Вычисление ошибки репрезентативности для собственно случайной выборки.
Пусть нам необходимо оценить средний возраст некоторой группы людей по ограниченному числу наблюдений n. Оценкой среднего значения непрерывной случайной величины является математическое ожидание:
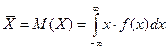 .
.
Естественной оценкой математического ожидания является среднее арифметическое:
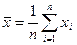 .
.
От оценки необходимо потребовать следующие свойства:
1. состоятельность – оценка называется состоятельное, если при увеличении числа опытов оценка сходится по вероятности с искомым параметром,
2. несмещенность – оценка называется несмещенной, если выполнялось условие
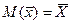 ,
,
3. эффективность – оценка называется эффективной, если ее дисперсия минимальна по сравнению с другими.
Среднее арифметическое обладает этими свойствами[3].
Оценка параметра является функцией от случайных величин 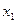 ,
, 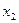 , … ,
, … , 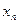 , поэтому сама является случайной величиной. Другими словами, мы можем сделать множество выборок, для каждой из которых значение оценки будет различно. По закону больший чисел распределение оценки является нормальным с математическим ожиданием
, поэтому сама является случайной величиной. Другими словами, мы можем сделать множество выборок, для каждой из которых значение оценки будет различно. По закону больший чисел распределение оценки является нормальным с математическим ожиданием
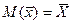
и дисперсией
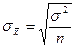 [4],
[4],
где 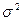 - генеральная дисперсия.
- генеральная дисперсия.
Тогда можно рассчитать вероятность того, что 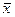 попадет в интервал
попадет в интервал 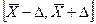 . Поскольку нам неизвестна величина
. Поскольку нам неизвестна величина 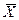 , то мы будем говорить о вероятности, с которой интервал
, то мы будем говорить о вероятности, с которой интервал 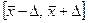 накроет . Эта которая равна площади под графиком функции распределения случайной величины (см. рис. 2):
накроет . Эта которая равна площади под графиком функции распределения случайной величины (см. рис. 2):
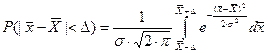 .
.
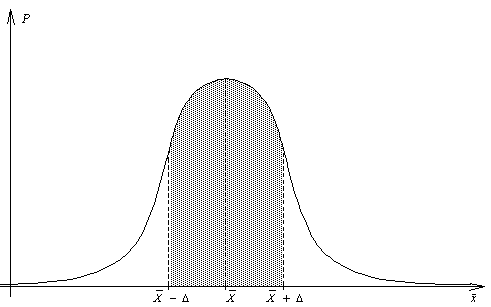
Рисунок 2. Распределение выборочной оценки среднего.
Приведем это распределение к стандартному виду.
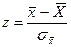
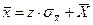
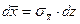
Произведем замену переменной:
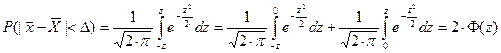 .
.
Справа получили функцию Лапласа, которая табулирована (см. Приложение):
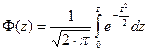 .
.
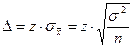
Нам не известно значение 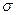 , поэтому заменим его на
, поэтому заменим его на 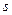 . Но в этом случае нужно использовать не нормальное распределение, а распределение Стьюдента.
. Но в этом случае нужно использовать не нормальное распределение, а распределение Стьюдента.
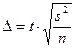 ,
,
где 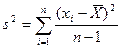
При больших объемах выборки вид распределения Стьюдента приближается к виду нормального распределения, поэтому для больших выборок также можно использовать функцию Лапласа.
Для повторной выборки
(1).
Для бесповторной выборки необходимо внести поправку на конечность ГС
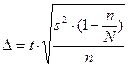 (2).
(2).
Для большой ГС (объем ВС составляет менее 5% от ГС) поправкой на конечность совокупности можно пренебречь.
Про коэффициент доверия 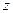 следует сказать отдельно. Этот коэффициент исследователь выбирает сам. Чем меньше , тем меньше доверительный интервал, но тем меньше и вероятность того, что оценка не выйдет за пределы доверительного интервала.
следует сказать отдельно. Этот коэффициент исследователь выбирает сам. Чем меньше , тем меньше доверительный интервал, но тем меньше и вероятность того, что оценка не выйдет за пределы доверительного интервала.
Пример 1. Пусть была произведена выборка 1600 человек. Средний возраст по выборке – 30 лет, среднеквадратическое отклонение – 10 лет. Необходимо найти доверительный интервал.
Прежде всего, необходимо задать надежность оценки. Возьмем 95% надежность. Поскольку выборка большая, воспользуемся таблицей значений функции Лапласа и найдем коэффициент доверия - 1,96.
Тогда
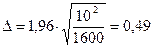 .
.
С вероятностью 95% истинное средний возраст по ГС находится в интервале от 29,51 лет до 30,49 лет.
Для биномиального распределения
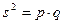 ,
,
где 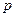 – доля признака,
– доля признака, 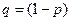 .
.
Тогда для повторной выборки из (1)
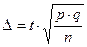 (3),
(3),
для бесповторной выборки из (2)
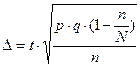 (4).
(4).
Пример 2.Из 200 опрошенных 55% - женщины. Действуем аналогично примеру 1. Выборку также можно считать большой. Тогда =1,96 для 95% надежности.
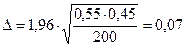 .
.
С вероятностью 95% доля женщин в ГС находится в интервале от 48% до 62%.
Таблица 1.
Формулы ошибки репрезентативности для собственно случайного отбора.[3, 16]
| Предмет изучения. | Повторный отбор. | Бесповторный отбор. |
| Среднее значение признака. | 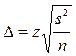
| 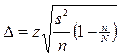
|
| Доля признака. | 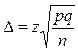
| 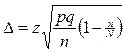
|
Где:
z – коэффициент доверия,
n – объем выборки,
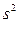 - выборочная дисперсия,
- выборочная дисперсия,
N – объем генеральной совокупности,
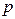 - доля признака в выборочной совокупности.
- доля признака в выборочной совокупности.
Дата добавления: 2016-03-05; просмотров: 1620;