обеспечения стимулирует интерес к программному продукту на рынке и увеличивает количество продаж. [1]
Базы данных.
Структуры данных.
Оперативная память ПК организована в виде отдельных ячеек с последовательными адресами. Однако часто бывает удобно представлять эти ячейки в виде других структур данных. Например, записи о продажах за неделю удобно представлять в табличной форме, которая является абстрактным представлением данных.
Во время конструирования абстрактных представлений необходимо различать является структура данных статической или динамической, то есть, меняется ли со временем ее форма и размер. В целом статическими структурами проще управлять, чем динамическими. Если структура статическая необходимо только обеспечит способы доступа к различным элементам данных и способы изменения значений элементов, находящихся на определенных местах. В случае динамической структуры необходимо решать проблемы добавления и удаления элементов данных и поиска пространства в памяти для увеличения размера структуры.
Указатели. Указатель – это ячейка (или блок ячеек), содержащий адрес другой ячейки памяти. Применительно к структурам данных указатели используются для записи адресов элементов данных. Таким образом, элемент данных может храниться в какой-либо ячейки памяти, а адрес этой ячейки – в указателе, при помощи которого можно позже получить эти данные. То есть значение указателя сообщит нам, где искать данные («указатель указывает на данные»).
Пример использования указателя. В памяти ПК храниться список рассказов, отсортированный в алфавитном порядке по названию. Такая организация удобна во многих приложениях, но затрудняет поиск рассказов, написанных одним автором, т.к. они разбросаны по всему списку. Для решения этой проблемы можно зарезервировать в каждом блоке ячеек памяти, представляющем один рассказ, отдельную ячейку типа указатель. Тогда в каждом из этих указателей можно хранить адрес другого блока, представляющего произведение того же автора, и все рассказы одного автора будут связаны в замкнутую цепь.
Массивы. Часто удобно представлять данные в виде таблиц, т.е. как двумерный массив. Но память машины организована не как таблица, а как цепочка ячеек с последовательными адресами. Поэтому требуемую прямоугольную структуру массива приходится моделировать. Если массив статичен (то есть его размер не изменяется по мере внесения изменений в данные), то подсчитаем объем памяти необходимый для всего массива, и зарезервируем непрерывный блок ячеек памяти полученного размера. Начиная с первой ячейки этого блока, последовательно в каждую ячейку записываем значения из первой строки массива, после первой строки таким же образом записываем последующие. Такая система записи называется построчной (может быть постолбцовая запись). При обращении к элементам массива транслятор преобразует запросы в фактические адреса памяти. Программист тем временем может представлять данные в табличной форме (абстрактная структура), даже если на самом деле они хранятся в одной строке (фактическая структура).
Списки. Это набор записей, выстроенных в определенной последовательности. Один из способов хранения списка – запись всего списка в один блок ячеек памяти с последовательными адресами (непрерывный список). Если данные динамические, то при добавлении или удалении данных приходится перемещать часть элементов списка в другие ячейки памяти.
Проблем, возникающих при работе с динамическими списками, можно избежать, разрешив хранение отдельных имен в различных областях памяти, а не одном большом непрерывном блоке. Например, можно хранить каждое имя в блоке из девяти смежных ячеек памяти. Первые восемь необходимы для записи самого имени, а последняя ячейка будет использоваться как указатель на следующее имя в списке. Следуя этому принципу, список можно раскидать по небольшим блокам, каждый из 9 ячеек, которые связаны между собой указателями. Подобная организация списков называется связным списком.
Для того чтобы определить начало связного списка, отдельно определяется еще один указатель, в котором хранится адрес первой записи. Так как этот указатель указывает на начало, или голову списка, он называется указателем головы.
Для определения конца связного списка используется пустой указатель (NIL), который является просто определенного вида набором битов и находится в последней записи, указывая, что за ним в списке более нет элементов, пример, если мы условимся никогда не хранить элементы списка по адресу 0; значение 0 никогда не будет являться разрешенным значением указателя, и этому его можно использовать как пустой указатель.
На рис. 3.11 отдельные блоки памяти, в которых хранятся элементы связного списка, представлены в виде прямоугольников. Строение каждого прямоугольника (блока памяти) обозначено надписями над ним. Указатели представлены стрелками, идущими от самого указателя к адресу, на который тот указывает. Для прохождения списка нужно последовать указателю головы — так мы найдем первую запись. Далее необходимо следовать указателям, хранящимся в записях, и по ним переходить от элемента к элементу до достижения пустого (NIL) указателя.
