Передача параметров функции main
Функция main, с которой начинается выполнение СИ-программы, может быть определена с параметрами, которые передаются из внешнего окружения, например, из командной строки. Во внешнем окружении действуют свои правила представления данных, а точнее, все данные представляются в виде строк символов. Для передачи этих строк в функцию main используются два параметра, первый параметр служит для передачи числа передаваемых строк, второй для передачи самих строк. Общепринятые (но не обязательные) имена этих параметров argc и argv. Параметр argc имеет тип int, его значение формируется из анализа командной строки и равно количеству слов в командной строке, включая и имя вызываемой программы (под словом понимается любой текст не содержащий символа пробел). Параметр argv это массив указателей на строки, каждая из которых содержит одно слово из командной строки. Если слово должно содержать символ пробел, то при записи его в командную строку оно должно быть заключено в кавычки.
Функция main может иметь и третий параметр, который принято называть argp, и который служит для передачи в функцию main параметров операционной системы (среды) в которой выполняется СИ-программа.
Заголовок функции main имеет вид:
int main (int argc, char *argv[], char *argp[])
Если, например, командная строка СИ-программы имеет вид:
A:\>cprog working 'C program' 1
то аргументы argc, argv, argp представляются в памяти как показано в схеме на рис.1.
argc [ 4 ] argv [ ]--> [ ]--> [A:\cprog.exe\0] [ ]--> [working\0] [ ]--> [C program\0] [ ]--> [1\0] [NULL] Рис.1. Схема размещения параметров командной строкиОперационная система поддерживает передачу значений для параметров argc, argv, argp, а на пользователе лежит ответственность за передачу и использование фактических аргументов функции main.
Следующий пример представляет программу печати фактических аргументов, передаваемых в функцию main из операционной системы и параметров операционной системы.
Пример:# include <stdio.h>
#include <windows.h>
char bufRus[256];
char* Rus(const char* text){
CharToOem(text, bufRus);
return bufRus;
}
int main ( int argc, char *argv[], char *argp[])
{ int i=0;
printf (Rus("\n Имя программы %s"), argv[0]);
for (i=1; i<=argc; i++)
printf (Rus("\n аргумент %d равен %s"),i, argv[i]);
printf (Rus("\n Параметры операционной системы:"));
while (*argp)
{ printf ("\n %s",*argp);
argp++; }
return (0); }
Тема 7. Язык программирования С/С++. Директивы препроцессора. Способы конструирования программ
Директивы: #define, #include, директивы условной компиляции: #if, #else, #elif и #endif, #ifdef и #ifndef. Директива #undef.Предопределенные макросы.
Способы конструирования и верификации программ. Модульное программирование, многофайловые проекты.
Препроцессор и его директивы. Компилятор языка С, прежде чем компилировать программу, выполняет определенные операции. Одной из таких операций является включение в программу других файлов (#include). Но это не все. Используя возможности прекомпиляции, можно создавать программы, компилируемые по разному в зависимости от текущих потребностей (например, строя или не строя отладочную информацию).
Препроцессор является составной частью любого компилятора языка С. Управление работой препроцессора осуществляется при помощи директив, включаемых в исходный код программы. В результате выполнения всех директив препроцессора, образуется новый вариант исходного кода программы, который затем компилируется.
Директива #include. Эта директива предназначена для включения в исходный текст программы исходного кода из указанных файлов, например, заголовочных файлов. В коде программы строка, содержащая директиву заменяется содержимым файла (например, одна строка - 8 страниц).
Допустимо вложение директив, т.е. в файле, на который указывает директива #include могут также использоваться директивы #include на другие файлы. Однако глубина такого вложения ограничена. Обычно допускается до 10 уровней вложения.
Существенный момент в использовании директивы #include состоит в указании имени файла:
#include <stdio.h>
#include "myhead.h"
если имя файла заключено в кавычки - файл будет искаться в том же каталоге, в котором находится файл программы, а если в угловые скобки - то сначала поиск осуществляется в специальном стандартном каталоге, определяемом при установке на компьютере системы программирования.
Директива #define. Эта директива предназначена для решения двух задач: сокращения длины кода и реализация макроопределений функций.
Первая задача решается следующим образом. Предположим, что по ходу программы часто встречается расчет некоторой формулы, например
...grad * (grad -1) * (grad -2)
Вместо того, чтобы это выражение записывать каждый раз можно определить замену
#define MGRAD grad * (grad -1) * (grad -2)
и в программе везде, где встретится выражение, использовать его обозначение MGRAD.
Следует отметить, что макроопределение нельзя использовать внутри строк, заключенных в кавычки.
Вторая задача - реализация макроопределений функций, обеспечивается следующей конструкцией:
# define <имя макроса> (<параметры>) <выражение>
# define Tenth (x) (x)/10
Разница между реализации обычной функции и макроса состоит в том, что в отличии от функции, тело макроса встраивается непосредственно в исходный код, увеличивая его размер, но ускоряя время исполнения.
Следует иметь в виду, что при описании тела макроса полезно обычно передаваемые ему аргументы заключать в скобки. Это делается с целью защиты от нарушений порядка исполнения операций. Например, если бы так не было сделано при определении макроса Tenth(), то его вызов с параметром-выражением давал бы ошибочный результат в случае
Tenth (arg1 + arg2) → arg1 + arg2/10 - ошибка!
