Общие сведения и определения. В разделе 10 были рассмотрены алгоритмы поиска элемента в таблице
В разделе 10 были рассмотрены алгоритмы поиска элемента в таблице. Эти алгоритмы предполагают, что прежде, чем найти требуемую запись, необходимо организовать просмотр и сравнение с аргументом поиска некоторого количества ключей. Организация таблицы (последовательная, индексно-последовательная, в виде бинарного дерева и т. д.) и порядок, в котором вставляются ключи, определяют то число ключей, которое должно быть проверено до получения нужного ключа. Очевидно, что эффективными методами поиска являются те методы, которые минимизируют число этих проверок. Было показано, что наиболее эффективным методом поиска является бинарный поиск, требующий в наихудшем случае выполнения числа сравнений, приблизительно равного log2N. Однако бинарный поиск не может быть применен для таблиц с произвольным расположением элементов: элементы должны быть расположены в отсортированном порядке.
В идеале мы бы хотели иметь такую организацию таблицы, при которой не было бы ненужных сравнений. Посмотрим, возможна ли такая организация. Если каждый ключ должен быть извлечен за один доступ, то положение записи внутри такой таблицы может зависеть только от данного ключа. Оно не может зависеть от расположения других ключей, как это имеет место в дереве. Наиболее эффективным способом организации такой таблицы является одномерный массив, т. е. доступ к каждой записи обеспечивается с помощью ее уникального целочисленного индекса, который определяет позицию элемента в общей таблице. Если ключи записей являются целыми числами, то сами ключи могут использоваться как индексы в массиве. Рассмотрим пример такой системы.
Предположим, что некоторая фирма-производитель имеет таблицу с перечнем производимых изделий, состоящую из 1000 наименований изделий, причем каждое изделие имеет уникальный номенклатурный номер из трех цифр. Тогда обычным способом хранения этой таблицы является описание некоторого массива:
a[0], a[1], a[2], …, a[HighIndex].
Допустим для определенности, что массив a описывается нотациями (11.1) и (11.2). Общее число элементов по‑прежнему обозначаем N, тогда HighIndex = N - 1.
В нашем случае можно задать N = 1000, и если номера изделий, составляющие содержимое поля Key, являются ключами, то целесообразно определить, что эти номера используются как индексы в данном массиве. Тогда запись с ключом, например, 67 при вставке размещается в элементе a[67]. В такой таблице легко организовать поиск: элемент, соответствующий аргументу поиска ArgSearch, - это элемент a[ArgSearch]. Мы видим, что при такой организации таблицы при поиске не нужно производить ни одного сравнения.
Та же самая структура может использоваться для организации файла производимых изделий, даже если на складах фирмы накопилось до, например, 200 наименований изделий (при условии что ключи по-прежнему состоят из трех цифр). Хотя многие ячейки в массиве a тогда бы соответствовали несуществующим ключам, эти потери компенсируются преимуществом прямого доступа к записи с информацией о каждом из существующих изделий.
К сожалению, такая система не всегда имеет практический смысл. Например, предположим, что фирма имеет некоторую таблицу производимых изделий, состоящую из более 1000 пунктов, и ключ каждой записи является номером изделия из семи цифр. Для применения прямой индексации с использованием полного семизначного ключа потребовался бы массив из 10000000 (10 млн.) элементов. Ясно, что это привело бы к потере неприемлемо большого пространства памяти, поскольку совершенно невероятно, что какая-либо фирма может иметь больше чем несколько тысяч наименований изделий. Поэтому необходим некоторый метод преобразования ключа в какое-либо целое число внутри ограниченного диапазона. В идеале в одно и то же число не должны преобразовываться два различных ключа. К сожалению, такого идеального метода не существует. Попытаемся разработать методы, которые приближаются к идеальным, и определить, какие действия надо предпринять, когда идеальный случай не достигается.
Рассмотрим опять пример с таблицей наименований изделий фирмы, в которой каждая запись задается ключом из семизначного номера изделия. Предположим, что фирма имеет не более 1000 наименований изделий и что для каждого изделия используется только одна запись. Тогда для хранения всего файла будет достаточно массива из 1000 элементов. Этот массив индексируется целым числом в диапазоне от 0 до 999 включительно. В качестве индекса записи об изделии в этом массиве используются три последние цифры номера изделия. Это показано на рисунке 12.1. Отметим, что два ключа, которые близки друг к другу как числа (такие как 4618396 и 4618996), могут располагаться дальше друг от друга в этой таблице, чем два ключа, которые значительно различаются как числа (такие как 0000991 и 9846995). Это происходит из-за того, что для определения позиции записи используются только три последние цифры ключа.
Функция, которая трансформирует ключ в некоторый индекс в таблице, называетсяфункцией хеширования (hash function). Другие названия функции хеширования: хеш-функция, функция перемешивания. Если h является некоторой хеш-функцией, а Кey некоторый ключ, то h(Кey) называетсязначением хеш-функции от ключа Кey и является индексом, по которому должна быть помещена запись с ключом Кey. Преобразование ключа элемента в значение индекса называется хешированием (hashing). Массив, используемый для хранения элементов, в котором индексы определяются с помощью хеширования ключей, называется хеш-таблицей (hash table).
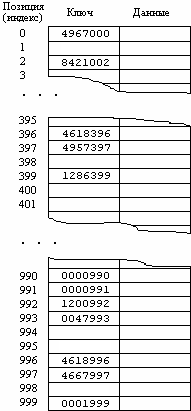
Рисунок 12.1 - Размещение записей в таблице, когда
позиция записи определяется по трем последним цифрам ключа
Если мы обозначим остаток от деления X на Y как X Mod Y, то хеш‑функция для вышеприведенного примера есть
h(Кey) = КeyMod 1000. (12.1)
Значения, которые выдает функция h, должны покрывать все множество индексов в таблице. Например, функция КeyMod 1000 может дать любое целое число в диапазоне от 0 до 999 в зависимости от значения Кey. Как мы вскоре увидим, хорошей идеей является таблица, размер которой немного больше, чем число вставляемых записей. Это иллюстрируется на рисунке 12.1, где несколько позиций таблицы не используются.
Дата добавления: 2015-08-21; просмотров: 806;