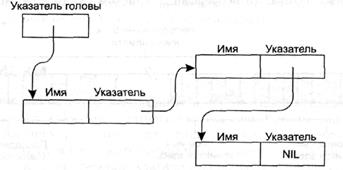
Рис. 3.12. Структура связного списка.
Теперь вернемся к вопросу удаления и добавления элементов в список. Использование указателей устраняет необходимость перемещения имен из одной ячейки памяти в другую, возникающую при хранении списка в одном связном блоке. Удалить имя можно, изменив один указатель. Это означает, что указатель, который ранее указывал на удаленное имя, изменяется и указывает теперь на имя, следующее за удаленным (рис. 3.13). Тогда при обработке списка удаленное имя пропускается.
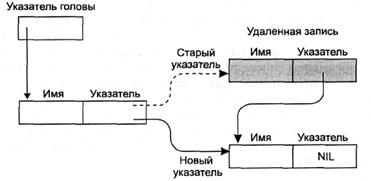
Рис. 3.13. Удаление записи из связного списка.
При добавлении нового имени находим неиспользуемый блок из девяти ячеек памяти, записываем новое имя в первые восемь ячеек, а в девятую записываем адрес имени, которое должно следовать в списке за новым. Затем изменяем указатель, связанный с именем, которое должно предшествовать новому имени в списке так, чтобы он указывал на этот новый блок (рис. 3.14). После этого новую запись можно будет найти на нужном месте при прохождении списка.
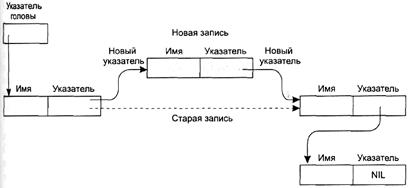
Рис. 3.14. Добавление записи в связный список.
Стек. Если разрешить удаление и добавление данных только в начале или в конце структуры, то можно использовать непрерывную структуру. В стеке последний добавленный элемент всегда будет удален первым (последним прибыл – первым убыл). Тот конец стека, где добавляются или удаляются элементы, называется вершиной стека, другой конец называют основанием стека. Для реализации стека в памяти компьютера обычно резервируют блок смежных ячеек памяти достаточного размера, чтобы вместить стек с учетом его увеличения или уменьшения.
Очередь – это список, в который записи добавляются с одной стороны, а удаляются с другой (первым прибыл – первым обслужен). Тот конец очереди, откуда удаляются записи, называется головой или началом очереди, конец очереди, куда добавляются записи, называется хвостом очереди.
Деревья. Эта структура данных отражает принцип организации типичных компаний. В такой структуру президент находится на вершине, от которой отходят линии к вице-президентам, и т.д. Чтобы дать интуитивное определение дерева накладывает ограничение, состоящее в том, что ни один сотрудник компании не подчиняется двум разным начальникам. То есть разные ветви организации не сливаются на нижнем уровне.
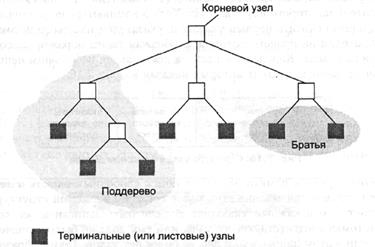
Рис. 3.15. Структура дерева.
Каждый элемент дерева называется узлом (рис. 3.15). Узел, находящийся наверху, называется корневым. Если перевернуть рисунок вверх ногами, этот узел будет находиться на месте основания или корня дерева. Узлы на противоположном конце дерева называются терминальными (или листовыми). Если мы выберем любой нетерминальный узел дерева, то обнаружим, что он вместе с узлами, находящимися ниже, также образует дерево. Эти меньшие структуры называются поддеревьями. Иногда структура деревьев рассматривается так, как если бы каждый узел порождал узлы, находящиеся сразу же под ним. Так определяются предки и потомки. Потомки узла называются дочерними узлами, а его предок - родителем. Узлы, имеющие одного и того же родителя, называются братьями. Глубину дерева определяют как количество узлов в наиболее длинном пути от корня до листа. Другими словами, глубина дерева – это количество горизонтальных уровней в нем.
Бинарное дерево – дерево, где у каждого узла может быть максимум два потомка. Бинарные деревья обычно хранятся в памяти при помощи связной структуры, похожей на связные списки. Каждая запись (или узел) дерева состоит из трех компонентов: 1) данные, 2) указатель на первого потомка узла и 3) указатель на второго потомка узла.
Дата добавления: 2017-01-29; просмотров: 6585;