При использовании функциональных макроопределений символ # используется для вывода параметра в виде строки - при компиляции параметр заключается в двойные кавычки
Предопределенные макросы
В C++ определено несколько макросов, предназначенных в основном для того, чтобы выдавать информацию о версии программы или месте возникновения ошибки.
_cplusplus — определен, если программа компилируется как файл C++. Многие компиляторы при обработке файла с расширением с считают, что программа написана на языке С. Использование этого макроса позволяет указать, что можно использовать возможности C++:
#ifdef _cpl uspl us
// Действия, специфические для C++
#endif
Применяется, если требуется переносить код из С в C++ и обратно.
__DATE__ — содержит строку с текущей датой в формате месяц день год,
__FILE__ — содержит строку с полным именем текущего файла.
__LINE__ — текущая строка исходного текста.
__TIME__ — текущее время, например:
printf(Rus(" Дата компиляции - %s \n"), __DATE__);
printf(Rus(" Ошибка в файле %s \n Время компиляции %s\n Строка %d\n"), __FILE__, __TIME__,__LINE__);
Тема 8. Язык программирования С/С++. Файлы и потоки
"Файлы и организация ввода-вывода"
Файлы и их представления. Файлы являются существенной частью современных компьютерных систем. Они используются для хранения произвольной (текстовой, графической, аудио, видео и др.) информации. Файл - это именованный раздел для сохранения информации, обычно раздел на диске. Например, относительно stdio.h можно думать как об имени файла, содержащем некоторую полезную информацию.
Язык С рассматривает файл как последовательность байтов, каждый из которых может быть прочитан индивидуально. Стандартами установлено два вида представления файлов: текстовое и двоичное. В текстовом представлении то, что видит программа может отличаться от того, что находится в файле. В случае использования двоичного представления, программа будет видеть точно ту последовательность байтов, которая записана в файле.
Библиотека языка С поддерживает три уровня ввода-вывода: потоковый ввод-вывод, ввод-вывод нижнего уровня и ввод-вывод для консоли и портов.
Стандартные файлы. Программы С автоматически открывают три файла. Они имеют названия стандартный ввод (stdin), стандартный вывод (stdout) и стандартный вывод ошибок (stderr). Стандартный ввод - это по умолчанию обычное устройство ввода в системе, как правило, клавиатура. Оба стандартных вывода по умолчанию также представляют собой обычное устройство вывода, как правило, монитор.
Стандартный ввод естественным образом обеспечивает ввод для программ. Этот файл, который читается с помощью функций getchar(), gets(), scanf(). Стандартный вывод - это место, куда направляется обычный вывод программы. При обработке вывода используются функции putchar(), puts(), printf(). Назначение стандартного вывода ошибок заключается в обеспечении логически понятного направления для посылки сообщений об ошибках.
Потоковый ввод-вывод. На уровне потокового ввода-вывода обмен данными производится побайтно. В случае файлов на диске используется поблочный обмен, при котором за одно обращение к устройству читается или записывается фиксированная порция данных. При вводе данные сначала помещаются в буфер операционной системы, а уж затем передаются программе пользователя. При выводе данные накапливаются в буфере, а уж затем за одно обращение записываются на диск. Буферы операционной системы реализуются в виде участков оперативной памяти. Поэтому пересылки между буферами ввода-вывода и выполняемой программой происходят достаточно быстро в отличие от реальных обменов с физическими устройствами.
Функции С, поддерживающие обмен данными с файлами на уровне потока, позволяют обрабатывать данные различных размеров и форматов, обеспечивая при этом буферизованный ввод-вывод. Таким образом, поток - это файл вместе с предоставляемыми средствами буферизации. При работе с потоками можно производить следующие действия:
- открывать и закрывать потоки (т.е. связывать указатели на потоки с конкретными файлами);
- вводить и выводить: символ, строку, форматированные данные, порцию данных произвольной длины;
- анализировать ошибки потокового ввода-вывода и условие достижения конца файла;
- управлять буферизацией потока и размером буфера;
- получать и устанавливать указатель текущей позиции в потоке.
Все функции, необходимые для работы с потоками, описаны в заголовочном файле stdio.h.
1. Открытие и закрытие потока. Прежде чем начать работу с потоком, его следует открыть. При этом поток связывается в программе со структурой предопределенного типа FILE. Определение этой структуры находится в заголовочном файле stdio.h. В структуре FILE содержатся компоненты, с помощью которых ведется работа с потоком. В результате открытия в программу возвращается указатель на эту структуру, который идентифицирует поток во всех последующих операциях.
Для открытия используется функция fopen():
#include <stdio.h>
...
FILE *fp;
...
fp = fopen(<имя_файла>,<режим_открытия>)
...
Здесь аргументы <имя_файла> и <режим_открытия> - указатели на массивы символов, содержащих соответственно имя файла, связанного с потоком, и строку режимов открытия.
