Статистическое группирование
По аналогии со статистической формулировкой задачи распознавания образов при статистическом группировании наблюдаемое множество данных X представляет собой n экспериментальных точек с неизвестной принадлежностью к классам. На первом этапе процесса наблюдения с каждым i-мклассом множества из k классов связывалась известная функция плотности вероятности fi с неизвестными параметрами qi. Например, если функция fi является нормальным распределением, то множество параметров 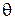 содержит всего два параметра: среднее значение и дисперсию для класса i.На втором этапе выбор точки xдляi-го классаопределяется плотностью вероятностей fi (x/q).
содержит всего два параметра: среднее значение и дисперсию для класса i.На втором этапе выбор точки xдляi-го классаопределяется плотностью вероятностей fi (x/q).
Задача группирования состоит в выборе значений для множеств
P = {pi} и q = {qi}, которые соответствуют данным множества X наилучшим образом. Поскольку с вычислительной точки зрения задача статистической оценки является достаточно сложной, дальнейшее рассмотрение будет ограничено широко используемым примером вычислений, известным как минимизация по критерию хи-квадрат.
Обозначим через 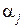 число точек из множества X, попадающих в область
число точек из множества X, попадающих в область 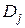 пространства описаний D, состоящего из r попарно непересекающихся областей
пространства описаний D, состоящего из r попарно непересекающихся областей 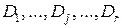 . При любых фиксированных значениях P и q ожидаемое число наблюдений в области с учетом попадания точек в нее из
. При любых фиксированных значениях P и q ожидаемое число наблюдений в области с учетом попадания точек в нее из 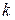 областей различных классов равно
областей различных классов равно
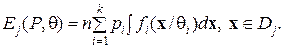 (49)
(49)
Решение задачи состоит в определении значений P и q, которые минимизируют статистику хи-квадрат, равную
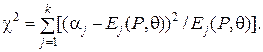 (50)
(50)
В некоторых задачах надо найти и значение k. Конкретный способ решения зависит от вида функций плотности вероятностей {fi}. Если не удается получить оценку в замкнутой форме, пробуют каким-то систематическим образом определить различные численные значения параметров. Когда исчерпывающее перечисление параметров также неосуществимо, может оказаться достаточно точной для практических целей процедура графической оценки, выполняемая с помощью ЭВМ.
6.2.2. Метод «k-средних»
Этот метод служит примером прямого адаптивного группирования для независимых классов. При его реализации, как и в задаче распознавания образов, экспериментальные точки упорядочены в последовательность Sx наблюдений x(1), …, x(n)  в m-мерном пространстве описаний. Предполагается, что число классов объектов ровно k, каждый класс имеет среднюю точку
в m-мерном пространстве описаний. Предполагается, что число классов объектов ровно k, каждый класс имеет среднюю точку 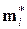 , а текущее среднее значение корректируется по мере накопления новых данных.
, а текущее среднее значение корректируется по мере накопления новых данных.
Алгоритм, оценивающий по последовательности Sx, выглядит следующим образом:
1) Вычислить множество 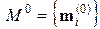 начальных оценок, относя к каждому классу одну из первых k точек из последовательности Sx.
начальных оценок, относя к каждому классу одну из первых k точек из последовательности Sx.
В результате получим
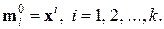
2) Отнести предъявляемую точку 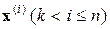 к группе точек j, для которой расстояние
к группе точек j, для которой расстояние 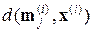 минимально. Неопределенности нивелируются в пользу группы с меньшим индексом.
минимально. Неопределенности нивелируются в пользу группы с меньшим индексом.
3) Найти новые оценки средних точек 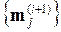 для каждой группы:
для каждой группы:
если точка  к группе j не отнесена, оценка
к группе j не отнесена, оценка 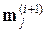 оставляется без изменения; если отнесена к j, то на основе текущего состава группы устанавливается новая оценка средней точки. Пусть
оставляется без изменения; если отнесена к j, то на основе текущего состава группы устанавливается новая оценка средней точки. Пусть 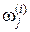 – число экспериментальных точек в группе в момент, когда предъявляется i-я экспериментальная точка. Тогда
– число экспериментальных точек в группе в момент, когда предъявляется i-я экспериментальная точка. Тогда
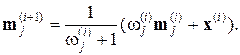
Математически доказано, что если последовательность Sx построена из выборок, относящихся к k различным распределениям вероятностей, то k оценок 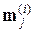 будут асимптотически сходиться к средним значениям этих распределений.
будут асимптотически сходиться к средним значениям этих распределений.
Дата добавления: 2016-01-20; просмотров: 634;