Существует шесть основных режимов открытия:
| "w" (write) | новый текстовый файл открывается для записи. Если файл уже существовал, то его содержимое стирается и он создастся заново |
| "r" (read) | открывается только для чтения существующий текстовый файл |
| "a" (append) | текстовый файл открывается или создается для добавления в конец файла новой порции информации. |
| "w+" (write) | новый текстовый файл открывается для записи и последующей модификации. Если файл уже существует, то его содержание стирается. После открытия файла чтение и запись допустимы в любом месте, в том числе разрешена запись в конец файла. |
| "r+" (read) | существующий текстовый файл открывается как для чтения, так и для записи в любом месте файла; однако запись в конец, приводящая к увеличению размера файла недопустима. |
| "a+" (append) | текстовый файл открывается или создается с возможностью последующей модификации. В отличие от режима "w+" можно открыть существующий файл без уничтожения его содержимого; в отличие от режима "r+" можно записывать в конец файла, увеличивая его размеры. |
В случае использования двоичных файлов к строке режима открытия следует добавить символ "b" ("wb", "rb", "ab", "w+b", "r+b","a+b"). В этом случае все преобразования, связанные с обработкой концов строк, будут отсутствовать.
При открытии потока могут возникнуть ошибки, например, "указанный файл не найден", "диск заполнен", "диск защищен от записи" и ряд других. В случае ошибки функция fopen() возвращает указатель со значением NULL. Для вывода на экран сообщения об ошибке используется функция perror(), прототип которой описан в stdio.h:
void perror (const char *s);
Функция выводит строку символов, адресуемую указателем s, за которой размещается двоеточие, пробел и сообщение об ошибке. Содержимое и формат сообщения определяются используемой системой программирования. Текст сообщения об ошибке выбирается функцией на основании номера ошибки. Этот номер заносится в глобальную переменную с именем errno ( определенную в заголовочном файле errno.h) при реализации библиотечных функций ввода-вывода.
По завершению работы с файлом его рекомендуется закрыть при помощи функции
int fclose(<указатель_на_поток>);
Открытый файл можно открыть повторно (например, для изменения режима работы с ним) только после того, как файл будет закрыт с помощью функции fclose().
Для изменения прав доступа к файлу, также существует функция
FILE * freopen(<имя_файла>,<режим_открытия>,<указатель_на_поток>)
Типичный фрагмент программы, связанный с открытием файла выглядит следующим образом:
if ((fp = fopen("Exampl.txt","w")) == NULL)
{
perror("Error opening file Exampl.txt \n");
exit(0);
}
2. Работа с потоками. Для обслуживания потоков, определяющих файлы на дисках используются функции библиотеки языка С:
fgetc(), getc() - чтение одного символа из файла;
fputc(), putc() - запись одного символа в файл;
fprintf() - форматированный вывод в файл;
fscanf() - форматированный ввод из файла;
fgets() - чтение строки из файла;
fputs() - запись строки в файл;
fread() - чтение из файла порции данных;
fwrite()- запись в файл порции данных.
2.1. Посимвольный обмен. Прототипы функций:
int getc(FILE *stream);
int fgetc(FILE *stream);
int putc(int c, FILE *stream);
int fputc(int c, FILE *stream);
Пример.
...
int c;
FILE *in;
...
c = getc(in);
2.2. Cтроковый обмен. При работе с текстовыми файлами очень часто удобно работать с применением функций строкового обмена. Прототипы функций:
int fputs(const char *str, FILE *stream);
char * fgets(char *str, int n, FILE *stream);
Функция fputs записывает строку str в файл, заданный указателем stream на поток, и возвращает неотрицательное целое. При ошибках функция возвращает значение EOF. Символ конца строки - '\0' в файл не переносится, и символ '\n' в файл не записывается.
Функция fgets читает из определяемого указателем stream файла не более (n - 1) символов и записывает их в строку str. Функция прекращает чтение, как только прочтет (n - 1) символов или встретит символ новой строки '\n', который переносится в строку str. При ошибках или при достижении конца файла, при условии, что из файла не прочитан ни один символ, функция возвращает значение NULL. Следует особо отметить, что в отличие от функции строкового ввода из стандартного потока (gets()) данная функция не отбрасывает символ '\n'.
2.3. Форматированный обмен. Для работы с файлами определены функции
int fscanf(FILE *stream, const char *format, ...);
int fprintf(FILE *stream, const char *format, ...);
которые аналогичны рассмотренным нами функциям scanf() и printf(), реализующими обмен со стандартными потоками.
2.4. Порционный обмен. Данные могут быть записаны в файл и прочитаны из него блоками заданной длины. Для этого служат функции
size_t fread( void *buffer, size_t size, size_t count, FILE *stream );
size_t fwrite( const void *buffer, size_t size, size_t count, FILE *stream );
Функция fread() считывает из файла, определяемого указателем потока stream, в область памяти buffer count элементов размером по size байтов каждый. Функция возвращает число действительно прочитанных элементов. Если число элементов меньше заказанного (count), то это свидетельствует либо о достижении конца файла, либо об ошибке чтения. Чтобы проанализировать эту ситуацию можно воспользоваться функциями feof() или ferror(). Если файл открыт в текстовом режиме, то осуществляется замена символов конца строки ('\r\n' à '\n').
Функция fwrite() записывает count элементов, по size байтов каждый, из области памяти, задаваемой указателем buffer в поток stream. Функция возвращает число действительно записанных элементов. Если возвращаемое значение меньше заказанного (count) - то это свидетельствует о возникшей ошибке.
3. Позиционирование в потоке. Выполнение всех обменных операций с потоком связано с понятием текущей позиции в потоке. Начальная позиция чтения-записи установливается при открытии потока и может соответствовать либо первому байту файла (для режимов "write" или "read"), либо конечному (за последним байтом) (для режима "append"). При выполнении операций ввода-вывода текущая позиция в потоке меняется в соответствии с количеством прочитанных или записанных байтов.
Программисту даются средства для управления позиционированием в потоках, связанных с файлами (но не потоков, связанных с устройствами! Например, стандартных).
Функция fseek() позволяет установить указатель текущей позиции в потоке на нужный байт. Прототип этой функции:
int fseek( FILE *stream, long offset, int origin );
здесь offset - смещение, может быть как отрицательным так и положительным, т.е. возможно изменение текущей позиции по файлу и вперед, и назад;
origin - начало отсчета - задается при помощи одной из предопределенных констант:
SEEK_SET () - начало файла (значение 0);
SEEK_CUR () - текущая позиция (значение 1);
SEEK_END ()- конец файла (значение 2).
Примеры:
fseek(fp,0L,SEEK_SET); // Перемещение к началу файла (из любой позиции)
fseek(fp,0L,SEEK_END); // Перемещение к концу файла (из любой позиции)
fseek(fp,-2L,SEEK_СUR); // Возврат на два байта от текущей позиции
fseek(fp,12L,SEEK_СUR); // Пропуск 12 байтов от текущей позиции
Для получения значения указателя текущей позиции в потоке служит функция
long ftell( FILE *stream);
Пример:
long pos;
FILE * fp;
...
pos = ftell(fp); //Запомнить текущую позицию
...
fseek(fp, pos, SEEK_SET); // Восстановить запомненное значение
...
4. Контроль исполнения потоковых операций. Для проверки условия достижения конца файла служит функция
int feof( FILE *stream );
Функция возвращает не нулевое значение после первой операции чтения после достижения конца файла. Если конец файла не достигнут возвращается 0.
Для контроля ошибок обмена служит функция
int ferror( FILE *stream );
Если ошибок нет - функция возвращает значение 0, в противном случае - не 0. После возникновения ошибки индикатор ошибки, связанный с данным потоком, остается установленным до закрытия или изменения текущей позиции файла или выполнения функции очистки clearer().
Для сброса индикатора ошибки потока служит функция
void clearerr( FILE *stream );
:
Одновременно с необходимостью в динамическом распределении памяти, возникла необходимость в разработке способов управления этой памятью. Если до начала работы невозможно определить, сколько памяти необходимо под переменные, то ее выделяют по мере необходимости отдельными блоками, связанными друг с другом с помощью указателей. В итоге были разработаны три основные динамические структурыобъединенные под общим термином списки.
Список — это набор динамических элементов (чаще всего структурных переменных), связанных между собой каким-либо способом. Списки бывают линейными и кольцевыми, односвязными и двусвязными, и т.д.
Линейный односвязный список представляет собой самый обыкновенный список: каждый элемент связан только с одним элементом, который называется элементом, следующим за данным. Сам элемент по отношению к следующему называется предшествующим или предыдущим. Последний элемент списка содержит. признак конца списка.
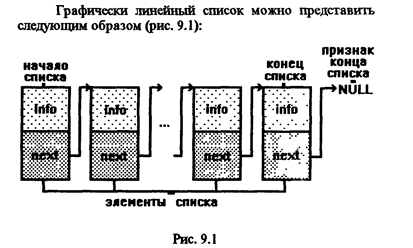
Элемент линейного списка как и любой динамической структуры данных представляет собой структуру, содержащую по крайней мере два поля: для хранения данных и для указателя. Поля данных могут быть любого типа: основного, составного или типа указатель. Описание простейшего элемента (компоненты, узла) выглядит следующим образом:
struct Node{
тип d; // тип данных информационного поля
Node *next;
};
Самьми распространенными случаями линейного односвязного списка являются очередь и стек.
Очередь — это список с таким способом связи между , элементами, при котором элементы добавляются строго в конец списка, а извлекаются строго из начала. Принцип организации списка можно описать так: "Первым пришел — первым ушел".
Ниже приведена программа, которая формирует очередь из пяти целых чисел и выводит ее на экран. Функция помещения в конец очереди называется add, а выборки — del. Указатель на начало очереди называется pbeg, указатель на конец — pend.
#include <iostream.h>
#include <conio.h>
struct Info
{int i;
};
struct FIFO{
Info d;
FIFO *next;
};
FIFO * first(Info d); //Формирование 1 элемента очереди
void add(FIFO **pend, Info d);
Info del(FIFO **pbeg);
//--.------...----------...--..-.....-----.-....--
int main(){
Info d;
d.i=1;
FIFO *pbeg = first (d);
FIFO *pend = pbeg;
for (int i = 2; i<6; i++)
{d.i=i;
add(&pend, d);
}
while (pbeg)
{d=del(&pbeg);
cout<<d.i<<' ';
}
getche();
return 0;
} //----..----------.---------.-..--------...-----..
// Начальное формирование очереди
FIFO *first(Info d)
{
FIFO *pv = new FIFO;
pv->d = d;
pv->next = 0;
return pv;
} //.-.---.----------------------------------------
// Добавление в конец
void add(FIFO **pend, Info d)
{
FIFO *pv = new FIFO;
pv->d = d;
pv->next = 0;
(*pend)->next = pv;
*pend = pv;
} //--.-------------------------.------------..---.-
// Выборка
Info del(FIFO **pbeg)
{
Info temp = (*pbeg)->d;
FIFO *pv = *pbeg;
*pbeg = (*pbeg)->next;
delete pv;
return temp;
}
Результат работы программы:
Стек — это список с таким способом связи между элементами, при котором элементы добавляются строго в начало списка и извлекаются тоже строго из начала списка. Принцип организации: "Первым пришел — последним ушел".
Ниже приведена программа, которая формирует стек из пяти целых чисел (1, 2, 3, 4, 5) и выводит его на экран Функция помещения в стек называется add, а выборки — del Указатель для работы со стеком (top) всегда ссылается на его вершину
#include <iostream.h>
#include <conio.h>
struct Info
{int i;
};
struct LIFO{
Info d;
LIFO *next;
};
LIFO * first(Info d); //Формирование 1 элемента очереди
void add(LIFO **top, Info d);
Info del(LIFO **top);
//--.------...----------...--..-.....-----.-....--
int main(){
Info d;
d.i=1;
LIFO *top = first (d);
for (int i = 2; i<6; i++)
{d.i=i;
add(&top, d);
}
while (top)
{d=del(&top);
cout<<d.i<<' ';
}
getche();
return 0;
} //----..----------.---------.-..--------...-----..
// Начальное формирование очереди
LIFO *first(Info d)
{
LIFO *pv = new LIFO;
pv->d = d;
pv->next = 0;
return pv;
} //.-.---.----------------------------------------
// Добавление в конец
void add(LIFO **top, Info d)
{
LIFO *pv = new LIFO;
pv->d = d;
pv->next = *top;
*top = pv;
} //--.-------------------------.------------..---.-
// Выборка
Info del(LIFO **top)
{
Info temp = (*top)->d;
LIFO *pv = *top;
*top = (*top)->next;
delete pv;
return temp;
}
Например, формула
(а+b/с)*(d-e*f)
постфиксную (ПОЛИЗ - польская инверсная запись): abc/+def*-*.
Рассмотрим пример использования динамических структур данных(стек). По введенной формуле необходимо построить cc ПОЛИЗ. (При записи формулы используются только операции +, —, *, / и буквы - операнды.)
#include <stdio.h>
#include <conio.h>
#include <string.h>
#include <windows.h>
#define ZNAK (c=='*' || c=='/')
char buf[256];
char *rus(char *t)
{CharToOem(t,buf);
return buf;
}
struct Info
{char i;
};
struct LIFO{
//char d;//
Info d;
LIFO *next;
};
LIFO * first(Info d); //Формирование 1 элемента очереди
void add(LIFO **top, Info d);
Info del(LIFO **top);
//--.------...----------...--..-.....-----.-....--
void main()
{ char s[50], sl[80], c;
Info d;
int er, i, l, k=0;
LIFO *st=NULL;
puts(rus("Введите инфиксную запись формулы, операндами в которой"));
puts(rus("являются буквы, а знаками - символы +, -, *, /"));
gets(s) ;
l=strlen(s);
d.i='(';
st=first(d); // заносим '(o в стек и
for(i=0; i<l; i++) // просматриваем выражение слева направо
if(isalpha(s[i]))
sl[k++]=s[i]; // операнд заносим т выходной массив
else if(s[i] == '('){d.i='('; add(&st, d);} // '(' кладется а стек
else if(s[i]==')')
while((c=del(&st).i)!= '(')
sl[k++]=c;// извлекаем из стека все до ближай-
// шей'(', которую тоже удаляем из стека
else switch(s[i]) /* : когда в записи формулы встречается знак операции - не скобка и не операнд - то с вершины стека из-извлекаются (до ближайшей скобки, которая сохраняется в стеке) знаки операций, старшинство которых больше или равно старшинству данной операции, и они заносятся в выходной массив, после чего рассматриваемый знак заносится в стек.*/
{
case '+' : case '-':
while((st->d).i!='(')
sl[k++]=del(&st).i;
d.i=s[i];
add(&st, d); break;
case '*':case '/':
while((st->d).i!='(')
{ if(!ZNAK)break;
sl[k++]=del(&st).i; }
d.i=s[i];
add(&st, d); break;
default:printf(rus("Неверный символ s[%d]: %с !"), i+1, s[i]);
exit(1);}
// в заключение выполняются такие же действия, как если бы встре-
// тилась закрывающая скобка
while((c=del(&st).i) !='(') sl[k++]=c;
sl[k]='\0';
puts(rus("\n\t\tПОЛИЗ:\n\n\t")) ; puts(sl) ;
}
// Начальное формирование очереди
LIFO *first(Info d)
{LIFO *pv = new LIFO;
pv->d = d;
pv->next = 0;
return pv;
} //.-.---.----------------------------------------
// Добавление в конец
void add(LIFO **top, Info d)
{LIFO *pv = new LIFO;
pv->d = d;
pv->next = *top;
*top = pv;
} //--.-------------------------.------------..---.-
// Выборка
Info del(LIFO **top)
{Info temp = (*top)->d;
LIFO *pv = *top;
*top = (*top)->next;
delete pv;
return temp;}
Кольцевой список отличается от линейного тем, что в односвязном варианте элементом, следующим за последним, считается первый элемент списка; в двусвязном варианте элементом, следующим за последним, считается первый, а элементом, предшествующим первому, считается последний. Графически кольцевой список можно представить следующим образом (рис. 9.2):
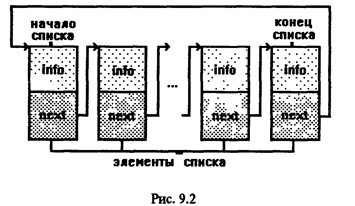
Линейный двусвязный список отличается от односвязного только тем, что в данном случае элемент связан не только со следующим элементом, но и с предыдущим. И первый, и последний элементы списка содержат признак конца списка. Извлечение и добавление элементов может происходить в любом месте списка.
Описание простейшего элемента:
struct Node{
тип d; // тип данных информационного поля
Node *next;
Node *prev;
};
Над списками можно выполнять следующие операции:
- начальное формирование списка (создание первого элемента);
- добавление элемента в конец списка;
- чтение элемента с заданным ключом;
- вставка элемента в заданное место списка (до или после элемента с заданным ключом);
- удаление элемента с заданным ключом;
- упорядочивание списка по ключу.
Программа, которая формирует список из фамилий и например группы крови(целое число 1 2 3 или 4), добавляет запись в список, удаляет запись из списка и выводит список на экран. Указатель на начало списка обозначен рbеg, на конец списка — pend, вспомогательные указатели — pv и pkey
Указатели, которые могут измениться (например, при удалении из списка последнего элемента указатель на конец списка требуется скорректировать), передаются по адресу
#include <iostream.h>
#include <conio.h>
#include<string.h>
struct info
{char fam[20];
int gr;
};
struct LIST
{
info d;
LIST *next;
LIST *prev;
} ;
// ... - ... ---.---- .---- ----- -..--...-.--...-
void vvod(info &d);
LIST * first(info d); //// Формирование первого элемента
void add(LIST **pend, info d); // Добавление в конец списка
LIST * find(LIST * const pbeg, char *key); // Поиск элемента по ключу
bool remove(LIST **pbeg, LIST **pend, char *key); // Удаление элемента
LIST * insert(LIST * const pbeg, LIST **pend, char *key, info d); // Вставка элемента
void sort(LIST **pbeg, LIST **pend);
void vyvod(LIST *pbeg);
//-. ... -. .--..--.-.---..----.------. -----.--
int main()
{char fam[20];
info d;
int i;
vvod(d);
LIST *pbeg = first(d); // Формирование первого элемента списка
LIST *pend = pbeg ; // Список заканчивается едва начавшись
// Добавление в конец списка четырех элементов 2 3 4 и 5
for (i = 0 ;i<3;i++)
{
vvod(d);
add(&pend,d);
}
// Вставка элемента 200 после элемента 2
vyvod(pbeg);
cout <<" posle Fam ";
cin>>fam;
vvod(d);
insert(pbeg ,&pend, fam, d);
vyvod(pbeg);
// Удаление элемента 5
cout <<" Fam dla delet ";
cin>>fam;
if(!remove (&pbeg, &pend ,fam)) cout<< "не найден" ;
vyvod(pbeg);
cout<<"do sort"<<endl;
for(i=0;i<2;i++)
{vyvod(pbeg);
if(!i){ cout<<"posle sort"<<endl;
sort(&pbeg,&pend);}}
cout<<"fam for find\n";
cin>>fam;
LIST *pv=pbeg;
do{
if(pv=find(pv,fam))
{cout << pv->d.fam<<' '<<pv->d.gr<<endl;
pv=pv->next;}
}while(pv);
return 0;
}
// ... -- ---. ---- -..-..-- ---.. --..---... --
void vvod(info &d)
{cout <<"Fam"<<endl;
cin>>d.fam;
cout<<"G r"<<endl;
cin>>d.gr;
}
void vyvod(LIST *pbeg)
{LIST *pv = pbeg;
while (pv){ // вывод списка на экран
cout << pv->d.fam<<' '<<pv->d.gr<<endl;
pv = pv->next;
}}
// Формирование первого элемента
LIST * first(info d)
{
LIST *pv= new LIST;
pv->d = d ;
pv->next = 0;
pv->prev = 0;
return pv;
}
//..-...-.....-...------ ---- --- --..----. --
// Добавление в конец списка
void add(LIST **pend, info d)
{
LIST *pv = new LIST;
pv->d = d;
pv->next= 0;
pv->prev = *pend;
(*pend)->next = pv;
*pend = pv;
} //-...----...----....--.---..-...-..--.......-----
// Поиск элемента по ключу
LIST * find(LIST * const pbeg, char *key)
{ LIST *pv = pbeg;
while (pv){
if(!strcmp(pv->d.fam,key))break;
pv = pv->next;
} return pv;
}
//..-----.-.....---..--.....--....------.-....----
// Удаление элемента
bool remove(LIST **pbeg, LIST **pend, char *key){
if(LIST *pkey = find(*pbeg, key)){ // 1
if (pkey == *pbeg)
{ // 2
*pbeg = (*pbeg)->next;
(*pbeg)->prev =0;
}
else if (pkey == *pend)
{ // 3
*pend = (*pend)->prev;
(*pend)->next =0;
}
else
{ // 4
(pkey->prev)->next = pkey->next;
(pkey->next)->prev = pkey->prev;
}
delete pkey;
return true; //5
}
return false; // 6
}
//..-----...------....------.......--I--......---.
// Вставка элемента
LIST * insert(LIST * const pbeg, LIST **pend, char *key, info d)
{ if(LIST *pkey = find(pbeg, key)){
LIST *pv = new LIST;
pv->d = d;
// 1 - установление связи нового узла с последующим:
pv->next = pkey->next;
// 2 - установление связи нового узла с предыдущим:
pv->prev = pkey;
// 3 - установление связи предыдущего узла с новым-
pkey->next = pv;
// 4 - установление связи последующего узла с новым
if( pkey!= *pend) (pv->next)->prev = pv;
// Обновление указателя на конец списка
// если узел вставляется в конец
else *pend = pv;
return pv;
} return 0;
}
//---------------
void sort(LIST **pbeg, LIST **pend)
{bool f;
LIST *pv,*pt,*pk=*pbeg;
while(pk)
{ pv=new LIST;
pv->d =pk->d;
pt = *pbeg;
f=true;
while (pt!=pk){ // просмотр списка
if ((pv->d).gr < (pt->d).gr ){ // занести перед текущим элементом (pt)
f=false;
pv->next = pt;
if (pt == *pbeg){ // в начало списка
pv->prev = 0; *pbeg = pv;}
else{ // в середину списка
(pt->prev)->next = pv;
pv->prev = pt->prev;}
pt->prev = pv;
//запоминаем указатель на следующий элемент
pt=pk->next;
//удаляем элемент pk
if(pk==*pend)//если он стоит в конце
{(pk->prev)->next=0;
*pend=pk->prev;}
else //если он стоит в середине
{(pk->prev)->next= pk->next;
(pk->next)->prev=pk->prev;
}
delete pk;
pk=pt;
break;
} pt = pt->next;
}
if(f) pk=pk->next;
}
}
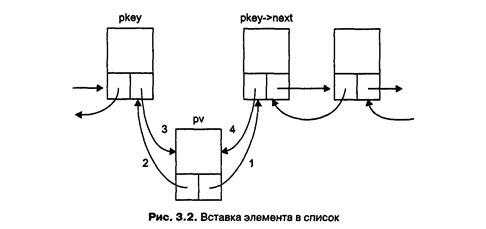
Рассмотрим подробнее функцию удаления элемента из списка remove Ее параметрами являются указатели на начало и конец списка и ключ элемента, подлежащего удалению В строке 1 выделяется память под локальный указатель pkey, которому присваивается результат выполнения функции нахождения элемента по ключу find Эта функция возвращает указатель на элемент в случае успешного поиска и 0, если элемента с таким ключом в списке нет. Если pkey получает ненулевое значение, условие в операторе i f становится истинным (элемент существует), и управление передается оператору 2, если нет — выполняется возврат из функции со значением false (оператор 6).
Удаление из списка происходит по-разному в зависимости от того, находится элемент в начале списка, в середине или в конце В операторе 2 проверяется, находится ли удаляемый элемент в начале списка — в этом случае следует скорректировать указатель pbeg на начало списка так, чтобы он указывал на следующий элемент в списке, адрес которого находится в поле next первого элемента Новый начальный элемент списка должен иметь в своем поле указателя на предыдущий элемент значение О
Если удаляемый элемент находится в конце списка (оператор 3), требуется сместить указатель pend конца списка на предыдущий элемент, адрес которого можно получить из поля prev последнего элемента Кроме того, нужно обнулить для нового последнего элемента указатель на следующий элемент Если удаление происходит из середины списка, то единственное, что надо сделать, — обеспечить двустороннюю связь предыдущего и последующего элементов После корректировки указателей память из-под элемента освобождается, и функция возвращает значение true
Работа функции вставки элемента в список проиллюстрирована на рис 3 2 Номера около стрелок соответствуют номерам операторов в комментариях.
Сортировка связанного списка заключается в изменении связей между элементами Алгоритм состоит в том, что исходный список просматривается, и каждый элемент вставляется в новый список на место, определяемое значением его ключа
Ниже приведена функция формирована упорядоченного списка (предполагается, что первый элемент существует):
void add_sort(Node **pbeg, Node **pend, int d)
{ Node *pv = new Node; // добавляемый элемент
pv->d = d;
Node * pt = *pbeg;
while (pt){ // просмотр списка
1f (d < pt->d){ // занести перед текущим элементом (pt)
pv->next = pt;
if (pt == *pbeg){ // в начало списка
pv->prev = О; *pbeg = pv;}
e1se{ // в середину списка
(pt->prev)->next = pv;
pv->prev = pt->prev;}
pt->prev = pv:
return;
} pt = pt->next:
}
pv->next = 0; // в конец списка
pv->prev = *pend:
(*pend)->next = pv;
*pend = pv;
}
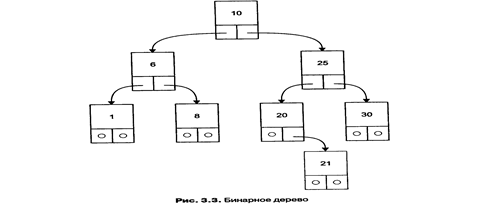
Бинарное дерево — это динамическая структура данных, состоящая из узлов, каждый из которых содержит, кроме данных, не более двух ссылок на различные бинарные деревья. На каждый узел имеется ровно одна ссылка. Начальный узел называется корнем дерева.
Приведем пример бинарного дерева . Узел, не имеющий поддеревьев, называется листом. Исходящие узлы называются предками, входящие — потомками. Высота дерева определяется количеством уровней, на которых располагаются его узлы.
Если дерево организовано таким образом, что для каждого узла все ключи его левого поддерева меньше ключа этого узла, а все ключи его правого поддерева — больше, оно называется деревом поиска. Одинаковые ключи не допускаются. В дереве поиска можно найти элемент по ключу, двигаясь от корня и переходя на левое или правое поддерево в зависимости от значения ключа в каждом узле. Такой поиск гораздо эффективнее поиска по списку, поскольку время поиска определяется высотой дерева, а она пропорциональна двоичному логарифму количества узлов.
Рассмотрим работу с бинарным деревом (в котором у каждого узла может быть только два приемника - левый и правый сын). Необходимо уметь:
построить дерево;
выполнить поиск элемента с указанным значением в узле;
удалить заданный элемент;
обойти все элементы дерева (например, чтобы над каждым из них провести некоторую операцию).
Обычно бинарное дерево строится сразу упорядоченным, т.е. узел левого сына имеет значение меньшее, чем значение родителя, а узел правого сына - большее. Например, если приходят числа 17, 18, 6, 5, 9, 23, 12, 7, 8, то построенное по ним дерево будет выглядеть так (рис. 15.6).
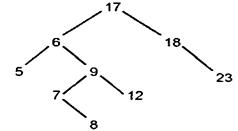
Для того, чтобы вставить новый элемент в дерево, надо найти для него место. Для этого, начиная с корня, будем сравнивать значения узлов (Y) со значением нового элемента (NEW). Если NEW < Y, то пойдем по левой ветви; в противном случае - по правой. Когда дойдем до узла, из которого не выходит нужная ветвь для дальнейшего поиска, это означает, что место под новый элемент найдено.
Путь поиска места для числа 11 покажем жирной линией.
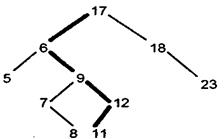
При удалении узла из дерева возможны три ситуации:
а) исключаемый узел - лист (в этом случае надо просто удалить ссылку на данный узел);
б) из исключаемого узла выходит только одна ветвь;
в) из исключаемого узла выходят две ветви (в таком случае на место удаляемого узла надо поставить либо самый правый узел левой ветви, либо самый левый узел правой ветви для сохранения упорядоченности дерева).
Например, построенное ранее дерево после удаления узла 6 может стать таким (рис. 15.8).
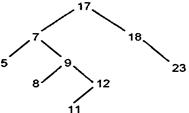
Рассмотрим задачу обхода дерева. Существуют три способа обхода, которые естественно следуют из самой структуры дерева.
1) Обход слева направо: A, R, В (сначала посещаем левое поддерево, затем - корень и, наконец, правое поддерево).(5 6 7 8 9 11 12 17 18 23)
2) Обход сверху вниз: R, А, В (посещаем корень до поддеревьев).(17 6 5 9 7 8 12 11 18 23)
3) Обход снизу вверх: А, В, R (посещаем корень после поддеревьев). (5 8 7 11 12 9 6 17 23 18 )
Интересно проследить результаты этих трех обходов на примере записи формул в виде дерева.
Например, формула
(а+b/с)*(d-e*f)
будет представлена след. образом
(дерево формируется по принципу: операция - узел, операнды - поддеревья).
Обход 1 даст обычную инфиксную запись выражения (правда, без скобок).
Обход 2 - префиксную запись *+а/bс-d*ef
Обход 3 - постфиксную (ПОЛИЗ - польская инверсная запись): abc/+def*-*.
В качестве примера работы с древовидной структурой данных рассмотрим решение следующей задачи.
Вводятся слова; необходимо распечатать их в алфавитном порядке с указанием количества повторений каждого слова.
В программе будет использована функция der(), которая строит дерево слов, а также рекурсивная • функция для печати дерева print_der(), в которой реализован первый способ обхода дерева.
#include<stdio.h>
#include<conio.h>
#include<string.h>
#include<windows.h>
char buf[256];
char *rus(char *text)
{CharToOem(text,buf);
return buf;}
struct info
{ char *w;
int c;
};
struct TREE
{ info d;
TREE *l;
TREE *r;
};
TREE *first(char *word);//фармирование первого элемента дерева
TREE *der(TREE *kr, char *word);//добавление элемента
void print_der(TREE *kr);//просмотр элементов дерева
void main()
{ int i=0;
char word[40][20],ch;
puts(rus("Введите фамилии, пока не нажата клава Esc"));
scanf ("%s",word[i]);
TREE *kr=first(word[i]);
do
{
scanf("%s", word[++i]);
der(kr,word[i]);
printf("");}
while((ch=getch())!=27);
print_der(kr) ;
}
TREE *first(char *word)
{TREE *pv=new TREE;
(pv->d).w=word;
(pv->d).c=1;
pv->l=0;
pv->r=0;
return pv;}
TREE *der(TREE *kr, char *word)
{TREE *pv=kr,*prev;
int flag=0;
int sr;
while(pv&&!flag)
{prev=pv;
if((sr=strcmp(word, (pv->d).w))==0) {((pv->d).c)++;flag=1;}
else if(sr<0) pv= pv->l;
else pv= pv->r;}
if (flag) return pv;
// Создание нового узла
TREE *pnew=new TREE;
(pnew->d).w=word;
(pnew->d).c=1;
pnew->l=0;
pnew->r=0;
if(sr<0) prev->l= pnew;
else prev->r=pnew;
return pnew;
}
void print_der(TREE *kr)
{
if(kr)
{ print_der(kr->l);
printf(rus("Фамилия - %-20s \tКол-во повторов.- %d\n"), (kr->d).w, (kr->d).c);
print_der (kr->r) ;
}
}
Дата добавления: 2017-01-13; просмотров: 1448;